Présentation d'outils d'extraction de données
| Site: | Callisto Formation |
| Cours: | Corpus et données : comment utiliser les données ouvertes de Wikimedia |
| Livre: | Présentation d'outils d'extraction de données |
| Imprimé par: | Visiteur anonyme |
| Date: | jeudi 9 juillet 2026, 12:24 |
1. Introduction
Des API aux requêtes SQL et SPARQL en passant par des bibliothèques R et Python, les techniques ne manquent pas pour consulter, traiter et récupérer les données des wikis de Wikimedia Foundation. Dans ce chapitre, nous passerons en revue quelques techniques basiques, avant de présenter les outils pour effectuer des requêtes SQL et SPARQL, plusieurs API, et enfin quelques ressources pour Python et R.

2. Techniques basiques
Dans la suite de ce chapitre, nous présentons quelques méthodes basiques d'extraction de contenu.
2.1. Copier-coller
Exemples
- Présidents de la Société préhistorique française
- Climat à Bordeaux
- Monuments aux morts au cimetière du Père-Lachaise
- Classement du championnat de France de football masculin 2022-2023
- Liste des personnalités féminines historiques représentées dans la statuaire publique parisienne
- Liste des arbres les plus anciens
- Liste des pays par ville la plus haute
Mode d'emploi
Pour récupérer les données, il faut lancer le mode édition en cliquant le bouton «Modifier » puis sélectionner le contenu d’un tableau afin de le copier-coller dans un tableur. 2.2. Moteur de recherche
Le moteur de recherche des wikis de Wikimedia Foundation est Elasticsearch via une extension MediaWiki appelée CirrusSearch. Il cherche par défaut dans le texte visible lors de la lecture de l'article, et non dans le wikicode interne des pages (le langage permettant d'écrire les pages de l'encyclopédie).
Pour effectuer une recherche, saisissez le terme recherché dans la boîte de recherche située en haut. Une complétion automatique vous indique quels articles existent. Cliquez sur le terme voulu, le moteur de recherche vous y emmène directement. S'il existe une page portant ce nom exact, vous arrivez directement dessus en cliquant sur « Entrée ». Pour forcer le lancement d'une recherche dans ce contexte, sélectionnez la dernière entrée du menu déroulant, après la liste de suggestions (« Recherche les pages contenant »).
Le recours au moteur de recherche est conseillé lorsqu'il faut chercher une chaîne de caractères ou lorsqu'il faut retrouver un élément Wikidata sans connaître son identifiant. Par contre, pour des recherches complexes, cet outil n'est pas forcément adapté.

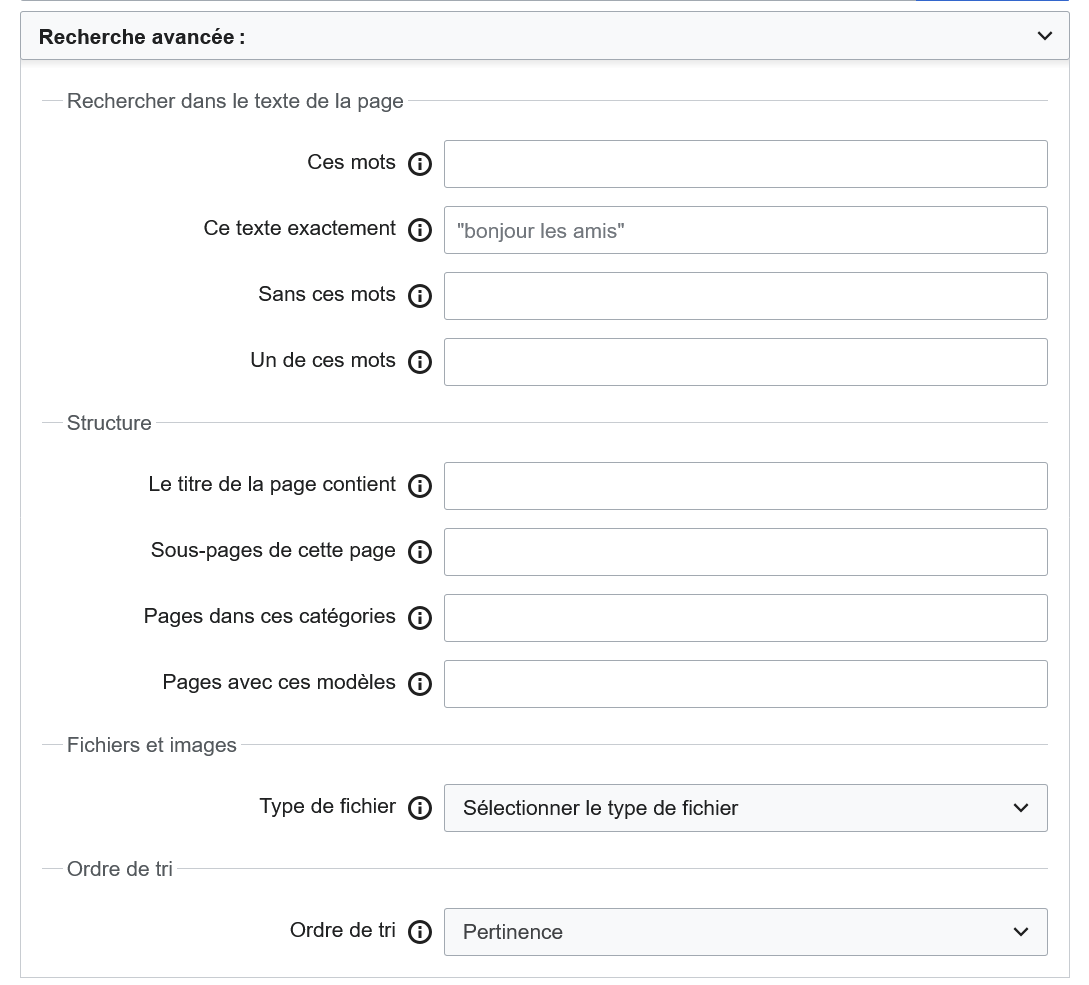
Fonctionnalités de base
| Symbole |
Description |
