Tour d'horizon des données ouvertes
| Site: | Callisto Formation |
| Cours: | Corpus et données : comment utiliser les données ouvertes de Wikimedia |
| Livre: | Tour d'horizon des données ouvertes |
| Imprimé par: | Visiteur anonyme |
| Date: | vendredi 9 janvier 2026, 09:44 |
1. Introduction
Après un rapide aperçu de ce qu’il était possible de faire avec les contenus et données des projets Wikimedia, ce chapitre aborde les principales sources de données utilisées. Vous découvrirez les points suivants :
- Quelles sont les données existantes ?
- Quelles sont les conditions pour y accéder ?
- Quelles sont les conditions de réutilisation de ces données ?
Le mouvement Wikimedia comprend plus de 1000 sites basés sur la technologie wiki. Le contenu est rédigé dans plus de 300 langues et 35 systèmes d'écritures différents. En tout, cela représente plus de 60 millions d'articles encyclopédique dans les différentes versions linguistiques de Wikipedia, plus de 100 millions de médias dans Wikimedia Commons, des millions de mots de vocabulaire dans les différents versions du Wiktionnaire, etc.

Données statistiques de la Wikipedia francophone. 10.5281/zenodo.15236570
Outre le contenu intrinsèque des projets Wikimedia, la consultation et l'élaboration des wikis génèrent de nombreuses données : nombre de fois qu'une page est consultée, tout un tas de données provenant des serveurs, historique des modifications d'un article et historique des contributions d'un rédacteur, nombre de clics sur un lien, etc. De plus, les chercheurs mettent régulièrement à disposition des jeux de données spécifiques en retravaillant les données extraites des projets Wikimedia, par exemple des jeux de données sur les références bibliographiques utilisées dans Wikipedia ou les personnes célèbres présentes dans l'encyclopédie.
Voici un récapitulatif des sources de données présentées dans ce chapitre et le suivant :
| Source | Contenu | Accès | Format | Actualisation | Quantité | Limites |
|---|---|---|---|---|---|---|
| Wikimedia Foundation dumps | métadonnées contenu relations |
hors ligne | XML SQL |
bimensuelle | données massives | gros volume de données et données au format wikitexte |
| Wikimedia Enterprise dumps | contenu | hors ligne | HTML | mensuelle | données massives | gros volume de données |
| Analytics dumps : jeux de données de l'activité des wikis | pages vues activité |
hors ligne | TSV | mensuelle | données massives | gros volume de données |
| MediaWiki API MediaWiki REST API Wikimedia REST API |
métadonnées contenu relations statistiques |
en ligne | JSON PHP WDDX XML YAML |
temps réel | micro données | pas adapté pour extraire beaucoup de données |
| Wiki replicas : copies en temps réel et nettoyées des bases de données | métadonnées contenu relations |
en ligne | SQL | quasi temps réel | micro données | pas adapté pour extraire beaucoup de données |
| EventStreams : suivi en direct de l'activité des wikis | logs | en ligne | JSON SSE |
temps réel | traitement des données | |
| Wikimedia Statistics : rapports statistiques | pages vues contenu activité |
en ligne | CSV JSON |
mensuelle | micro données | pas adapté pour extraire beaucoup de données |
| dons collectés | en ligne |
CSV |
quotidienne | micro données |
||
| Entrepôts de données : sources extérieures de données | jeux de données spécifiques |
hors ligne |
Source : inspiré du tableau 4 d'Arroyo-Machado, Wenceslao, et al. “Wikinformetrics: Construction and Description of an Open Wikipedia Knowledge Graph Data Set for Informetric Purposes”, Quantitative Science Studies, vol. 3, no. 4, 2022, pp. 931–52.
2. Sources de données
Wikimedia Foundation met à disposition un très grand nombre de données, dès lors qu'elles respectent la vie privée des personnes qui consultent et rédigent les projets Wikimedia.
Les jeux de données sont en accès libre et publiés sous licence libre sur dumps.wikimedia.org. Une liste détaillée peut être consultée sur Research:Data. En outre, les chercheurs peuvent accéder à certaines données non-publiques sous réserve de la signature d'un accord de non-divulgation (NDA).
Il est également possible de trouver des données des projets Wikimedia déposées par des chercheurs sur des entrepôts de données. Nous listons les principaux ci-dessous :


Zenodo (CERN)

Figshare (Springer)

Dimensions (Springer)


Academic Torrents (Institute for Reproducible Research)
3. Données de consultation
En matière de données de consultation des wikis, il ne faut pas s'attendre à trouver autant de données sur les utilisateurs que sur d’autres grandes plateformes Internet. Wikimedia Foundation collecte très peu de données personnelles sur les internautes et à des principes de diffusion des données très strictes en matière de respect de la vie privée. Il est donc impossible par exemple de connaître les habitudes de consultation d’un internaute, le pourcentage de femmes qui rédigent Wikipedia ou même le nombre de visiteurs uniques du site.
Il est néanmoins possible d'obtenir 3 types d'information :
- Fréquentation des sites, pages et fichiers des wikis de Wikimedia Foundation,
- Flux de clics de quelques versions linguistiques de Wikipedia,
- Système d'exploitation et navigateurs utilisés par les internautes.
3.1. Consultation des pages
L'audience d'un site internet, a fortiori celle de Wikipedia, n'est pas une réalité simple et unidimensionnelle cernable avec un seul indicateur. De plus, la mesure, la conservation et la diffusion de ces données demandent des ressources humaines, financières et techniques dont le mouvement Wikimedia n'a pas toujours disposées. Ce chapitre présente les données publiques disponibles, la définition de ce qui est mesuré, l'évolution au cours du temps des données recueillis et pointe quelques limites afin de correctement analyser ces jeux de données. La Wikimedia Foundation met à disposition de tous la fréquentation des wikis qu'elle héberge. Il est possible de remonter jusqu'à mai 2015, voire jusqu'en 2007 via les archives, mais au prix de nombreuses ruptures statistiques rendant délicate l'analyse sur longue période.
Données ouvertes
Il existe plusieurs façons d'accéder aux données. Pour connaître la fréquentation de quelques pages, une interface visuelle est proposée : la suite d'outils pageviews. Pour un nombre plus important de pages ou un besoin d'automatisation, une API ouverte est disponible. Enfin les données sont librement téléchargeables et publiées sous la mention Creative Commons CC0. Les dumps de données prennent la forme d'un fichier compressé par heure.
Par ailleurs, de nombreux outils, plus ou moins éphémères, voient régulièrement le jour à partir de ce jeu de données. C'est également un domaine important en matière de création de visualisation de données.
Enfin il y a une littérature abondante analysant la fréquentation de Wikipedia ou les chercheurs se servent du nombre de vues dans leur démonstration (Ball, 2023). Une récente revue de la littérature a étudié l'utilisation du nombre de vues dans Wikipedia dans le domaine de la santé (Alibudbud 2023). Un autre papier analyse l'impact de Wikipedia sur la science en utilisant entre autre la consultation des articles (Thompson et Hanley 2018). La consultation de l'encyclopédie peut aussi être utilisé pour mesurer l'intérêt du public pour un sujet donné, par exemple les aires protégées (Guedes-Santos et al. 2021), les reptiles (Roll et al. 2016) ou les sites touristiques (Owuor et al. 2023), la grippe (Brownstein et Mclever, 2014, McIver et Brownstein, 2014, De Toni et al., 2021), les épidémies mondiales (Provenzano et al., 2019), la grippe porcine (Ritterman et al., 2009), le coronavirus (O'Leary et Storey, 2020), si le Ice Bucket Challenge a sensibilisé les gens à la sclérose latérale amyotrophique (Bragazzi et al., 2017), le succès d'un film au cinéma (Mestyán et al., 2013), les résultats électoraux (Yasseri et Bright, 2016, Salem et Stephany, 2021), l'essor de l'extrême droite en Allemagne (Debus et Florczak 2022), le cour de la bourse (Moat et al., 2013, Zimmerman, 2020, Gómez-Martínez et al. 2022), l'incidence des restrictions en matière de droits d'auteur sur la réutilisation des connaissances (Nagaraj, 2017).
