La diffusion des données de recherche en linguistique
Aperçu des sections
-
-
Bienvenue dans ce parcours destiné aux doctorants et chercheurs en linguistique qui souhaitent découvrir et comprendre pourquoi, comment et quelles données de recherche diffuser en linguistique.
Ce parcours a été pensé et conçu pour être suivi de façon linéaire et progressive, mais aussi de manière fragmentée. Vous pouvez consulter uniquement les parties qui vous intéressent.
Un sommaire s'affiche à la gauche de votre écran et vous permet de naviguer à votre convenance.
Bonne visite !
Si vous rencontrez des difficultés à ouvrir certains liens du cours, essayez de les ouvrir dans un autre navigateur.
Objectifs
- Identifier les enjeux liés à l’ouverture des données.
- Trier les données diffusables de celles non diffusables.
- Sélectionner les données à déposer.
- Choisir un entrepôt de données en linguistique adapté à ses besoins.
- Préparer le dépôt de ses données dans un entrepôt de données.

Ce cours est en libre accès !
Aucune création de compte ou d'inscription n'est nécessaire, toutefois vous pouvez vous inscrire à ce cours si vous le souhaitez.
S'inscrire au cours - Identifier les enjeux liés à l’ouverture des données.
-
-
-
Ce modèle est une extension du Dublin-Core : un standard de métadonnées générique très utilisé pour la description des données en Sciences Humaines et Sociales. Plus précisément, OLAC est une extension du modèle Dublin-Core qualifié (une version détaillée du Dublin-Core) auquel ont été ajoutés 5 attributs liés à des vocabulaires contrôlés qui permettent de décrire plus finement des ressources linguistiques.
Pour plus de détails, consulter la page CoCoOn sur les métadonnées.

Logo OLAC
-
Il s'agit de conventions de balisage de textes sous la forme élément/attribut, encodées en XML. Le schéma TEI possède une architecture évolutive qui accepte d'être enrichie d'éléments propres à un domaine particulier.
Pour plus de détails, consulter le site officiel de la TEI.

Logo TEI
-
Le CMDI permet la création et l'utilisation d'un schéma de métadonnées flexible et modulable. Il permet de sélectionner, parmi des standards existants, les métadonnées jugées pertinentes pour la description d'une ressource, voire d'en créer de nouvelles, et de les assembler dans un modèle appelé "profil". Chaque utilisateur obtient ainsi un profil au plus près des besoins spécifiques de description de ses ressources. Pour préserver l'interopérabilité, les utilisateurs sont invités à partager les profils ainsi créés dans le Registre des Composants
Pour plus de détails, consulter la page CMDI: Component Metadata Infrastructure du consortium CLARIN et le chapitre 2 (Métadonnées) du guide The Component Metadata Initiative (CMDI).
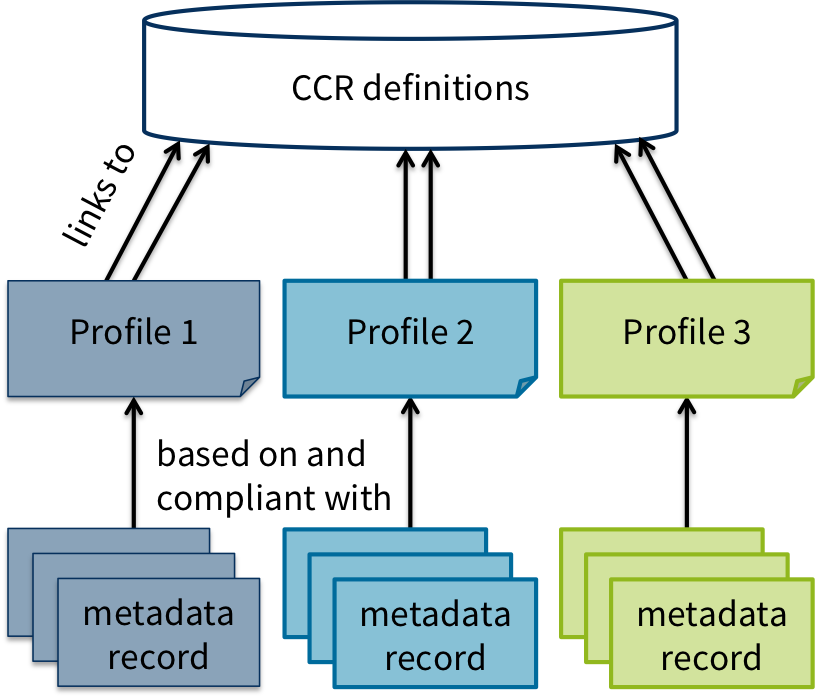
Schéma CMDI de CLARIN
-