Exemple | Explication |
|---|---|---|---|
| Recherche par défaut | économie développement |
Pages contenant à la fois « économie » et « développement » | |
"..." |
Expression exacte | "économie du développement" |
Pages contenant l'expression « économie du développement » |
OR |
Obtenir la liste des pages où un des deux termes est présent, ainsi que les pages où les deux termes sont présents | travail OR enfants |
Pages contenant « travail », celles contenant « enfants », et celles contenant les deux termes |
- |
Ignorer un mot |
économie -France |
Pages contenant « économie » mais ne contenant pas « France » |
* |
Remplacer une chaine quelconque, au début ou à la fin d'un mot |
économi*
|
Renvoie tous les mots commençant par « économi », et *économique ceux finissant par « économique » |
~ |
Recherche approchée |
économi~ |
Renvoie aussi bien « économie » que « économique » ou « économiste » |
Fonctionnalités avancées
| Filtre |
Description |
Exemple | Explication |
|---|---|---|---|
intitle |
Recherche dans le titre | intitle:"économie française" |
Pages dont le titre contient l'expression exacte « économie française ». |
intitle:économie intitle:française |
Pages dont le titre contient le terme « économie », et ne contient pas le terme « française ». | ||
intitle:économie* |
Pages dont le titre contient un mot commençant par « économie ». | ||
intitle:/économi[es]\w/ |
Pages dont tout ou partie du titre correspond au motif de l'expression régulière « /économie[es]\w/ ». |
||
prefix |
Recherche un mot seulement dans les pages dont le titre commence par le terme souhaité |
France prefix:"économi" |
Recherche le terme « France » dans les pages débutant par « économi » |
insource |
Recherche dans le wikicode | insource:"|date=2023" |
Recherche le texte exact indiqué, espaces et caractères spéciaux compris, sensible à la casse. |
incategory |
Recherche dans catégorie |
microéconomie incategory:"économie" |
Recherche le terme dans les pages de la catégorie |
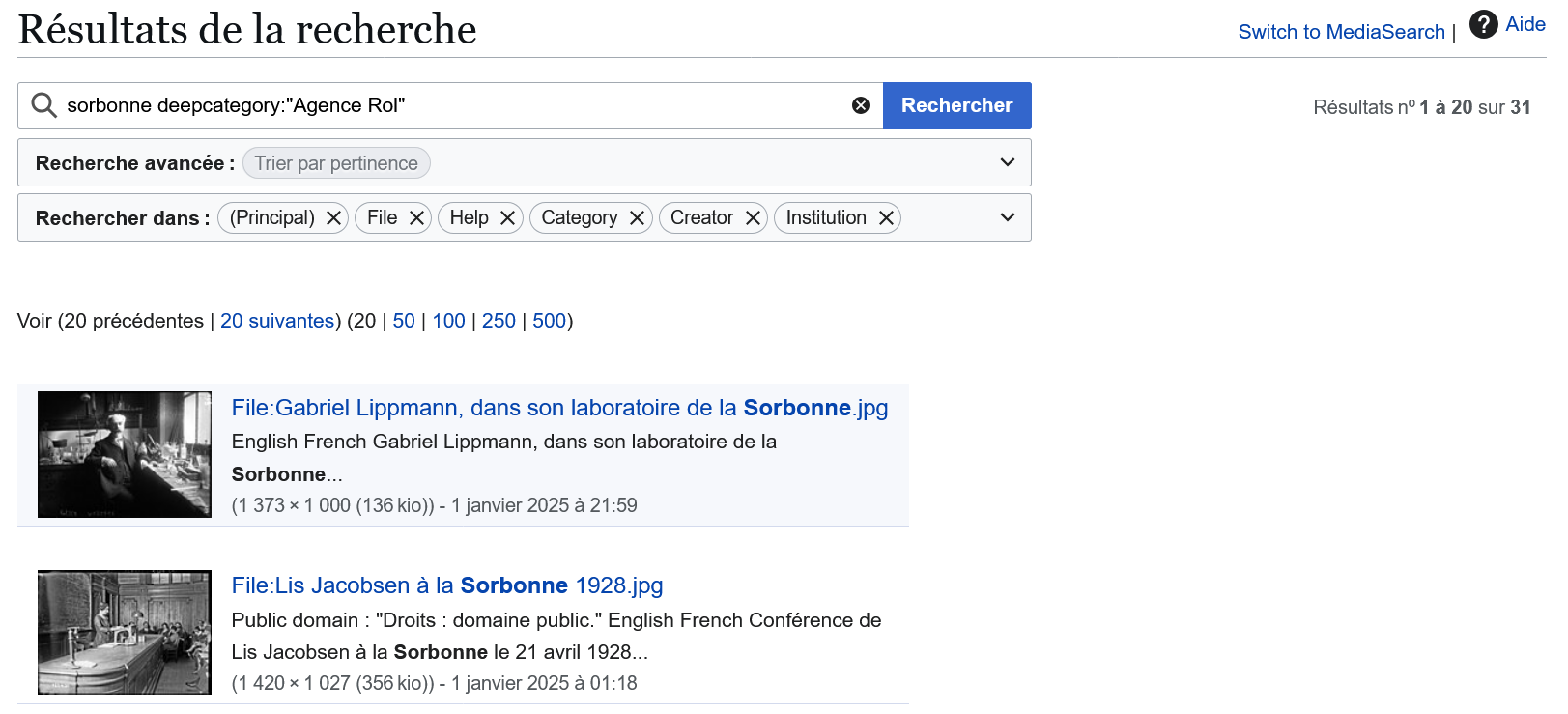
deepcategory |
Recherche dans une catégorie et sous-catégories |
microéconomie deepcategory:"économie" |
Recherche le terme ou des vidéos dans les pages de la catégorie et ses sous-catégories |
articletopic |
Recherche par sujet | articletopic:books |
Sujet obtenu par apprentissage automatique |
neartitle |
Recherche géographique | neartitle:"Paris" |
- Via l'interface graphique, il est possible d'afficher jusqu'à 500 résultats max par page.
- L'URL peut être modifiée pour afficher 5000 résultats max par page (
limit=5000). - Il n'est pas possible de consulter les résultats au delà du 9999e (
offset=10000).