Dans la suite du cours, nous présenterons les liens vers les principales ressources utiles à l'aide d'icônes :
| Documentation | Données | API |
Dataviz |
|---|
Historique de la mesure de l'audience
La mesure de la fréquentation des wikis de Wikimedia Foundation n'a pas été un long fleuve tranquille. Voici une présentation des principales étapes montrant l'évolution dans la mesure de l'audience. Ce travail repose sur la chronologie de la mesure d'audience Wikimedia complétée par la documentation technique.
Définition de l'indicateur
La définition d'une page vue est la suivante depuis 2015. La documentation technique permet de savoir ce qui est précisément mesuré.
Une requête du journal des requêtes web est comptabilisée comme une page vue si elle remplit les conditions suivantes :
- l'entête HTTP X-Analytics ne contient pas
preview=1; - le code de réponse HTTP est
200 OKou304 Not Modified; - le type MIME est une version de
text/htmlouapplication/jsonpour les requêtes de l'application mobile ; - l'une ou l'autre des conditions suivantes :
- l'entête HTTP X-Analytics contient
pageview=1, ou - l'URL répond aux critères suivants :
- il comporte un site en production (Wikipedia, Wikisource, Meta, Commons, etc.) ;
- it comporte un répertoire de contenu (principalement
/wiki/, mais aussi/zh-hant/ou une autre variante linguistique) ; - il ne s'agit pas d'une page spéciale.
- l'entête HTTP X-Analytics contient
Bien que les modifications d’un article ne soient pas comptabilisées dans ce jeu de données, les pics de consultation d'articles très peu consultés peuvent tout de même être liés à un moment de forte activité de la part d'un ou plusieurs rédacteurs car dans la phase de rédaction, il peut être nécessaire de consulter l'article à plusieurs reprises.
L'API n'est pas prise en compte sauf dans un cas bien particulier. De plus, selon la méthode utilisée pour faire du web scraping des projets Wikimedia, cela va être ou non comptabilisé dans le nombre de vues d’une page. L'article Wikipedia intitulé Liste de sondage élections présidentielles de 2022 est un bon exemple d’article dont le contenu a été régulièrement scrappé en 2022, jusqu’à en faire un des articles les plus consultés durant cette année électorale.
Trafic humain vs Trafic automatisé
L'analyse de la consultation de l’encyclopédie n'est pas simple. Outre les internautes qui consultent le site pour lire le contenu, il y a ceux qui scrapent le contenu, les robots qui indexent le web et tout un tas d'autres cas : des personnes qui gonflent exprès le nombre de vues, des outils mal configurés et d'autres cas où la page n'est pas consultée pour son contenu. Il n'est pas rare de voir des courbes de fréquentation d'articles anormales sans qu'il soit possible d'en determiner la raison. C'est un sujet encore très peu etudié, que ce soit en interne (en 2023 aucun salarié de Wikimedia Foundation n'est dédié à ce sujet) ou de la part des journalistes et des chercheurs.
Dans les jeux de données mis à disposition, Wikimedia Foundation met a part le trafic provenant des moteurs de recherche et depuis 2020, la Fondation distingue le trafic automatisé, du trafic généré par les robots d’indexation et du trafic généré par les lecteurs stricto sensu. Le jeu de données comporte trois types d’agent utilisateur (user agent) :
- Utilisateur : les êtres humains qui consultent Wikipedia sur un ordinateur ou un téléphone ;
- Robot d'indexation : les robots des moteurs de recherche qui indexent le web (Bing, BNF, Google, Qwant...) ;
- Trafic automatisé : il peut s'agir par exemple de robots qui tentent de mettre en tête des articles les plus consultés des articles traitant de la sexualité, la pornographie ou la politique. La détection automatique du trafic automatisé est récente (sans reclassification du trafic passé) et très imparfaite. Beaucoup de trafic automatique se retrouve encore catégorisé comme du trafic humain. Et vice-versa, il doit y avoir du trafic humain catégorisé comme du trafic automatisé.
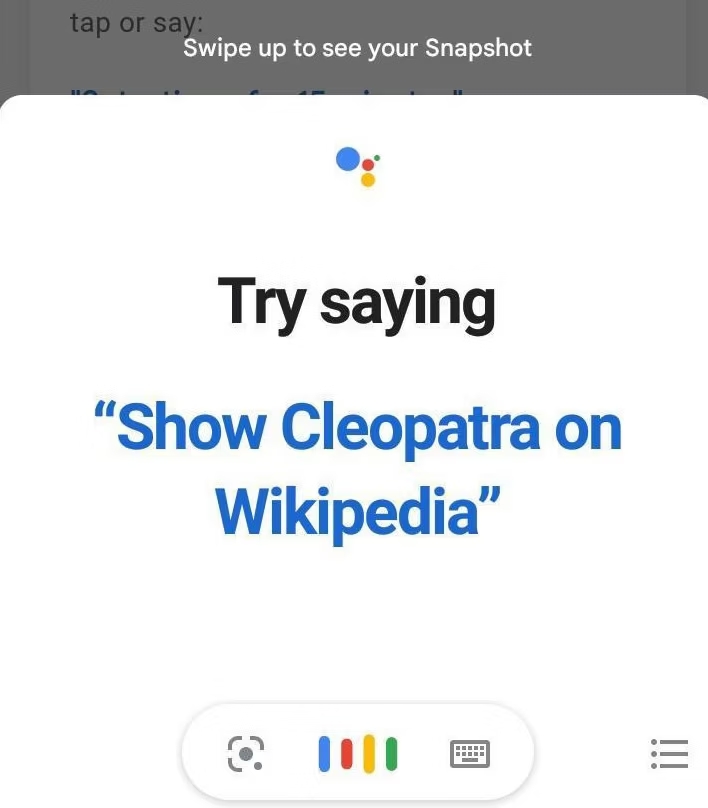
Étude de cas : Cléopâtre
L'analyse du trafic de Wikipedia est de plus en plus compliquée. Outre le cas standard d'un internaute intéressé par un article de l'encyclopédie, il y a de nombreux outils automatisés qui consultent Wikipedia afin d'en extraire des données (cela va des robots d'indexation au web scraping). Dans les deux cas, le site est consulté parce que son contenu intéresse l'internaute. Mais il y a sans doute un troisième cas assez fréquent où l'internaute consulte Wikipedia sans que son contenu l'intéresse.
La biographie Wikipedia en anglais et en espagnol sur Cléopâtre figure régulièrement dans les articles les plus consultés. Cléopâtre est un personnage célèbre, mais cela ne suffit pas à justifier un tel trafic limité à deux langues. Une analyse détaillée de l'audience permet de s'apercevoir que le trafic provient de consultations faites par téléphone portable.
Bien souvent, nous n'avons pas d'explication à ces courbes d'audience anormales. Mais ce cas fait exception. Google invite ses utilisateurs à tester l'outil de commande vocale en chargeant l'article Cléopâtre.
