
Les nouveaux défis à relever
Résumé de section
-
Les données biologiques sont souvent très volumineuses et complexes, et leur analyse nécessite des méthodes et des outils informatiques sophistiqués pour extraire des informations utiles. Elles sont aussi hétérogènes et proviennent de différentes sources, ce qui nécessite des méthodes pour les intégrer et les analyser de manière cohérente.
-
Avec l’avènement des nouvelles techniques de production de données en Biologie, deux phénomènes sont apparus :
- Un accroissement massif du volume des données à traiter, on parle de tsunami de données ou de datanami. L'article "Big data : Astronomical or Genomical ? " illustre le changement important de la production des données en Biologie. Les auteurs comparent les caractéristiques des données de l'Astronomie, Youtube, Twitter et de la Génomique. Ils arrivent à la conclusion que la Génomique présente des caractéristiques propres en ce qui concerne la production des données, leur stockage, leur distribution et leur analyse. Cela se traduit par une croissance explosive, répartie sur de multiples sites, et des besoins nouveaux pour le stockage, la diffusion et l'analyse des données.
- Le recours de plus en plus fréquent à l’outil informatique, étant donné que les données générées sont sous forme numérique, a un impact très important sur les pratiques des biologistes qui vont devoir développer une expertise additionnelle en Bio-informatique et en Informatique.

La Biologie et la Bio-Informatique doivent donc relever plusieurs défis depuis ces dernières années :
- La gestion efficace de cette masse de données ;
- L'intégration de ces données hétérogènes (données de type séquences, images, données d'expression, etc.) ;
- Le nombre croissant des outils d'analyse ;
- La mise en place de procédures efficaces pour une reproductibilité des traitements.
-
Accroissement de la quantité de données
Les statistiques des banques de données généralistes donnent une idée de la croissance des données en Biologie. Si l’on prend le cas de GenBank (figure ci-contre), on s’aperçoit qu’à partir des années 2002 démarre la production de génomes entiers (WGS: Whole Genome Shotgun).
Cette rupture est provoquée par l’apparition des séquenceurs de nouvelle génération qui vont modifier considérablement le paysage en Génomique et en Bio-Informatique. La Biologie était auparavant une discipline produisant assez peu de données. Depuis l'apparition des nouvelles techniques, il est possible de générer massivement des données sans avoir besoin de main d'œuvre supplémentaire. L’impact sur l’activité Bio-Informatique se fait sentir notamment en terme d’utilisation de ressources croissantes, qu’elles soient de calcul ou de stockage.
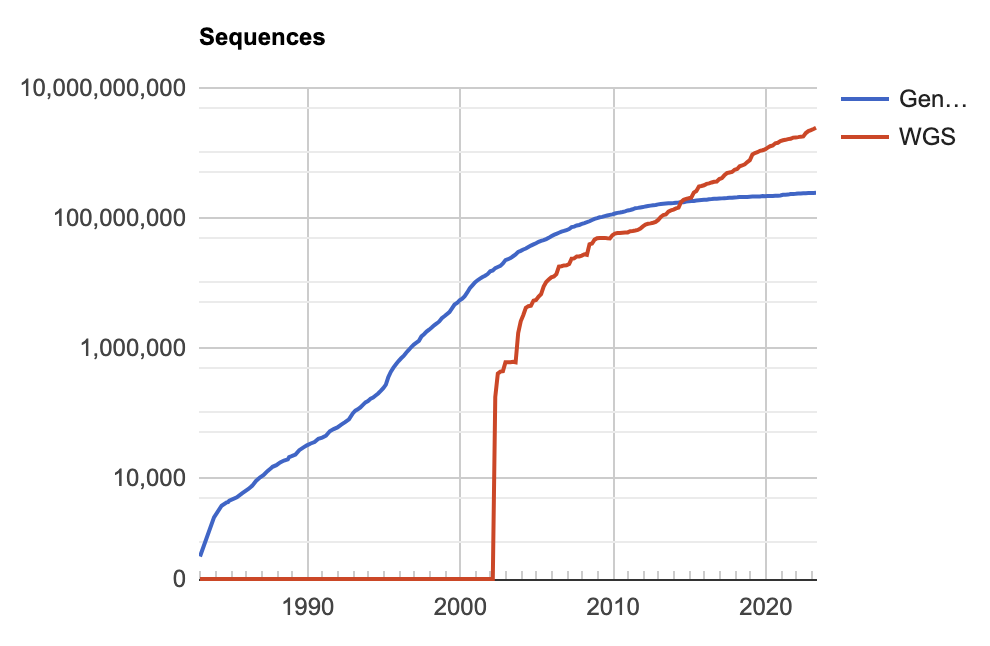
Accroissement du nombre de données disponibles sur GenBank. Source : statistiques de GenBank
-
L’accroissement des capacités de génération des données ne se manifeste pas qu’avec les techniques de séquençage puisque, dans bien des domaines, l’arrivée de nouvelles technologies ou bien de nouvelles pratiques d'ouverture des données (FAIR data, Science Ouverte) déclenche les mêmes phénomènes.
Le cas de la base EMDB (Electron Microscopy Data Bank) illustre ce phénomène comme le montre le graph ci-dessous.