Fonctionnalités spécifiques à Wikidata
La recherche dans Wikidata bénéficie de filtres spécifiques présentés ci-dessous :
| Filtre |
Description |
Exemple | Explication |
|---|---|---|---|
haswbstatement |
Renvoie les éléments qui ont une valeur spécifique dans l'instruction avec une propriété spécifique. La recherche est insensible à la casse. |
haswbstatement:P31=Q5haswbstatement:P31=Q5 A* Smith |
Éléments avec la valeur être humain (Q5) dans la propriété nature de l'élément (P31) |
chat haswbstatement:P31=Q3305213 |
Éléments comprenant chat en libellé et peinture (Q3305213) dans la propriété nature de l'élément (P31) | ||
inlabel |
Rechercher des éléments par libellé | inlabel:duck@en,fr,it |
Éléments Wikidata dont le libellé en anglais, français et italien est duck |
wbstatementquantity |
Rechercher des éléments auxquels sont associés des déclarations tout en spécifiant les quantités |
wbstatementquantity:P999=Q888>5|P999=Q888<8wbstatementquantity:P999=Q888>5 wbstatementquantity:P999=Q888<8 |
|
hasdescription |
Rechercher des éléments dont la description est rédigée dans la langue spécifiée |
|
Éléments avec des descriptions en anglais ET en allemand |
hasdescription:it,hu |
Éléments avec une description en italien OU en hongrois | ||
hasdescription:es |
Éléments avec une description en espagnol et sans description en français | ||
haslabel |
Similaire à hasdescription, mais pour les libellés |
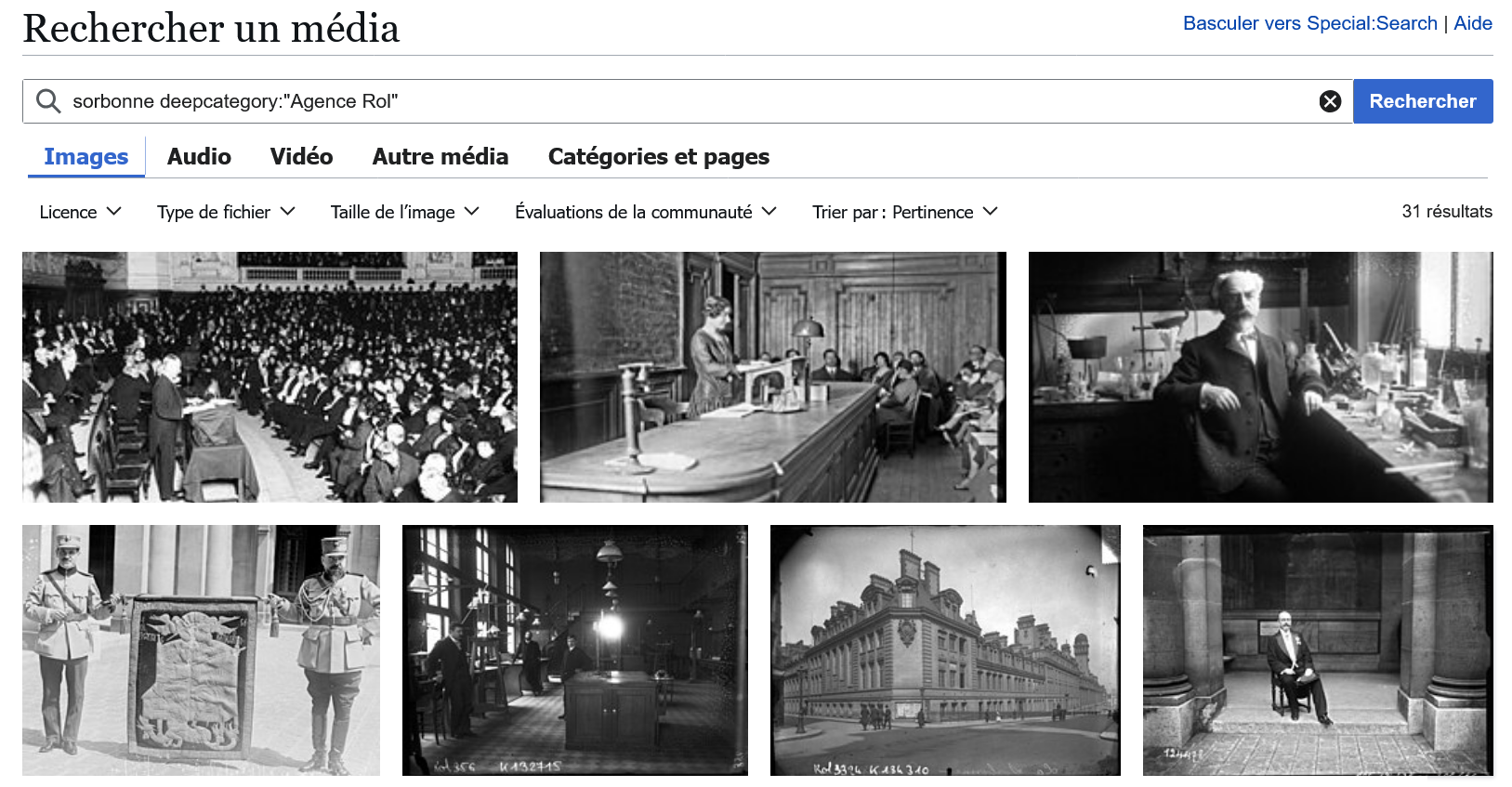
Fonctionnalités spécifiques à Wikimedia Commons
2.3. Export XML
| Documentation | Documentation avancée | Outil |
|---|
Il est relativement simple de récupérer un petit nombre de pages et d’historiques au format XML. Le nombre de versions de l’historique ou de pages à extraire est limité à 1000. Au-delà il faut utiliser l'API ou les dumps de données. La structure d'un fichier en XML est décrite dans la section 4.1 Wikipedia du chapitre 2. Données. Exemples d'utilisation : Extraction d'articles biographies de la Wikipédia en chinois dans le cadre du projet "Elites, networks, and power in modern urban China (1830-1949). Historical “big data” in modern Chinese history".
Il existe plusieurs façons d'exporter des pages en XML :
Méthode n°1 : via l'interface graphique accessible en tapant Special:Export dans le moteur de recherche de n'importe quel wiki de Wikimedia Foundation (les différents résultats proposés par le moteur de recherche renvoient vers la même page spéciale qui nous intéresse).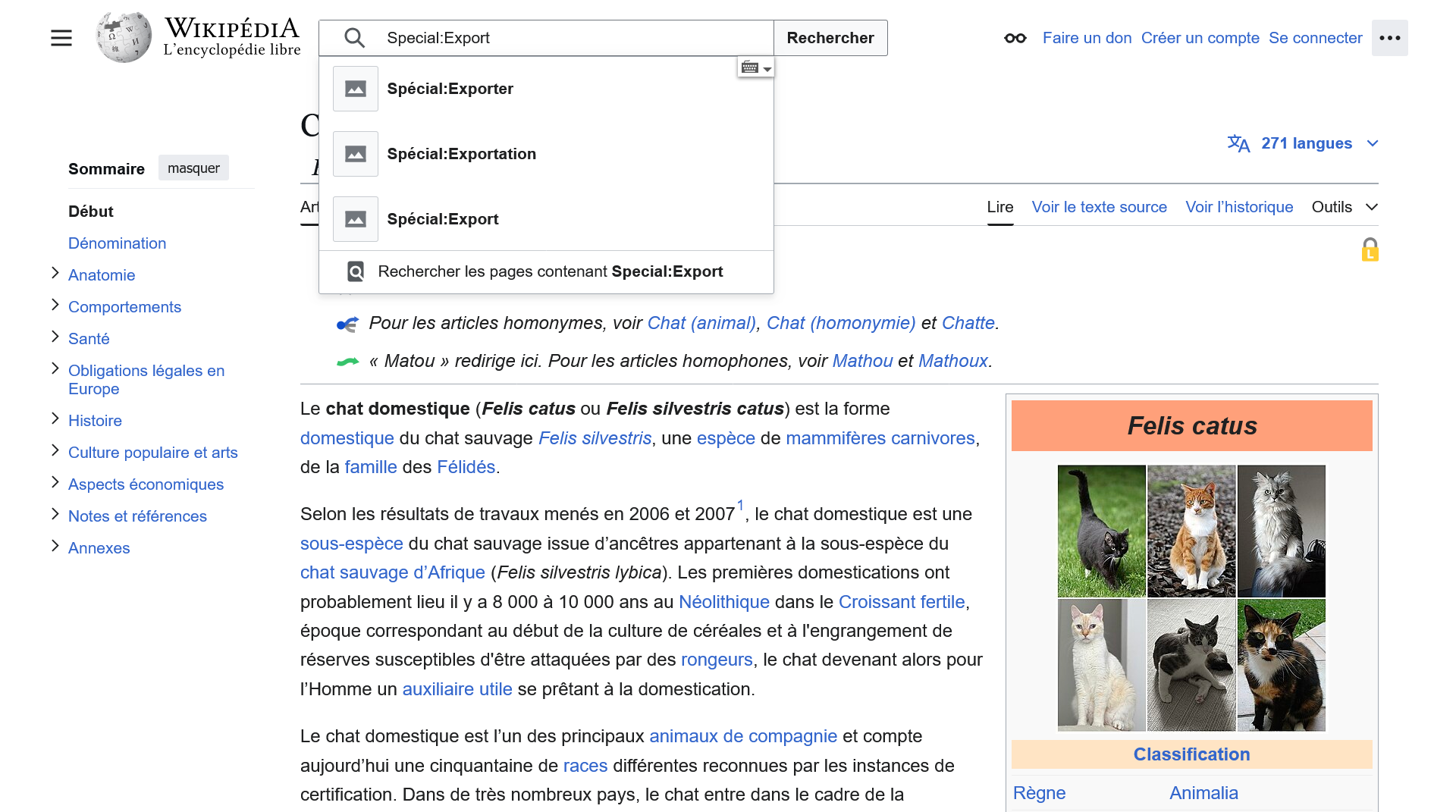
- Ajouter manuellement des pages ou automatiquement via une catégorie,
- Exporter la dernière version de la page ou toutes les révisions successives,
- Inclure ou non les modèles,
- Afficher le résultat dans le navigateur ou enregistrer le résultat dans un fichier XML.