Comme les autres moteurs de recherche, Google présente très souvent Wikipedia dans les premiers résultats. Et ponctuellement, Google génère des pics de consultation via les bannières Google Doodles affichées pour célébrer un événement ou une personnalité. Cette fois-ci il ne s'agit pas de trafic aberrant, mais cela montre l'importance de Google dans l'étude du trafic d'un site web, a fortiori dans le cas de Wikipedia. C'est aussi le signe qu'une décision a priori anodine peut avoir des effets très importants (Yasseri, 2023).
Étude de cas : Aster des jardins
Il n'y a pas que les articles qui peuvent avoir un trafic anormalement élevé. Pendant plusieurs mois entre 2020 et 2021, un fichier représentant une fleur a totalisé plus de 60 millions de requêtes par jour. Le trafic provenait d'Inde et représentait 20 % du trafic générés par les médias dans le datacenter EQSIN situé à Singapour. Dès qu'elle a découvert le problème, l'équipe de Wikimedia Foundation a rapidement détecté l'origine : il s'agissait d'une application mobile de réseautage social populaire en Inde qui était mal configurée.

Conseils pour détecter les cas aberrants
- Analysez le trafic sur une période longue.
- Regardez la répartition du trafic selon les méthodes d'accès. Moins de 10% pour l'ordinateur ou le mobile est suspect.
- Jetez un œil au trafic dans d'autres langues. Si un sujet mondialement connu voit sa courbe d'audience fortement grimpée que dans une seule langue, cela peut être suspect.
- Vérifiez si le sujet est évoqué sur les réseaux sociaux. Cela permet notamment de détecter les pics de consultation liés aux jeux télévisés.
- L'actualité doit également être prise en compte.
- Utiliser l'API PageViews pour obtenir la liste des articles les plus consultés par pays afin de mieux comprendre ce qui se passe. Cela permet par exemple de voir que le trafic démesuré sur l'article en français traitant des cookies informatiques provient des États-Unis et du Royaume-Uni.
Exemples de courbes de fréquentation
3.2. Consultation des médias
Wikimedia héberge plus de 100 millions de fichiers, principalement des images fixes, mais également des textes, des fichiers audio et un peu de vidéos. Exemples de contenus provenant de l'enseignement supérieur et la recherche :










{kind=link}
_(Ifremer_00576-68854).jpg){kind=link}
{kind=link}
.jpg){kind=link}
{kind=link}
.jpg){kind=link}
{kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}
Plusieurs méthodes permettent de mesure la consultation des images. Il est tout d'abord possible d'obtenir le nombre de requêtes des fichiers ou bien de mesurer le nombre de vues des pages illustrées par des fichiers. Voici un comparatif des données disponibles :
Données de consultation des médias
| Données |
Mesure | Filtrage du trafic |
Granularité des données |
Début de mesure |
Méthode |
|---|---|---|---|---|---|
| PageViews | Tous les fichiers |
|
Jour | 2015 |
|
| MediaRequests | Tous les fichiers |
|
Jour | 2015 |
|
| Commons Impact Metrics |
Collection préalablement signalée |
|
Mois | Date de signalement |
|
Le sous-chapitre précédent intitulé « Consultation des pages » présente les différents types d’agent utilisateur (utilisateur, robot d'indexation, trafic automatisé).
Plusieurs outils ont été mis en place afin de ne pas avoir à utiliser directement les API ou les dumps.
Outils de mesure de la consultation des médias
| Outil | Description | Données | Url |
|---|---|---|---|
| MediaViews | Comparaison des requêtes de médias entre plusieurs fichiers (10 fichiers max) | MediaRequests |
pageviews.wmcloud.org/mediaviews |
| Media Views in Category |
Nombre de requêtes des fichiers d'une catégorie et ses sous-catégories (500 fichiers max) |
MediaRequests | mvc.toolforge.org |
| BaGLAMa |
Nombre de vues mensuelles à partir d'une liste prédéterminée |
PageViews |
glamtools.toolforge.org/baglama2 |
| GLAMorgan | Nombre de vues mensuelles d'une catégorie et ses sous-catégories (30 000 fichiers max) |
PageViews | glamtools.toolforge.org/glamorgan.html |
| GLAM Wiki Dashboard |
Tableau de bord pour les collections institutionnelles |
PageViews |
glamwikidashboard.wmcloud.org |
| Commons Impact Metrics Dashboard (beta) | Tableau de bord | Commons Impact Metrics | tiago.bio.br/impact_metrics |
| Dynamic Collapsible Sections | Carnet Jupyter | Commons Impact Metrics | public-paws.wmcloud.org/User:Dominic/metrics.html |
| COM:VIEWS | Modèles Wikimedia Commons | Commons Impact Metrics | commons.wikimedia.org/wiki/Commons:VIEWS |
Commons Impact Metrics
Depuis 2024, Wikimedia Foundation propose un nouveau jeu de données afin de mesurer la consultation des fichiers. Il s'agit d'une mesure de la consultation des pages illustrées avec ces fichiers.
Pour des questions de performance, il faut préalablement demander l'ajout d'une collection afin que Wikimedia Foundation réalise les calculs une fois par mois. Une collection prend la forme d'une catégorie (ou d'une catégorie et ses sous-catégories) regroupant les fichiers à suivre. Voici la liste des statistiques générées chaque mois et la méthode pour faire une demande d'ajout à la liste. Une fois que la collection est ajoutée à la liste, il faut attendre qu'un nouveau jeu de donnée soit publié. Les données sont accessibles via API ou dumps. Il est possible de tester l'API via ce bac à sable.
Quelques caractéristiques et limites sont à avoir à l'esprit lors de l'utilisation de ces données :
- Monthly drift. Contrairement à MediaRequests, les données provenant de PageViews et Commons Impact Metrics ne prennent en compte la date d'ajout d'un fichier dans une page. Si un fichier est ajouté le 20 du mois, le trafic de l'ensemble du mois sera pris en compte. Wikimedia Foundation nomme ce problème "monthly drift".
- Pages d'accueil. À la différence de PageViews et MediaRequests, le trafic des pages d'accueil n'est pas pris en compte dans les données Commons Impact Metrics. Cela réduit le problème évoqué au point précédent.
- Plusieurs images par article. Si un article contient plusieurs images de la collection, la consultation de l'article ne sera comptabilisée qu'une seule fois.
- Modèles. Des illustrations sont insérées dans des messages placés sur plusieurs pages. Exemple : la palette Gouvernement Jospin est une boîte déroulante placée en pied de page de 44 articles dont certains sont très consultés. Cela gonfle les statistiques de la collection INRA de plusieurs centaines de milliers de vues.
- Sous-catégories : le rangement des fichiers dans des catégories et sous-catégories n'est pas parfait. Il n'est pas rare que des sous-catégories éloignées de la catégorie initiale comportent des fichiers n'appartenant pas à la collection. La profondeur de l'arbre est limitée à 7 niveaux, mais le paramètre
deepdoit être utilisé avec précaution.