Accroissement du nombre d'entrées de l'EMDB publiées par année et cumulées. Source : statistiques EMBD
-
L'adaptation des plateformes de Bio-Informatique
Les plates-formes Bio-Informatiques, occupant une place stratégique en tant que lieux de traitement de toutes ces données, sont des témoins privilégiés de cette évolution et doivent s’adapter pour accompagner au mieux les divers travaux de recherche. On constate que, depuis ces dernières années, les plates-formes Bio-Informatiques ouvertes aux communautés de recherche ont dû faire croître de manière importante leurs infrastructures pour accueillir des utilisateurs et utilisatrices toujours plus nombreux et dont les travaux d’analyses requièrent toujours plus de capacité de calcul et de stockage.
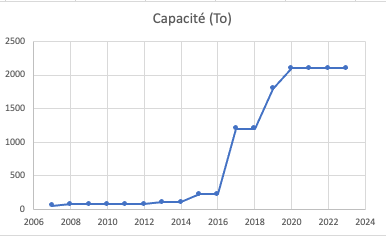
Accroissement de la capacité de stockage de la plate-forme Bio-informatique GenOuest, localisée à Rennes.
-
Hétérogénéité des données
La Biologie se caractérise par un grand nombre de types de données : séquences, motifs, graphes pour décrire les voies métaboliques ou les interactions, données quantitatives de suivi d'expression, données temporelles, images au contenu informationnel varié (résolution, traitements différents), informations spatiales et géographiques, modèles, données textuelles, etc.
Cette variété des données représente un défi en terme d'intégration pour les années à venir, d'autant plus que de nouvelles technologies de génération de données peuvent enrichir et compliquer ce paysage.
Pour aborder la question de l'hétérogénéité des données, on peut considérer à titre d'exemple la page dédiée aux ressources et aux outils de l'EBI (European Bioinformatics Institute).
En filtrant une recherche par "data resources", on a 63 résultats qui vont couvrir des catégories aussi diverses que de l'imagerie, des puces à ADN, des séquences...
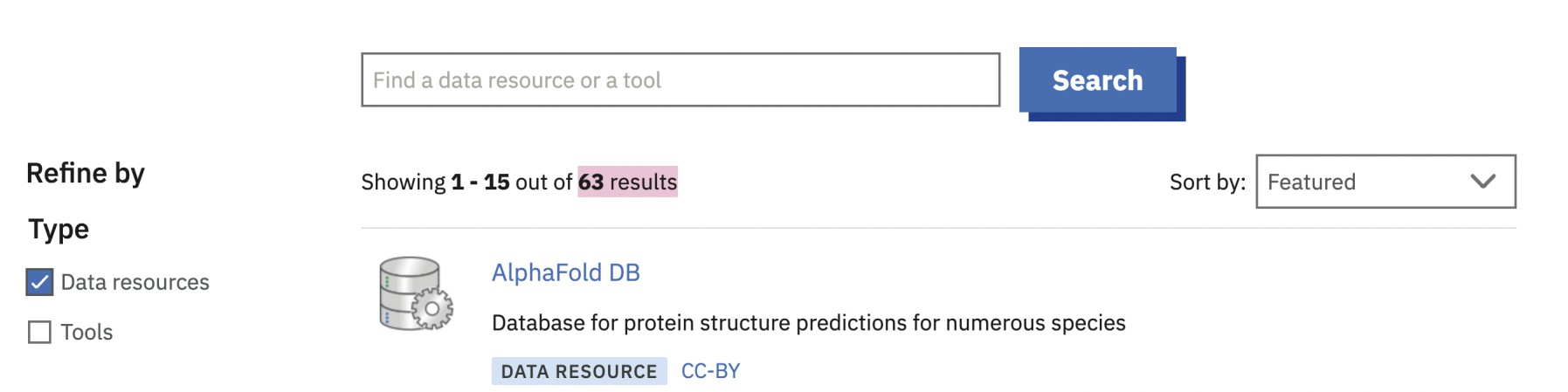
Tout cela complique de manière importante le travail du scientifique qui doit, à terme, intégrer / croiser les données pour pouvoir générer des informations significatives. Cette tâche est rendue plus complexe par le foisonnement de ressources à sa disposition. L'article annuel "NAR Database Issue" de la revue Nucleic Acids Research recense 1645 ressources dans sa 29ème édition publiée en décembre 2021.
-
Diversité des outils d'analyse
La diversité des outils d'analyse peut être traduite en considérant juste la page de bio.tools qui recense actuellement plus de 28 000 outils. Si l'on filtre notre recherche uniquement par le séquençage, on s'aperçoit qu'il y a environ 10 000 outils.
Cela signifie que les scientifiques sont amenés à un travail très important de sélection des outils afin d'identifier la ressource la plus adaptée à leur besoin. Le site bio.tools est d'ailleurs une solution à cette problématique puisqu'il permet de faire des recherches d'outils par catégorie.