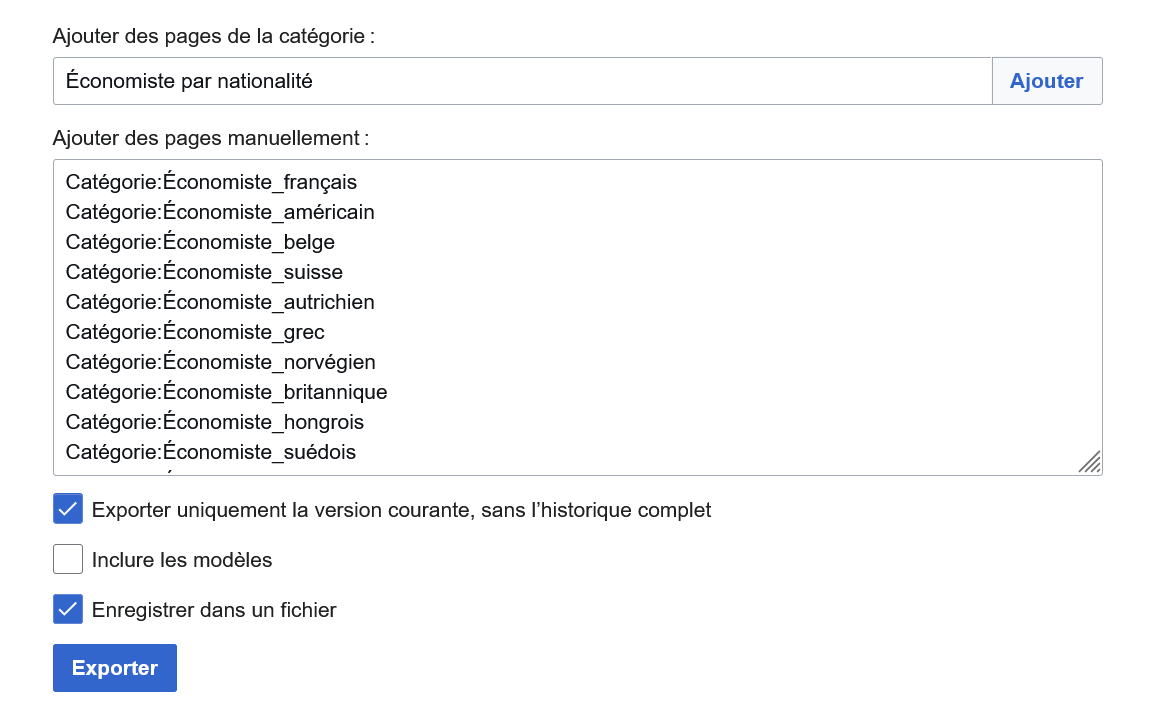
| Paramètre | Description | Exemple |
|---|---|---|
/ |
Exporter une seule page | /chat |
pages |
Exporter plusieurs pages (35 max) | pages=chien%0Achat |
addcat |
Exporter le contenu des pages d'une catégorie. S'utilise avec le paramètre catname |
|
catname |
Spécifier le nom de la catégorie. S'utilise avec le paramètre addcat |
addcat&catname=économiste |
addns |
Spécifier l'espace de nom. S'utilise avec le paramètre nsindex |
|
nsindex |
Numéro d'espace de nom. S'utilise avec le paramètre addns |
addns&nsindex=12 |
dir |
Du plus ancien au plus récent par défaut ou ordre chronologique (desc). Ne fonctionne qu'avec une requête POST |
dir=desc |
offset |
Date de départ pour récupérer les versions. Ne fonctionne qu'avec une requête POST |
offset=2010-01-01T20:25:56Z |
limit |
Nombre de versions à récupérer. Ne fonctionne qu'avec une requête POST |
limit=5 |
history |
Exporter l'ensemble des versions (1000 max) | history=1 |
templates |
Inclure les modèles | templates=1 |
wpDownload |
Sauvegarder le résultat dans un fichier | wpDownload=1 |
- https://fr.wikipedia.org/wiki/Special:Export/A : exporter la dernière version de l'article A,
- https://fr.wikipedia.org/wiki/Special:Export?pages=A : exporter la dernière version de l'article A,
- https://fr.wikipedia.org/wiki/Special:Export?pages=A&history=1 : exporter toutes les versions de l'article A depuis la plus ancienne à la plus récente,
- https://fr.wikipedia.org/wiki/Special:Export?pages=A%0ADiscussion:A : exporter la dernière version de l'article A et de sa page de discussion,
- https://fr.wikipedia.org/wiki/Special:Export?addcat&catname=Alphabet : exporter la dernière version des articles dans la catégorie Alphabet,
- https://fr.wikipedia.org/wiki/Special:Export?pages=A&wpDownload=1 : exporter la dernière version de l'article A dans un fichier XML,
- https://fr.wikipedia.org/wiki/Special:Export?pages=A&templates=1 : exporter la dernière version de l'article A et l'ensemble des modèles utilisés dans l'article.