API
| Description | Paramètre |
Réponse |
|---|---|---|
Indicateurs d'une collection : nombre de fichiers, fichiers utilisés, nombre de pages, nombre de wikis. category-metrics-snapshot |
category
|
timestamp
|
| Exemple : https://wikimedia.org/api/rest_v1/metrics/commons-analytics/category-metrics-snapshot/Gallica/20240101/20240501 | ||
Nombre de modifications par mois pour une collection donnée. edits-per-category-monthly |
category
|
edit-count
|
| Exemple : https://wikimedia.org/api/rest_v1/metrics/commons-analytics/edits-per-category-monthly/Gallica/deep/all-edit-types/20240101/20240501 | ||
Total du nombre de pages vues par mois pour une collection donnée. pageviews-per-category-monthly |
category
|
timestamp
|
| Exemple : https://wikimedia.org/api/rest_v1/metrics/commons-analytics/pageviews-per-category-monthly/Gallica/deep/fr.wikipedia/20240101/20240501 | ||
Classement des wikis les plus consultés pour une collection donnée. top-wikis-per-category-monthly |
category
|
wiki
|
| Exemple : https://wikimedia.org/api/rest_v1/metrics/commons-analytics/top-wikis-per-category-monthly/Gallica/deep/2024/05 | ||
Classement des pages les plus consultées pour une collection donnée. top-pages-per-category-monthly |
category
|
page-title
|
| Exemple : https://wikimedia.org/api/rest_v1/metrics/commons-analytics/top-pages-per-category-monthly/Gallica/deep/fr.wikipedia/2024/05 | ||
Classement des contributeurs ayant le plus de modifications pour une collection donnée. top-editors-monthly |
category
|
user-name
|
| Exemple : https://wikimedia.org/api/rest_v1/metrics/commons-analytics/top-editors-monthly/Gallica/deep/all-edit-types/2024/05 | ||
Indicateurs d'une collection : nombre de pages, nombre de wikis. media-file-metrics-snapshot |
media-file |
timestamp
|
| Exemple : https://wikimedia.org/api/rest_v1/metrics/commons-analytics/media-file-metrics-snapshot/Dvorak.jpg/20240101/20240501 | ||
Nombre de vues pour un fichier donné. pageviews-per-media-file-monthly |
media-file
|
timestamp
|
| Exemple : https://wikimedia.org/api/rest_v1/metrics/commons-analytics/pageviews-per-media-file-monthly/Dvorak.jpg/fr.wikipedia/20240101/20240501 | ||
Classement des fichiers les plus consultés. top-viewed-media-files-monthly |
category
|
media-file
|
| Exemple : https://wikimedia.org/api/rest_v1/metrics/commons-analytics/top-viewed-media-files-monthly/Gallica/deep/all-wikis/2024/05 | ||
Classement des wikis les plus consultés pour un fichier donné. top-wikis-per-media-file-monthly |
media-file
|
wiki
|
| Exemple : http://wikimedia.org/api/rest_v1/metrics/commons-analytics/top-wikis-per-media-file-monthly/Dvorak.jpg/2024/05 | ||
Classement des pages les plus consultées pour un fichier donné. top-pages-per-media-file-monthly |
media-filewiki
yearmonth
|
page-title
|
| Exemple : https://wikimedia.org/api/rest_v1/metrics/commons-analytics/top-pages-per-media-file-monthly/Dvorak.jpg/fr.wikipedia/2024/05 | ||
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Paramètres de la requête
category: nom d'une catégorie de Wikimedia Commons figurant dans la liste blanchecategory-scope: la catégorie uniquement (shallow) ou la catégorie et ses sous-catégories (deep). La profondeur de l'arbre est limitée à 7 niveaux.edit-type: type de modification : création (create), mise à jour (update) ou les deux (all-edit-types)media-file: nom d'un fichier se trouvant dans les collections de la liste blanche (sansFile:, avec extension)user-name: nom d'utilisateurwiki: un seul wiki (ex.fr.wikipedia,fr.wikisource) ou tous les wikis (all-wikis)start: premier mois (formatYYYYMM01)end: dernier mois (formatYYYYMM01)month: mois (formatMM)year: année (formatYYYY)
Réponses de la requête
-
edit-count: nombre de modification d'un contributeur ou des fichiers appartenant à une collection. -
media-file-count: nombre de fichiers de la collection (catégorie principale uniquement). -
media-file-count-deep: nombre de fichiers de la collection (catégorie principale et ses sous-catégories). -
used-media-file-count: nombre de fichiers de la collection (catégorie principale uniquement) réutilisés. -
used-media-file-count-deep: nombre de fichiers de la collection (catégorie principale et ses sous-catégories) réutilisés. -
leveraging-wiki-count: nombre de wikis réutilisant les fichiers de la collection (catégorie principale uniquement). -
leveraging-wiki-count-deep: nombre de wikis réutilisant les fichiers de la collection (catégorie principale et ses sous-catégories). -
leveraging-page-count: nombre de pages réutilisant les fichiers de la collection (catégorie uniquement). -
leveraging-page-count-deep: nombre de pages réutilisant les fichiers de la collection (catégorie principale et ses sous-catégories). -
page-title: titre des pages réutilisant des fichiers de la collection (limité à l'espace de nom principal : namespace=0). -
pageview-count: nombre de vues des pages.
3.3. Appareils uniques
Le nombre de visiteurs uniques est un indicateur très répandu pour mesurer la fréquentation d'un site Internet. Le mouvement Wikimedia est un des rares grands acteurs du Web à ne pas mesurer cela afin de protéger la vie privée des utilisateurs. À la place, la fondation mesure le nombre d'appareils uniques qui servent à consulter ses wikis.
Cas pratique : visiteurs uniques dans l'Union européenne
Le règlement européen sur les services numériques Digital Services Act prévoit que les hébergeurs communiquent à la Commission européenne le nombre de visiteurs uniques afin notamment de vérifier si elles dépassent ou non le seuil de 45 millions de visiteurs uniques par mois, ce qui en fait une très grande plateforme en ligne devant faire face à plus d'obligations. Pour satisfaire cette obligation, Wikimedia Foundation se base sur une étude de Cisco estimant à 2,4 le nombre moyen d'appareils utilisés par chaque personne pour consulter Internet.
Voici ci-contre l'estimation de la moyenne mensuelle du nombre de visiteurs uniques dans l'Union européenne.
| Wiki | Août 2022 à janvier | Février 2023 à juillet |
|---|---|---|
| Wikipedia | 151 556 000 | 151 088 000 |
| Wiktionary | 8 955 000 |
8 425 000 |
| Wikimedia Commons |
2 845 000 | 8 425 000 |
| Wikisource | 7 106 000 | 1 845 000 |
| Wikibooks | 6 919 000 | 1 611 000 |
| Wikiquote | 6 811 000 | 1 548 000 |
| Wikiversity | 6 360 000 | 1 082 000 |
| Wiidata | 1 056 000 | 1 051 000 |
| Wikinews | 9 283 000 | 1 035 000 |
| Wikivoyage | 616 000 | 632 000 |
| Wikspecies | 29 000 | 37 000 |
3.4. Flux de clics
https://fr.wikipedia.org/wiki/Wikipédia:Accueil_principal) contrairement au choix fait sur l'encyclopédie en anglais (https://en.wikipedia.org/wiki/Main_Page). 3.5. Données technologiques
Il est possible de consulter les données concernant les navigateurs et systèmes d'exploitation utilisés par les visiteurs des wikis de Wikimedia Foundation. Les données remontent à 2015 et sont publiées sous la mention Creative Commons CC0. Ces données permettent par exemple d'étudier le déploiement des nouvelles versions des navigateurs.
4. Corpus
Les sites Internet de Wikimedia Foundation stockent du contenu sous licence libre ou dans le domaine public. Wikipedia est conçue pour être réutilisée et diffusée ; c'est en cela qu'elle est une encyclopédie « libre ». Voici les recommandations de Wikipedia en matière de réutilisation du contenu :
Pour la réutilisation, la copie ou la modification de tout ou partie du texte d'un article, il faut veiller à :
-
indiquer que le contenu réutilisé, copié ou modifié est publié sous CC-BY-SA-4.0,
-
permettre l'identification des auteurs en donnant une adresse web vers l'article de Wikipedia, ou en donnant une liste des auteurs (paternité),
-
indiquer les modifications réalisées sur le contenu original de Wikipedia,
-
laisser tous les travaux dérivés sous la même licence (partage à l'identique).