28 190 outils au total sur bio.tools ( avril 2023)

10 749 outils dédiés à l'analyse de séquences sur bio.tools (avril 2023)
-
Abondance des données en Sciences de la Vie
Le graphe du LOD (Linked Open Data) présente les données publiques interconnectées grâce aux technologies du web sémantique. On constate que le domaine de la Biologie (entouré en rouge) est particulièrement bien représenté dans ce graphe avec un nombre important de ressources ouvertes et accessibles. Parmi les ressources disponibles, on peut citer :
- Les bases de données de référence (génomiques et protéiques) telles GenBank, UniProt, PDB (Protein Data Bank), KEGG (Kyoto Encyclopedia of Genes and Genomes), etc.
- Les bases de données d'expression génique comme GEO (Gene Expression Omnibus), ArrayExpress.
- Les bases de données des variations génétiques telles dbSMP (Single Nucleotide Polymorphism Database), GWAS Catalog (Genome Wide Association Studies).
- Les bases de référence des ontologies et des taxonomies comme GO, NCBI (National Center for Biotechnology Information).
Les bases de données en Sciences de la Vie se caractérisent par une connectivité importante (liens gris entre les ressources) qui devrait favoriser l'intégration des données.
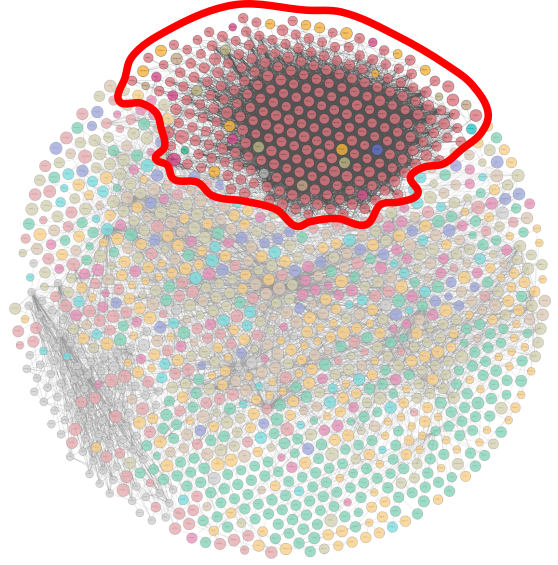
Visualisation des données interconnectées en sciences de la vie - source : The Linked Open Data
-

Bio
C'est au niveau de la couche métier de la Biologie que sont posées les questions et que sont générées les données. Avec les évolutions technologiques, les données sont le plus souvent sous format numérique et sont analysées avec les outils Bio-Informatiques.

Bio-Info
C'est au niveau de la couche métier Bio-Informatique que sont prises en charge les données pour être analysées avec l'ensemble des logiciels développées par la communauté, le plus souvent mis en œuvre au sein de workflows avant de délivrer les résultats qui vont permettre de répondre aux questions biologiques.
-