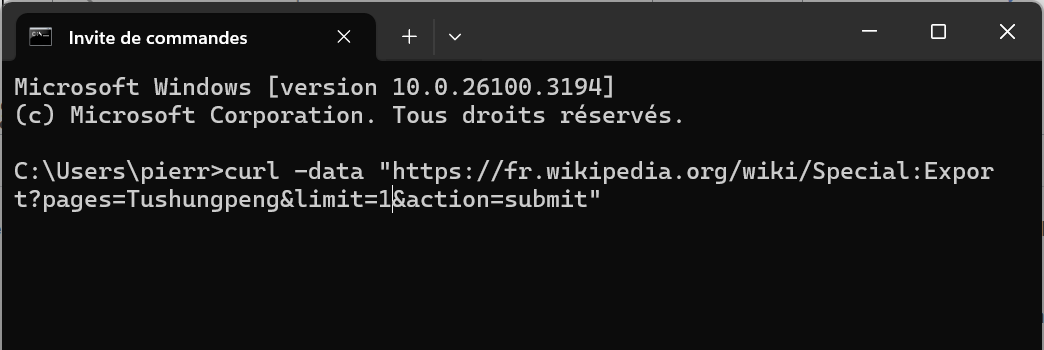
Méthode n°3 : certaines commandes ne fonctionnent qu'avec une requête
POST (une URL via le navigateur correspond à une requête GET). Voici quelques exemples à exécuter dans la console à l'aide de cURL. Sous Windows, cliquez sur l’icône Démarrer, puis cherchez invite de commande. Dans la fenêtre noire qui s'ouvre tapez l'une de ces commandes :
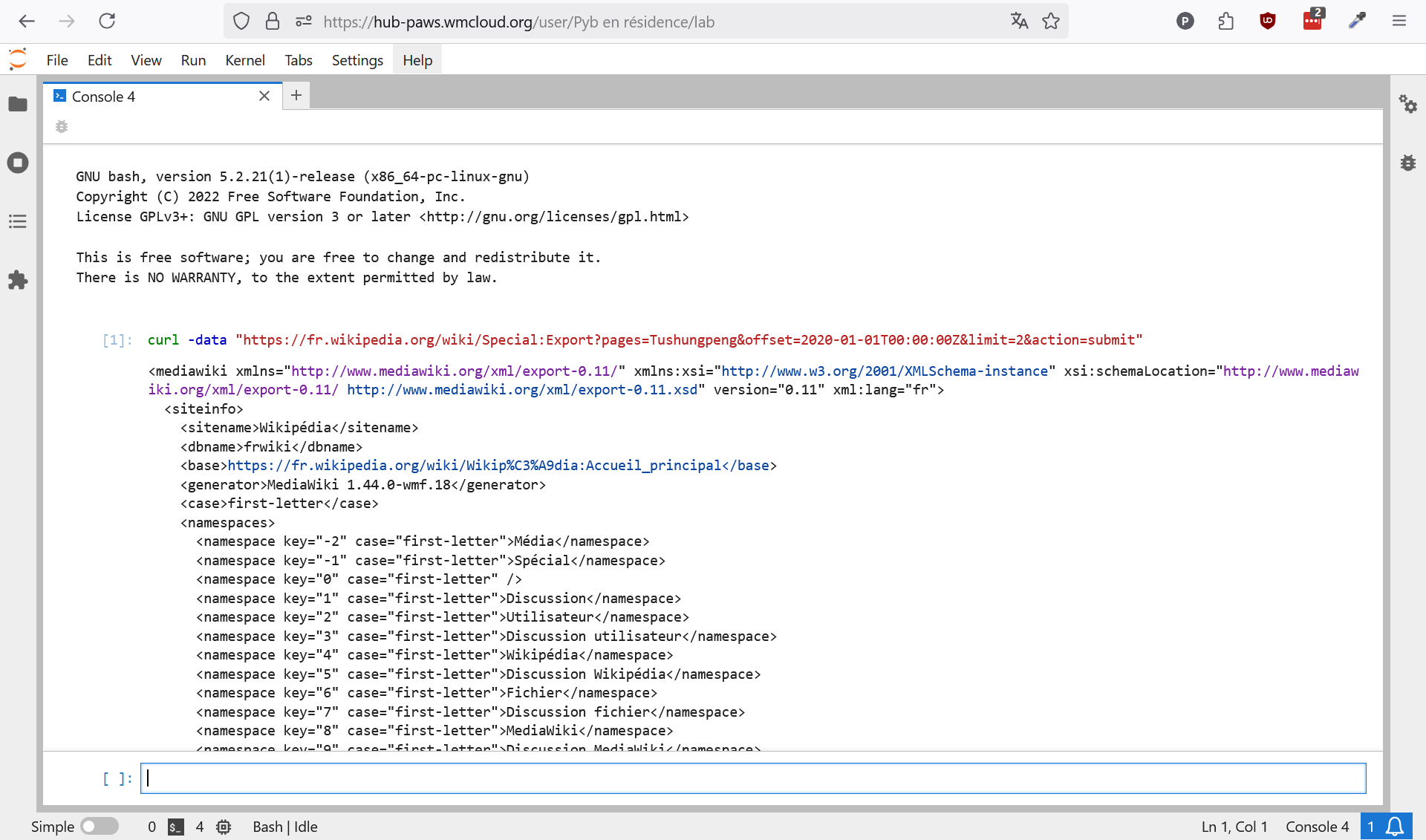
curl -data "https://fr.wikipedia.org/wiki/Special:Export?pages=Tushungpeng&history=1&action=submit": exporter toutes les versions de l'article Tushungpeng,curl -data "https://fr.wikipedia.org/wiki/Special:Export?pages=Tushungpeng&limit=5&action=submit": exporter les cinq premières versions de l'article Tushungpeng,curl -data "https://fr.wikipedia.org/wiki/Special:Export?pages=Tushungpeng&offset=2020-01-01T00:00:00Z&limit=2&action=submit": exporter les deux versions de l'article Tushungpeng postérieures au 1er janvier 2020.
2.4. PetScan
PetScan (petscan.wmflabs.org) est un puissant outil de requêtage ne nécessitant pas de connaître de langage de programmation du type SQL ou SPARQL. Il peut générer des listes d’articles Wikipédia ou d'éléments Wikidata qui correspondent à certains critères, tels que toutes les pages dans une catégorie donnée, ou tous les éléments avec une propriété donnée.
Cas d'utilisation
Véritable couteau suisse dont l'interface très chargée peut sembler déroutante au départ, PetScan s'avère très pratique pour les personnes ne voulant pas utiliser d'outils plus évolués nécessitant de savoir programmer. Pour des besoins importants en données, il faut avoir recours aux requêtes SQL et aux API.
Exemples
Voici quelques possibilités permises par l'outil :
- Articles à la fois dans la catégorie « Naissance en 1927 » et la catégorie « Football »
- Articles dans la catégorie et sous-catégories LGBT en Suisse
- Articles dont le titre contient “entente sportive”
- Jeux vidéo ne figurant pas dans la liste des jeux vidéo
- Articles sur les députés de la 16e législature par taille
- Carte des cathédrales en France
- Articles de la Wikipédia francophone n'affichant pas l'identifiant Canal U en bas de page alors qu'il se trouve sur Wikidata
Mode d'emploi
3. Outils d'interrogation de base de données
Il est possible de faire des requêtes SQL sur le contenu des wikis de Wikimedia Foundation et des requêtes SPARQL sur le contenu de Wikidata, Wikimedia Commons et Lingua Libre.