4.1. Wikipedia
Contenu techniquement réutilisable
Dumps de données
"dumps wikipedia " OR "wikipedia dumps". Exemples de réutilisation du contenu de Wikipedia (Nielsen, 2018) :- Enriching Word Vectors with Subword Information (Bojanowski et al., 2016),
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (Devlin et al., 2018),
- Overcoming the brittleness bottleneck using Wikipedia: enhancing text categorization with encyclopedic knowledge (Gabrilovich et Markovitch, 2006),
- Open semantic analysis: The case of word level semantics in Danish (Nielsen et Hansen, 2017).
Dumps XML
| Nom du fichier |
Taille | |
|---|---|---|
| frwiki-20231020-pages-articles-multistream1.xml-p1p306134.bz2 | 594,9 Mo | |
| frwiki-20231020-pages-meta-current.xml.bz2 | 7,9 Go | |
| frwiki-20231020-stub-meta-history.xml.gz | 14,0 Go | |
| frwiki-20231101-stub-meta-current1.xml.gz | 20,9 Mo |
|
|
|
|
|
Uniquement les pages dans l'espace principal (articles encyclopédiques pour Wikipedia). Disponible au format de compression bz. Généralement disponible avec |
|
|
Pages dans tous les espaces de nom. |
|
|
Métadonnées sans le contenu des pages, tels que les titres des pages, les modèles de contenu, les identifiants des pages et des révisions, noms d'utilisateurs et espaces de nom, horodatages et résumés de modification. Disponible au format gzip. |
|
|
Comprend le contenu de la page et les métadonnées. |
|
|
La dernière révision uniquement. |
|
|
Intégralité de l'historique de révision des pages, pour les informations sur les auteurs. |
