Définitions
Résumé de section
-
Dans cette partie nous verrons les types de métadonnées et les concepts associés indispensables pour gérer des références bibliographiques.
Temps estimé : 20 minutes
-
Qu'est-ce qu'une métadonnée ?
Imaginons que vous tenez un livre dans vos mains. Le contenu du livre, l'histoire elle-même, ce sont les informations. Mais sur la couverture et les premières pages, vous pouvez trouver :
- Le titre
- L'auteur
- La date de publication
- L'éditeur
- L'ISBN
- Le nombre de pages
- Le genre littéraire
Ces informations qui décrivent le livre sont des métadonnées. Ce sont des "données sur les données" : elles nous renseignent sur le contenu sans être le contenu lui-même.

Christa Jungnickel and Russell McCormmach, Public domain, via Wikimedia Commons
-
Les métadonnées numériques
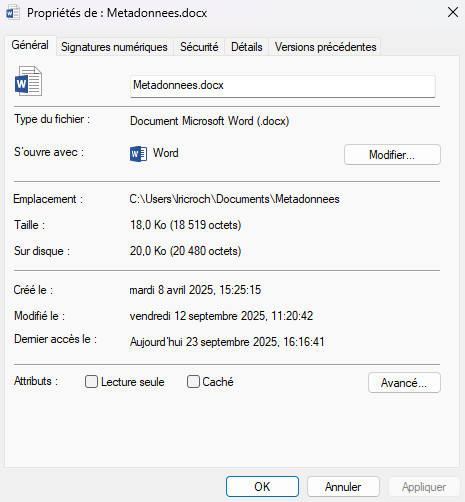
Cette logique se retrouve également dans nos fichiers informatiques. Prenez un fichier quelconque sur votre ordinateur :
- Son nom
- Sa taille
- Sa date de création
- Son format
- Son emplacement
- Etc.
Toutes ces informations sont des métadonnées. Elles nous permettent de comprendre, organiser et retrouver ce fichier.
-
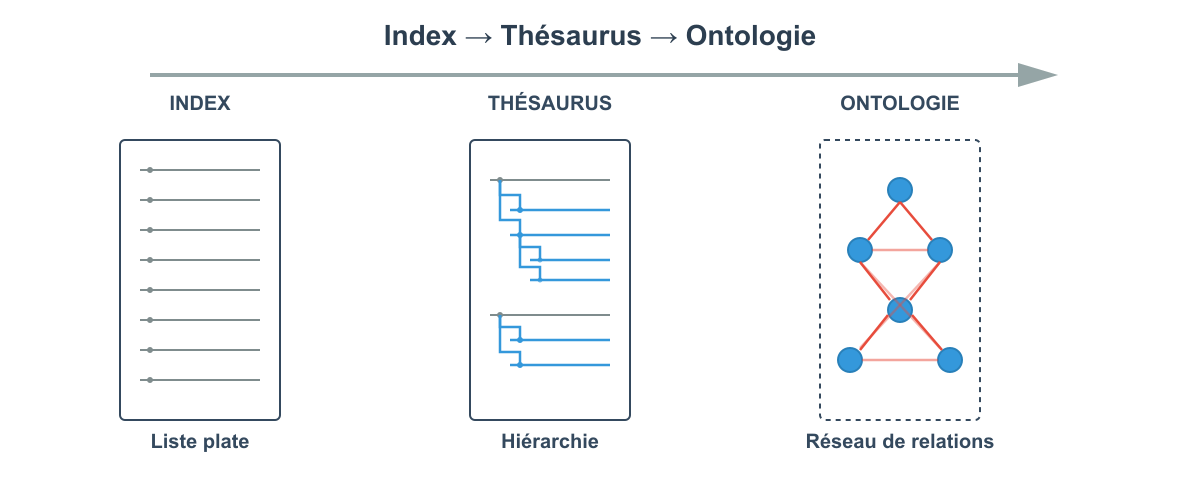
Pour bien comprendre la différence entre index, thésaurus et ontologie, rappelons quelques points :

Index
Un index est essentiellement un outil de localisation qui référence où trouver des informations spécifiques dans une collection. Il établit une correspondance directe entre des termes (mots-clés, concepts, noms propres) et leur localisation dans les documents.
L'index ne modélise pas les relations sémantiques entre concepts : il se contente de pointer vers les occurrences en s'appuyant sur les termes présents dans le thésaurus.
La liste des termes
"La liste de termes est le vocabulaire contrôlé le plus simple. Il s'agit d'un ensemble de mots permettant de décrire un contenu. Une liste de termes peut avoir 2 niveaux de structuration :
- Aucune structuration : une suite de mots constituant le champ lexical d'une thématique. Par exemple, "four", "réfrigérateur", "table", "plan de travail", "vaisselle" décrivent différents éléments de la cuisine, mais ne sont pas structurés entre eux.
- Structuration logique : nous pouvons citer les classements géographiques, alphabétiques ou chronologiques. Par exemple, la liste des départements français sont classés dans l'ordre alphabétique. La liste des planètes du système solaire est construite en fonction de leur distance par rapport au Soleil."
-