3.1. Quarry (SQL)
| Documentation | Outil |
|---|
Quarry (quarry.wmcloud.org) est un outil de Wikimedia Foundation permettant d'exécuter des requêtes SQL sur des répliques des wikis. Le SQL (Structured Query Language) est un langage informatique permettant de communiquer avec une base de données. La réplication des données est généralement instantanée. Il est également possible d'accéder aux Wiki Replicas via Toolforge et Cloud VPS.
Pour ne pas surcharger le serveur, Quarry est doté d'un temps d’exécution limité, empêchant certaines requêtes de s’exécuter. Cela touche particulièrement les gros wikis, comme la Wikipédia francophone ou Wikidata. Cet outil demeure difficile à utiliser sans connaître le langage SQL, mais la possibilité de visualiser les requêtes des autres utilisateurs simplifie un peu l’outil. Il est également possible de demander de l'aide sur la Wikipédia anglophone pour rédiger une requête : Wikipedia:QUARRY.
Exemples
Il est possible de faire des requêtes SQL pour analyser les contributions et répondre à ce genre d’interrogations :
- Quelle est la page la plus modifiée de la Wikisource en suédois ?
- Liste des 30 comptes les plus actifs sur la Wikipedia francophone (depuis 90 jours)
- Liste des 100 traducteurs les plus actifs sur la Wikipedia francophone (via l'outil Content Translation)
- D'autres requêtes concernant l'outil de traduction du contenu
- Quelle est la durée moyenne entre deux éditions de l'article “Insomnie” entre 21 h et 7 h ?
- Liste des articles renvoyant vers persee.fr
- Pages du site insee.fr les plus mentionnées
- Sites web les plus mentionnés sur les articles des communes françaises
- Nombre d’articles supprimés par jour sur la Wikipédia en français
Mode d'emploi
3.2. Query (SPARQL)
SPARQL (SPARQL Protocol and RDF Query Language) est un langage de requête sémantique de base de données, basé sur la technologie RDF. Trois projets Wikimedia peuvent être interrogés à l'aide de requêtes SPARQL :
| Service | Sigle | Interface web | API |
|---|---|---|---|
| Wikidata Query Service | WDQS | query.wikidata.org | https://query.wikidata.org/sparql. |
| Wikimedia Commons Query Service | WCQS |
commons-query.wikimedia.org | https://commons-query.wikimedia.org/sparql |
| LinguaLibre Query Service | LLQS | lingualibre.org/bigdata/#query | https://lingualibre.org/sparql |
Requêtage de Wikidata
Il est possible d'interroger les données de Wikidata via l'endpoint SPARQL, le Wikidata Query Service propulsé par Blazegraph, de deux façons différentes :
- une interface web interactive query.wikidata.org
- une API permettant d'envoyer des requêtes
GETouPOSTàhttps://query.wikidata.org/sparql.
- Un support de formation pour découvrir le langage SPARQL. La dernière version est téléchargeable sur Zenodo.
- Un aide mémoire pour maîtriser les requêtes SPARQL. Il présente quelques paramètres spécifiques au duo Wikidata-Blazegraph mais pourra être utile pour d'autres points de terminaison SPARQL. Le cheatsheet a été pensé pour différents niveau de maîtrise du langage de requêtes SPARQL. Une signalétique indique trois niveaux de difficulté (facile, intermédiaire, difficile). La dernière version est téléchargeable sur Zenodo.
- Les politiques relatives aux robots et aux agents utilisateurs s'appliquent.
- Si votre requête n'aboutit pas, demandez l'aide de la communauté pour l'optimiser (il y a une limite de 60 secodes pour le temps d'exécution de la requête).
- Si vous obtenez une réponse
429 Too Many Requests, faites une pause. - Ajoutez
?timeout=5(= 5 secondes) pour que la requête se termine plus tôt. Utile dans les cas où une réponse rapide est nécessaire, et où une réponse tardive ne serait de toute façon pas utilisable.
Requêtage de Wikimedia Commons
4. API
Qu'est-ce qu'une API ?
Une API, — ou Application Programming Interface — est « un ensemble de fonctions informatiques par lesquelles deux logiciels interagissent sans intermédiation humaine » (Rémi Mercier). Par exemple, « l’utilisateur effectue une requête sous la forme d’une requête HTTP, le service web met en forme les données correspondant à la requête et les renvoie à l’utilisateur, dans un format défini à l’avance » (Romain Tavenard).
Mode d'emploi
Voici une première requête API, la plus simple possible :
https://fr.wikipedia.org/w/api.php?action=query&titles=Perruchehttps://fr.wikipedia.org/w/api.phpest l’endpoint de l’API REST, c’est-à-dire l’URL à laquelle envoyer les appels. Tous les wikis de Wikimedia Foundation disposent d'une API accessible via une URL de ce type, par exemple :
?: le premier paramètre est précédé d'un séparateur point d'interrogation.
action=query: premier paramètre de cet appel qui se compose du paramètreactionet de sa valeurquery, qui signifient de récupérer le contenu d’un article Wikipedia.
titles=Perruche: le paramètretitlesdéfinit le titre de l'article Wikipedia ciblé, en l'occurencePerruche. L’API permet également de préciser plusieurs valeurs séparées par une barre verticale (|) pour obtenir les contenus de plusieurs articles dans un seul et même appel. Par exemple :titles=Perruche|Perroquet|Corneille|Corbeau.