Fichiers XML
siteinfo et l'objet page, chacun ayant de multiples objets associés, champs et attributs.siteinfo
dbname: le nom de la base de donnéesitename: le nom du projet Wikimedia concernébase: le lien vers la page d'accueil du wikigenerator: la version de MediaWiki au moment de la génération du dumpcase: indique si la première lettre du titre d'une page est sensible à la casse (case-sensitive) ou non (first-letter). Contrairement à Wikipedia, le Wiktionnaire distingue les pages Bac et bac.
page
id: identifiant unique au sein du wiki concernétitle: nom de la pagens: espace de nom dans lequel figure la pageredirect: apparait lorsque la page est une redirection
revision
id: identifiant de la révisionparentid: identifiant de la précédente révisiontimestamp: date de publication de la révisioncontributor: information sur l'utilisateur qui a publié la révisionminor: révision qualifiée de mineur ou non par l'utilisateurcomment: commentaire de modification laissé par l'utilisateurmodel: modèle (wikitext,JavaScript,CSS,plain textouJSON)format: format de sérialisation (text/plain,text/x-wiki,text/javascript,application/jsonoutext/css)text: le contenu de la page en wikitextesha1: identifiant de vérification généré par l'algorithme SHA-1

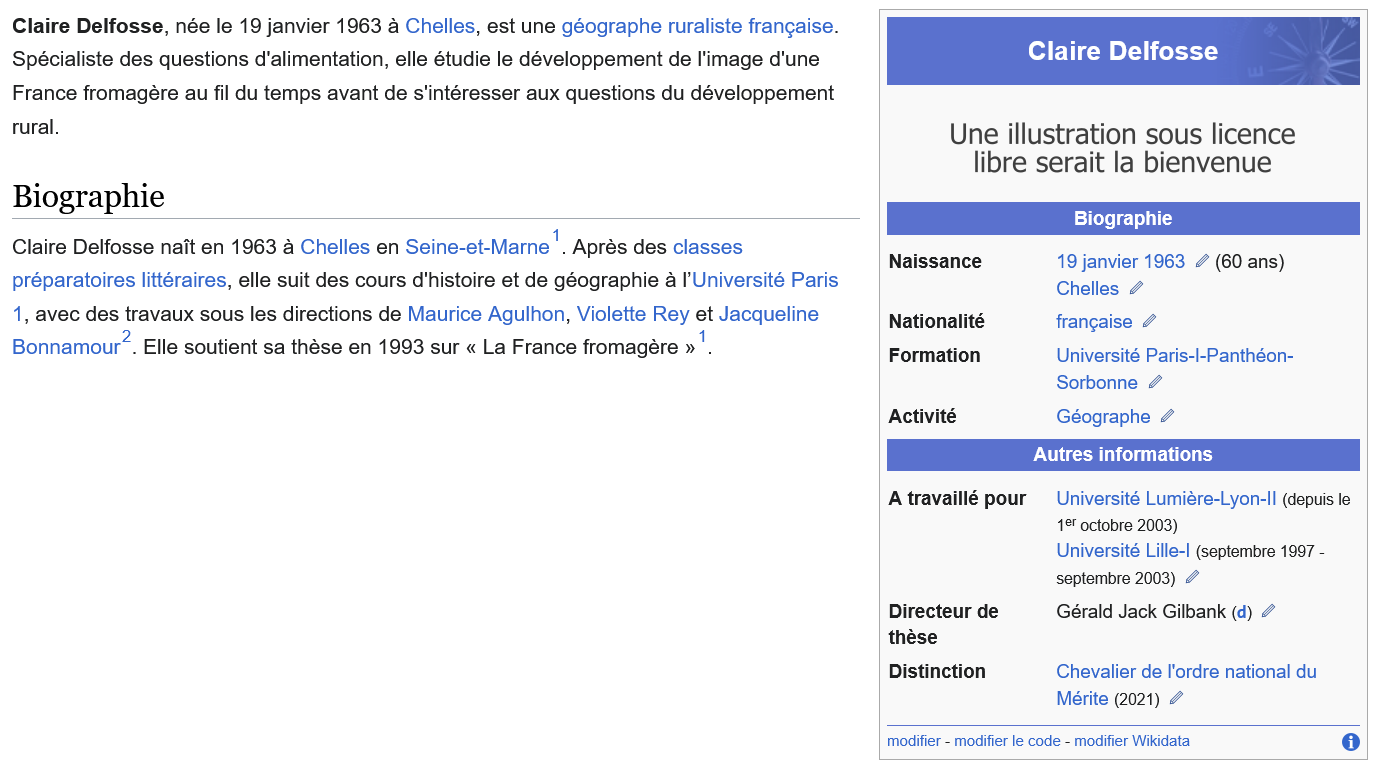
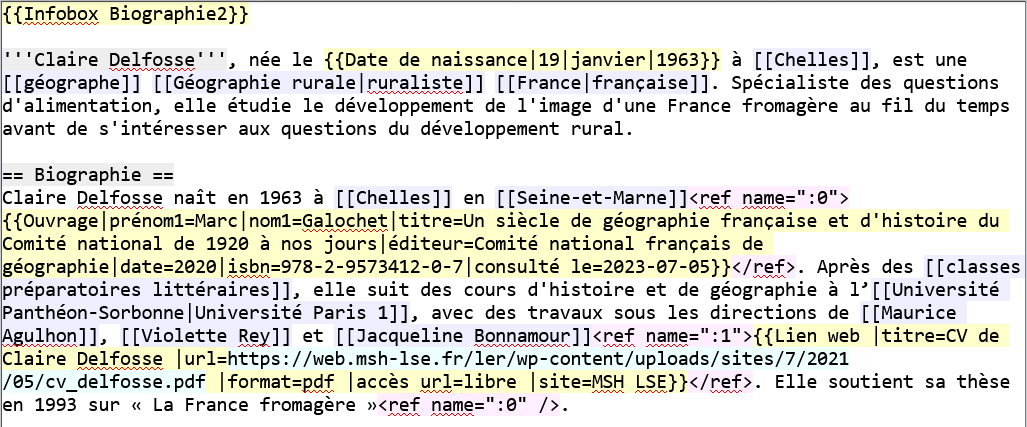
Wikitexte versus HTML
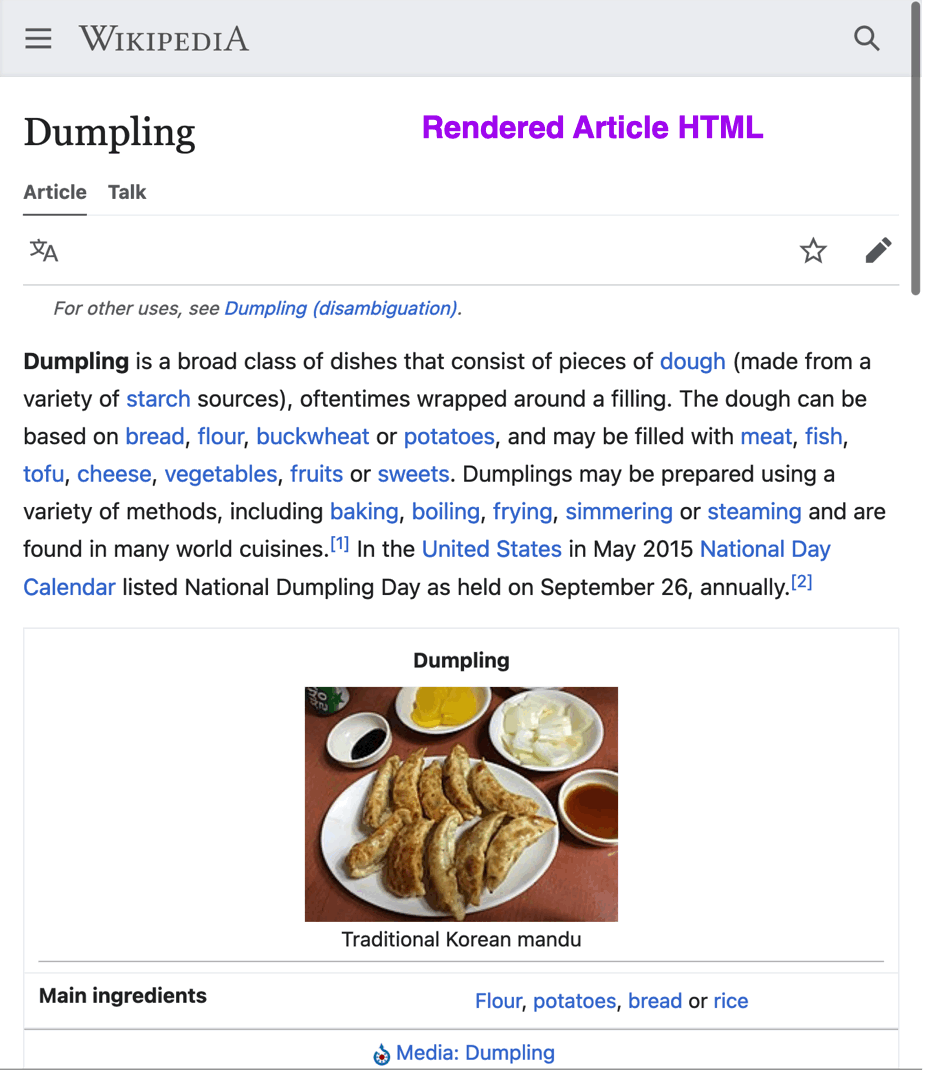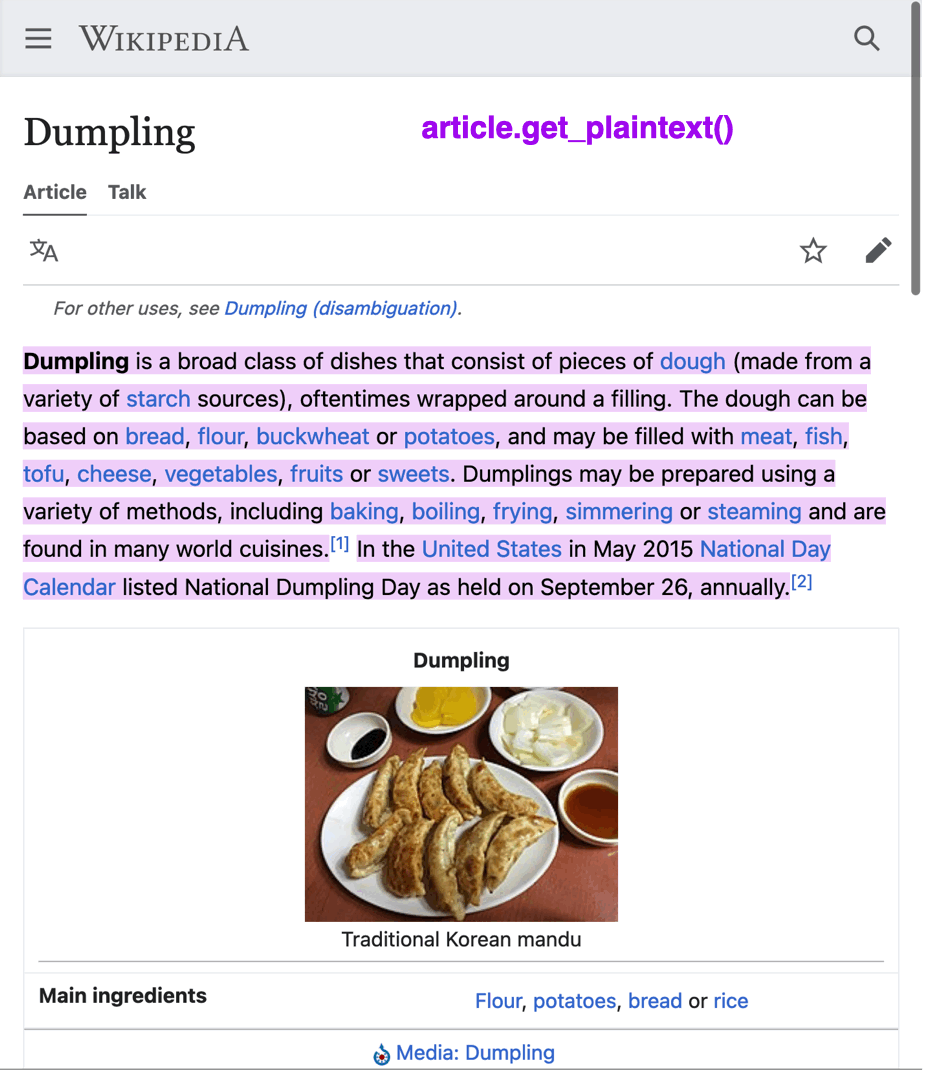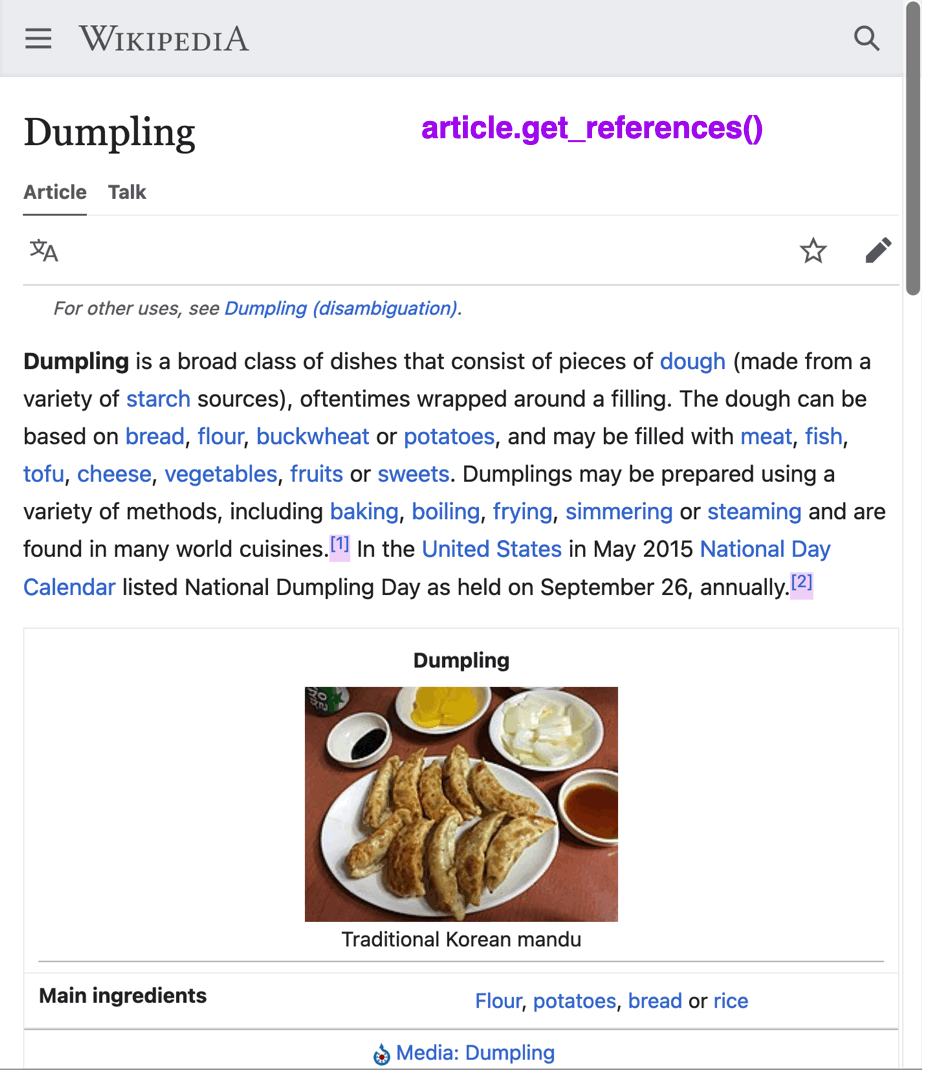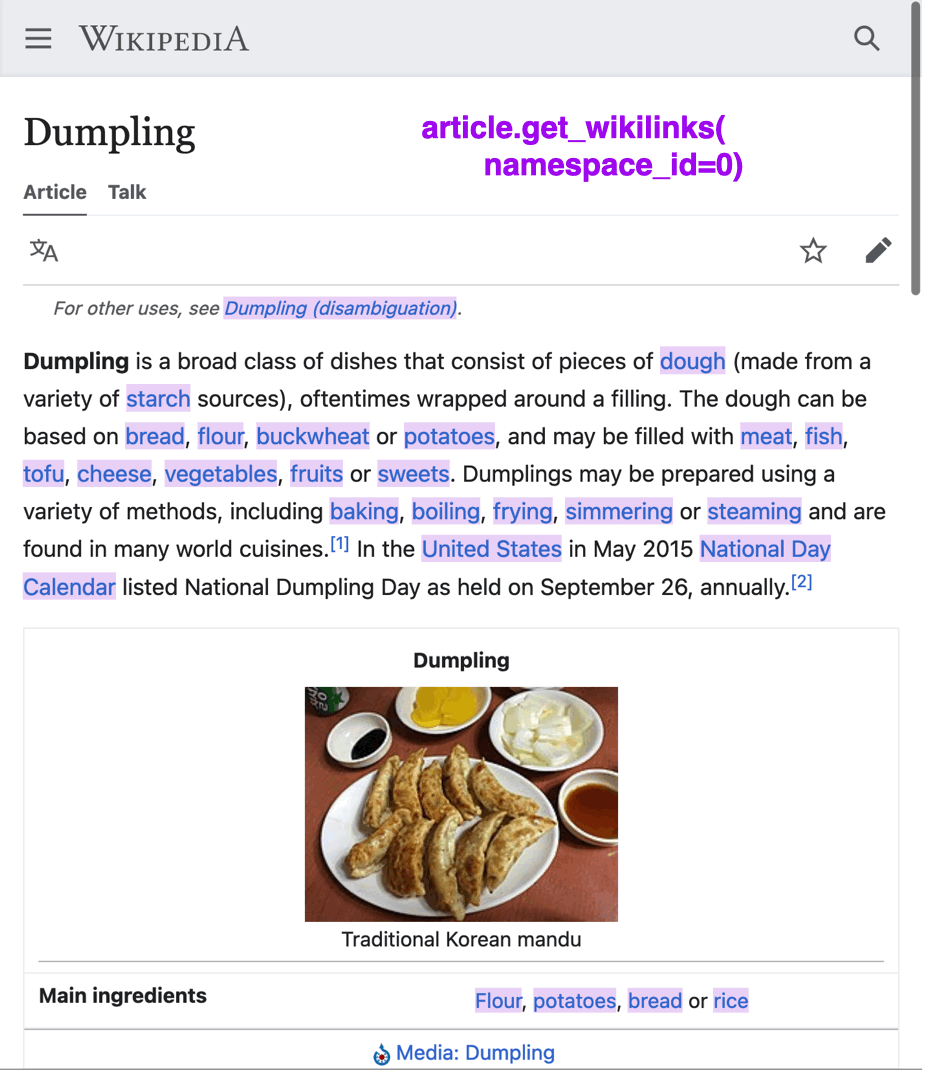