Thésaurus
Un thésaurus est un vocabulaire contrôlé qui organise les termes selon des relations sémantiques hiérarchiques et associatives. Il établit des liens entre concepts synonymes, plus généraux (termes génériques), plus spécifiques (termes spécifiques) ou simplement reliés (termes associés). Son objectif principal est de normaliser le vocabulaire pour l'indexation et la recherche documentaire, en proposant un langage documentaire unifié.
Pour aller plus loin
"Les bibliothécaires ont développé le concept de thésaurus, qui complète une taxonomie par des relations de similarité et de synonymes entre les termes. Cela signifie qu'ont été ajoutées d'autres dimensions orthogonales à la simple relation de subordination d'une hiérarchie. Alors que les taxonomies ne présentent qu'une structuration arborescente des termes utilisés, les thésaurus peuvent représenter une collection de descripteurs dans un graphe.
Nous reprenons la définition proposée par Rennesson et al. :
"Un thésaurus est une liste organisée de termes contrôlés et normalisés appelés descripteurs représentant les concepts d'un domaine de connaissance. Les descripteurs sont reliés entre eux par des relations hiérarchiques (terme générique TG, terme spécifique TS), des relations de synonymie (employé pour EP, correspond aux termes rejetés dits "non-descripteurs") et d'association (terme associé TA)." (Rennesson et al. 2019)
Chaque concept peut être sémantiquement lié dans le thésaurus en suivant trois correspondances possibles : un concept donné peut avoir une relation plus large, plus étroite ou associative avec d'autres concepts. Dans un même thésaurus, un certain nombre de micro-thésaurus peuvent être définis. Enfin, les thésaurus peuvent être liés par l'alignement de concepts spécifiques de chacun d'eux.
Il existe différentes normes pour élaborer un thésaurus (AFNOR, ISO, ANSI/NISO). L'ISO 25964 est la norme internationale pour les thésaurus. L'objectif de cette norme concerne les thésaurus destinés à prendre en charge la recherche d'information, et plus particulièrement à guider le choix des termes utilisés dans les requêtes d'indexation, de balisage et de recherche. Elle est publiée en deux parties comme suit : ISO 25964 Information and documentation - Thesauri and interoperability with other vocabularies
- Part 1: Thesauri for information retrieval [published August 2011]
- Part 2: Interoperability with other vocabularies [published March 2013]. Nous évoquons cette partie dans la section Alignement des référentiels."
-

Ontologie
Une ontologie va bien au-delà du thésaurus en modélisant formellement un domaine de connaissance. Elle définit non seulement les concepts et leurs relations, mais aussi les propriétés, les contraintes et les règles logiques qui régissent ce domaine. Exprimée dans des langages formels (comme OWL), elle permet le raisonnement automatisé, l'inférence de nouvelles connaissances et l'interopérabilité sémantique entre systèmes. C'est une représentation computationnelle de la connaissance.
Pour aller plus loin
"Nous reprenons la définition proposée par INRAE (2020) :
"Une ontologie cherche à décrire de façon formelle un domaine de connaissances, en identifiant les types d'objets de ce domaine, leurs propriétés et leurs relations. Les ontologies contiennent des classes, des propriétés, et des règles logiques formelles, éventuellement des instances de classe. Les types de relations utilisées sont :
- Inclusion (classe / sous-classe) ;
- Opérations ensemblistes : union, intersection, exclusion ;
- Caractéristiques des propriétés : domaine, ensemble d'arrivée, transitivité, propriétés inverses, etc.
- Toute relation spécifique au domaine définie formellement par l'auteur à partir des 3 propriétés précédentes.""
-
En résumé
L'index localise, le thésaurus structure le vocabulaire, et l'ontologie modélise formellement la connaissance d'un domaine.
Dans la pratique privilégiez le standard de métadonnées disponible dans votre discipline car cette option assure une homogénéité des termes utilisés. En l'absence de standard, optez pour un schéma de métadonnées s'il en existe dans votre domaine car c'est le modèle le plus exploitable pour les autres, ainsi que le plus complet en termes de structuration des données. Dans le cas contraire, vous pouvez vous rabattre sur un index. Enfin, vous pouvez avoir recours à la création de métadonnées s'il n'existe aucun modèle à disposition.