"title": Perruche), son numéro d'identifiant ("pageid": 250509) et l'espace de nom de la page ("ns" : 0 correspond à l'espace de nom principal où figurent les articles encyclopédiques).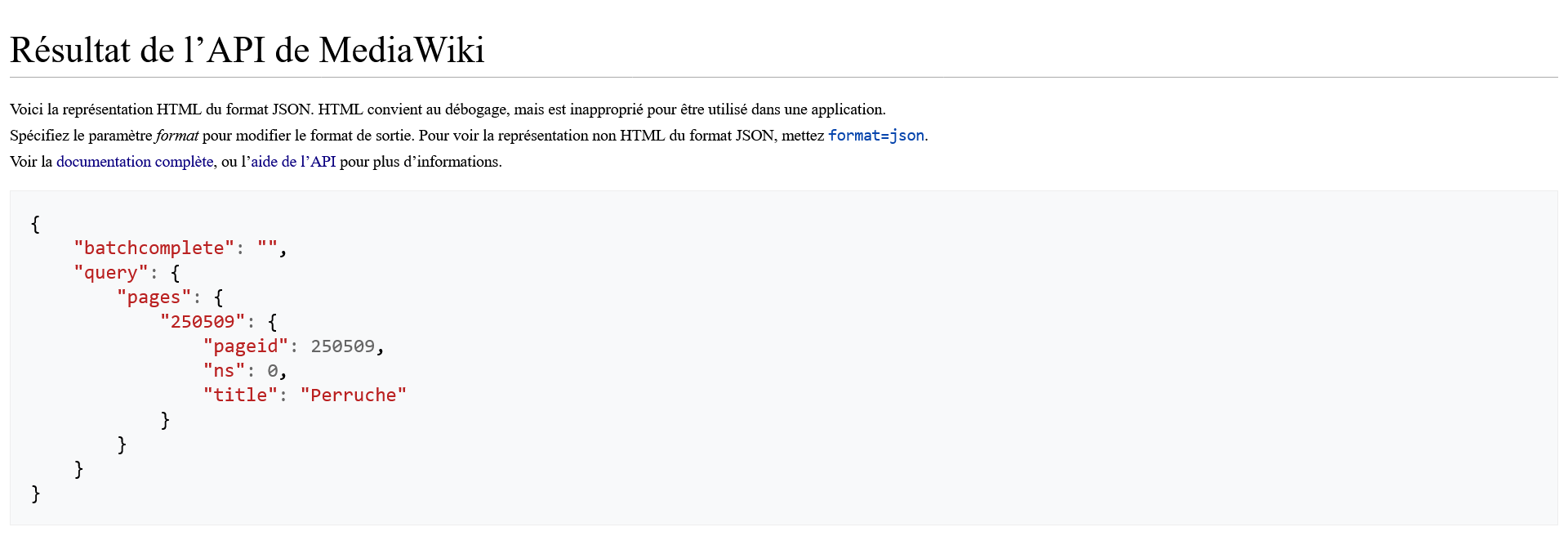
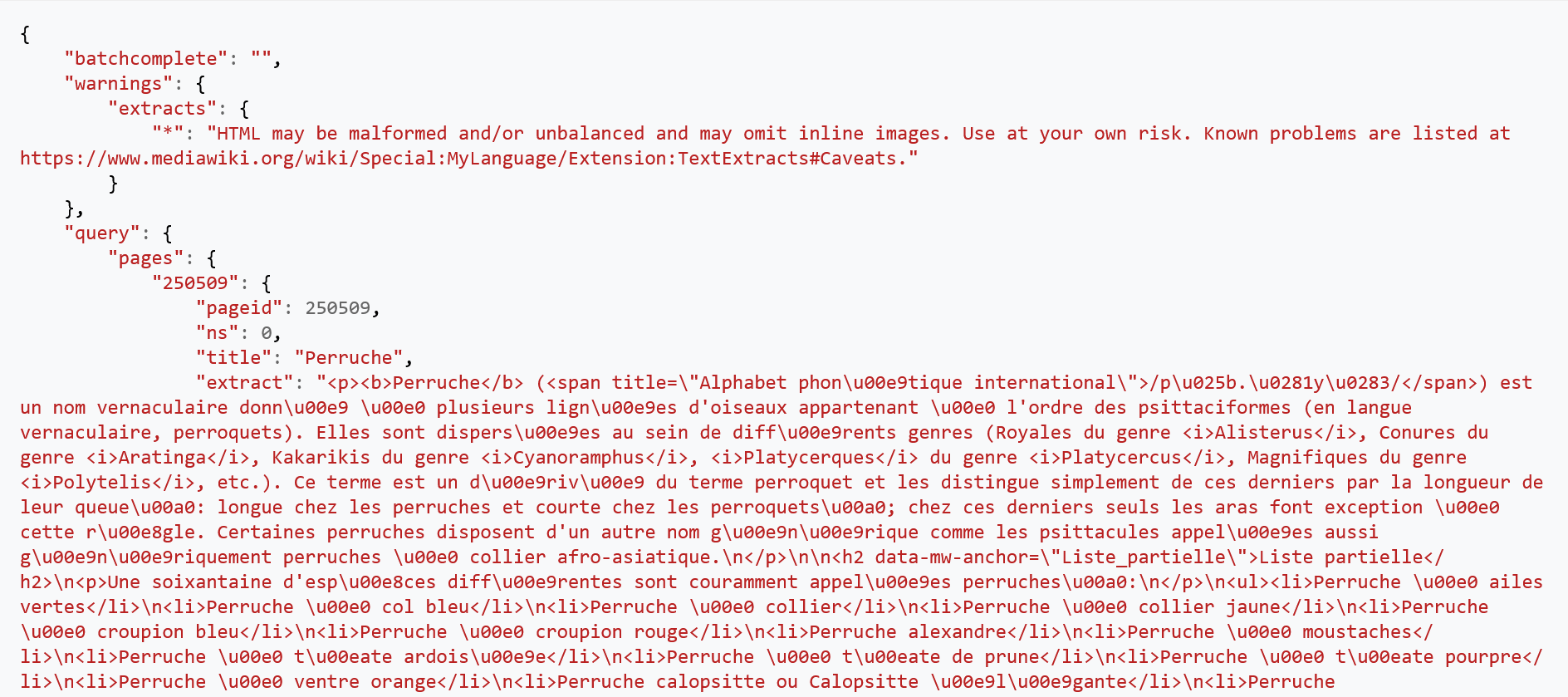
Nous allons complexifier notre première requête en ajoutant petit à petit des paramètres :
https://fr.wikipedia.org/w/api.php?action=query&titles=Perruche&prop=extractsprop=extracts: ce paramètre permet de récupérer un extrait de l'article.
https://fr.wikipedia.org/w/api.php?action=query&titles=Perruche&prop=extracts&exchars=500
exchars=500: ce paramètre limite l'extrait à 500 caractères.
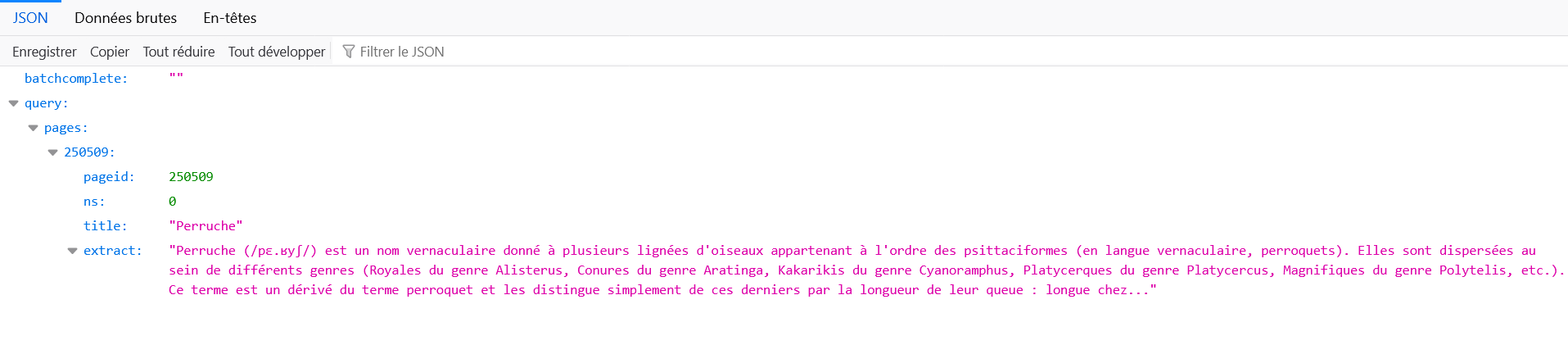
https://fr.wikipedia.org/w/api.php?action=query&titles=Perruche&prop=extracts&exchars=500&explaintext
explaintext: ce paramètre permet d'obtenir l'extrait en texte brut plutôt qu’en HTML. Il s'agit d'un paramètre booléen. Il n'a donc que deux valeurs possibles : vrai ou faux.