Dumps HTML
Depuis octobre 2021, Wikimedia Entreprise, une filiale de Wikimedia Foundation, met à dispositon gratuitement des dumps au format HTML afin de faciliter l'utilisation des dumps.
Ce jeu de données s'accompagne d'une librairie Python mwparserfromhtml qui permet d'extraire facilement des données (liens internes, liens externes, catégories, modèles, etc) des articles en HTML.
4.2. Wikidata
Objectif de Wikidata
I have a dream for the Web [in which computers] become capable of analyzing all the data on the Web – the content, links, and transactions between people and computers. A "Semantic Web", which makes this possible, has yet to emerge, but when it does, the day-to-day mechanisms of trade, bureaucracy and our daily lives will be handled by machines talking to machines. The "intelligent agents" people have touted for ages will finally materialize.
J’ai fait un rêve pour le Web [dans lequel les ordinateurs] deviennent capables d’analyser toutes les données sur le Web — le contenu, liens, et les transactions entre les personnes et les ordinateurs. Un « Web Sémantique », qui devrait rendre cela possible, n’a pas encore émergé, mais quand ce sera fait, les mécanismes plan-plan d’échange, de bureaucratie et de nos vies quotidiennes seront traités par des machines dialoguant avec d’autres machines. Les « agents intelligents » qu’on nous promet depuis longtemps vont enfin se concrétiser.