https://fr.wikipedia.org/w/api.php?action=query&titles=Perruche&prop=extracts&exchars=500&explaintext&utf8
utf8: paramètre booléen qui active l’encodage du texte en UTF-8

https://fr.wikipedia.org/w/api.php?action=query&titles=Perruche&prop=extracts&exchars=500&explaintext&utf8&format=jsonformat=json: il est possible de récupérer les données dans différents formats (json,jsonfm,none,php,phpfm,rawfm,xmletxmlfm).
Documentation
Politiques et recommandations
S'authentifier. Afin de ne pas surcharger les serveurs, une limitation du débit de l’API est mise en place. Il est possible de faire 500 requêtes par heure par adresse IP ou 5000 avec un jeton d’accès personnel. Pour de gros volumes de données, il vaut mieux utiliser les dumps.
Exemples
- Début des articles Perruche et Perroquet :
?action=query&titles=Perruche|Perroquet&prop=extracts&exchars=500&explaintext&utf8&format=json&exintro
- Première image affichée dans l’article Perruche de la Wikipédia francophone :
?action=query&format=json&prop=pageimages&titles=Perruche&piprop=original
- Contenu textuel de l'article sur les perruches :
?action=query&origin=*&prop=extracts&explaintext&titles=Perruche&format=json
- Dixième section de l'article Chat :
?action=parse&format=json&page=Chat&prop=wikitext§ion=10&disabletoc=1&utf8=1
- Coordonnées géographiques de l'article avec page ID 399 :
?action=query&format=json&prop=coordinates&pageids=399&coprimary=all
5. Outils de programmation
Dans la suite de ce chapitre, nous présentons brièvement quelques bibliothèques R et Python ainsi que l'instance Jupyter Notebook de Wikimedia Foundation.
5.1. PAWS (Jupyter Notebook)
Les notebooks Jupyter sont des carnets électroniques qui peuvent contenir dans un même document du texte, des images, des formules mathématiques, ainsi que du code informatique exécutable et afficher le résultat de ce programme directement dans un navigateur web.
Jupyter Notebooks tire son nom des trois langages de programmation (Julia, Python et R) gérés initialement. Dorénavant, les carnets Jupyter supportent des dizaines de langages de programmation. Ces carnets permettent d'obtenir une recherche plus transparente et plus reproductible. Ils facilitent la présentation de travaux en programmation et permettent le codage collaboratif
Wikimedia Foundation a déployé sa version de Jupyter Notebook sous le nom de PAWS: A web shell. PAWS permet d'accéder aux contenus des wikis via les API mais également les wiki replicas.
Exemples
- https://wikitech.wikimedia.org/wiki/PAWS/PAWS_examples_and_recipes
- https://www.wikidata.org/wiki/Wikidata:PAWS

Mode d'emploi
Utiliser PAWS :- Lancez PAWS.
- Cliquez sur le bouton Sign in with MediaWiki.
- Connectez-vous à votre compte Wikimedia ou créez en un.
- Donnez l'autorisation à PAWS d'exécuter certaines actions sur votre compte.
Créer un nouveau carnet ou en importer un :
- Cliquez sur le bouton New et choisissez le type de carnet :
Partager un notebook :
- Utilisez le bouton Public Link ou PAWS public link en haut à droite pour générer un lien public ou
- Modifiez manuellement l'URL pour rendre votre carnet public :
https://public-paws.wmcloud.org/User:YOURUSERNAME/YOURNOTEBOOK.ipynb
Copier un notebook :
- Récupérer l'URL d'un carnet public (tous les carnets sont publics). Exemple:
https://public-paws.wmcloud.org/YOURUSERNAME/YOURNOTEBOOK.ipynb - Ajoutez
?format=rawà la fin de l'URL pour télécharger un fichier.ipynb. Exemple:https://public-paws.wmcloud.org/YOURUSERNAME/YOURNOTEBOOK.ipynb?format=raw - Connectez-vous à votre compte PAWS et cliquez sur upload pour importer le carnet dans votre espace personnel.
5.2. Python
Python est un langage de programmation interprété, créé à la fin des années 1980 par Guido van Rossum. Ce langage de haut niveau est reconnu pour sa syntaxe clair et lisible. Sa polyvalence et sa flexibilité en font un des langages de programmation les plus populaires. Il est notamment très utilisé dans le domaine de la data science et au sein du mouvement Wikimedia.Exemples
- Installation de la bibliothèque (appelée également package ou librairie) :
pip install wikipedia
- Configuration :
import wikipedia
wikipedia.set_lang("fr")
- Récupérer le résumé introductif de l'article Pomme :
wikipedia.summary("Pomme")
- Récupérer les 3 premières phrases de l'article :
wikipedia.summary("Pomme",sentences=3)
- Récupérer tout le contenu de l'article :
wikipedia.page("Pomme").content
- Récupérer les images de l'article :
wikipedia.page("Pomme").images
- Récupérer les catégories de l'article :
wikipedia.page("Pomme").category
- Installation de la bibliothèque :
pip install wikidata- Configuration :
from wikidata.client import Clientclient = Client()- Sélection de l'élément Pomme :
entity = client.get("Q89", load=True)- Afficher le libellé de l'élément :
entity- Afficher la description de l'élément :
entity.description
- Afficher le caractère Unicode de l'élément :
unicode_prop = client.get("P487")unicode = entity[unicode_prop]unicode5.3. R
Tidywikidatar
WikidataQueryServiceR
Glitter
6. Flux des modifications récentes
| Documentation | Outil | Exemples |
|---|
Wikimedia Foundation met gratuitement à disposition EventStream qui permet de suivre en temps-réel les modifications apportées à Wikipedia et l'ensemble des wikis hébergées par la fondation. Ce flux est accessible via l'url stream.wikimedia.org au format JSON ou il peut être consommé via l'API du moteur du wiki. Outre les modifications apportées aux articles encyclopédiques, il est notamment possible de suivre l'activité en matière de création, suppression et restauration de pages, renommage de pages ou encore le score d'évaluation des révisions par les outils d'apprentissage automatique.
Cas d'utilisation
- Produire un tableau de bord actualisé en temps réel
- Avoir besoin de beaucoup données à jour