Depuis son lancement en 2012, Wikidata contenait principalement des concepts : les éléments Q sont liés à une chose ou une idée, pas au mot qui le décrit. Depuis 2018, Wikidata stocke un nouveau type de données : des mots, des locutions et des phrases. Ces informations sont stockées dans de nouveaux types d'entités, appelés lexèmes (L), formes (F) et sens (S). Wikidata comporte plus de 650 000 lexèmes. Pour en savoir plus sur le modèle de données, reportez-vous à la page de documentation.
Licence des données
Format des données
Exemples
5. Métadonnées
En plus du contenu, de nombreuses métadonnées sont mises à disposition.
Dumps XML
pages-logging |
Journaux, dont les blocages, protections, suppressions, imports |
Dumps SQL
|
|
Identifiants des pages et leurs catégories |
|
|
Toutes les catégories avec le nombre de pages, sous-pages et fichiers qu'elles contiennent |
|
|
Toutes les balises de modification |
|
|
Identifiant des pages et les liens externes qu'elles contiennent |
|
|
Identifiant des pages et la dernière révision stable (extension MediaWiki déployée sur quelques wikis) |
|
|
Identifiant des révisions et information concernant le relecteur (extension MediaWiki déployée sur quelques wikis) |
|
|
Coordonnées géographiques figurant dans les pages |
|
|
Information au sujet des fichiers importés |
|
|
Identifiant de la page et les liens vers les fichiers média |
|
|
Identifiant de la page et les liens vers les autres wikis |
|
|
Identifiant de la page et les équivalents dans les autres wikis |
|
|
Information sur la page : espace de nom, titre, dernière révision, etc. |
|
|
Liens vers d'autres pages du wiki |
|
|
Clé primaire d'identification unique des pages |
|
|
Pages protégées |
|
|
Titres dont la page ne peut être créée |
|
|
Liste de redirections et les pages de destination |
|
|
Information sur les wikis : code langue, type de projet, etc. |
|
|
Statistiques sur les wikis : pages vues, nombre de modifications, etc. |
|
|
Identifiant de la page et les modèles qu'elle contient |
|
|
Identifiant utilisateur et groupe auquel il appartient (administrateur, robot, etc.) |
|
|
Identifiants des éléments Wikidata et les pages du wiki qui s'en servent |
Sources : What's available for download et Dump format
6. Divers jeux de données
Wikimedia Foundation n'est pas le seul acteur à publier des données ouvertes concernant Wikimedia. Il existe de nombreux jeux de données publiés par des chercheurs sur les entrepôts de données. Voici une rapide présentation de quelques jeux de données spécifiques dont les données sont généralement tirées de Wikipedia et Wikidata.
6.1. Références bibliographiques
| Code | Wikipedia Citations 2020 |
Wikipedia Citations 2023 |
|---|
6.2. Personnes notables
| Documentation | Code | Données |
Dataviz | Podcast |
|---|
6.3. Liens Wikipédia sur Twitter
Twitter Wikipedia Link (TWikiL) est une base de données de liens menant vers Wikipedia mentionnés sur Twitter entre mars 2006 et janvier 2021. La version 1.0 du jeu de données mis à disposition par Florian Meier est constitué de deux ensembles de données :
TWikiL rawcomporte tous les tweets renvoyant vers Wikipedia, soit 44 millions tweets.
TWikiL curatedne comporte que les liens renvoyant à des articles, soit 35 millions de tweets. Il n'y figure pas les tweets mentionnant les pages en dehors de l'espace principal (historique, page de discussion, espace utilisateur) ni vers la page d'accueil des différentes versions linguistiques de Wikipedia.
6.4. Enquête sur les usages de Wikipedia
En 2023, six chercheurs ont réalisé une enquête sur l'usage de l'encyclopédie dans 8 versions linguistiques de Wikipedia. Les données ont été collectées à l'aide d'un questionnaire en ligne entre juin et juillet. Le lien vers le questionnaire a été distribué via une bannière publiée affichée aux lecteurs et rédacteurs du site. Parmi les 200 questions, les internautes devaient indiquer ce qu'ils étaient en train de faire sur Wikipedia avant d'ouvrir le questionnaire ; comment ils utilisent Wikipedia en tant que lecteurs ; leur opinion sur la qualité du contenu, la couverture thématique, l'importance de l'encyclopédie, etc. Plus de 200 000 personnes ont ouvert le questionnaire, 100 332 ont commencé à y répondre et 10 576 sont allés jusqu'au bout. Le jeu de données a été déposé sur Nakala sous la licence libre Creative Commons Attribution Share Alike 4.0 International (CC-BY-SA-4.0).
Vikidia, l'encyclopédie des 8-13 ans, a également fait récemment l'objet d'une enquête par Wikimedia France et Datactivist. Le jeu de données a été déposé sur data.gouv.fr sous la licence CC0.
7. Bonnes pratiques de réutilisation des données
Comment réutiliser les éthiquement les données d'un communs numérique ? Les données Wikimedia sont utilisables gratuitement mais voici une liste de bonnes pratiques.
Bonnes pratiques d’accès aux données
Veiller à avoir un usage raisonné des ressources serveurs. Pour cela, il faut sélectionner la méthode d'accès aux données la plus rapide et la plus efficiente possible, sans exiger plus de ressources que nécessaire des serveurs. Voici quelques règles à respecter :
- Respecter la politique de l'agent utilisateur (utilisation d'un en-tête User-Agent conforme).
- Respecter la politique qui s'applique aux robots (
Accept-Encoding: gzip,deflate, pas trop de requêtes simultanées). - Respecter les bonnes pratiques en matière d'API (utilisation du paramètre
maxlag). - En cas d'erreur
429 Too Many Requests, arrêtez de faire des requêtes pendant un moment (consultez l'en-tête de réponseRetry-Afterafin de savoir combien de temps).
Bonnes pratiques d’utilisations aux données
- Respectez la licence du contenu, le droit des marques.
- Donnez quelque chose en retour :
- Visibilité et publicité afin que plus de gens connaissent les données ou le wiki utilisé.
- Participez à l'amélioration des données en partageant vos processus internes de gestion de la qualité des données.
- Participez à l'entretien des données. Garder un œil sur les changements apportés aux données.
- Partagez votre expertise.
- Partagez vos retours d'expérience sur ce qui fonctionne ou ne fonctionne pas bien.
- Soutenez financièrement le mouvement Wikimédia.
- Visibilité et publicité afin que plus de gens connaissent les données ou le wiki utilisé.
- Indiquez l'origine des données. Voici quelques exemples concernant Wikidata : « Propulsé par Wikidata », « Powered by Wikidata », « Utilise des données provenant de Wikidata », « Source : Wikidata », « Origine des données : Wikidata », ou à l'aide d'une image.
- Signalez les erreurs :
- Petite échelle : signalement sur le wiki.
- Grande échelle : publication d'un rapport.
- Corrigez les erreurs. Cela profitera à tout le monde.
- Présentez-vous sur votre utilisateur ainsi que vos travaux.
- Signalement obligatoire des conflits d'intérêts (exigé par les conditions générales d'utilisation.)
- Participez aux discussions qui peuvent vous impacter.
- Déployez votre propre infrastructure si vous avez de très gros besoins. Les gros réutilisateurs doivent privilégier les dumps ou le flux de modifications récents.