La question des données en Bio-Informatique
Résumé de section
-
L'objectif de ce cours est de présenter les différentes étapes associées à la gestion de la donnée scientifique dans les champs de la Biologie et de la Bio-informatique. On abordera ces étapes sous l'angle technique tout en considérant les perspectives de science ouverte et de données FAIR qu'il est indispensable d'intégrer dans sa démarche.
En Bio-Informatique, les données sont indissociables des logiciels utilisés pour leur traitement et leur analyse.
Ce support brossera le paysage actuel en France, proposera des éléments de réflexion et fournira des pointeurs vers des ressources utiles ou indispensables. Certains points techniques, notamment concernant les aspects informatiques, seront rapidement abordés afin de permettre de disposer des clés d'analyse de la situation.
Objectifs
- Comprendre la question de la donnée en Sciences du Vivant.
- Avoir une vision d’ensemble du paysage des infrastructures dédiées à la donnée.
- Identifier les verrous technologiques.
- Obtenir des pistes concernant des solutions technologiques.

Ce cours est en libre accès !
Aucune création de compte ou d'inscription n'est nécessaire, toutefois vous ne pourrez le parcourir qu'en lecture seule.
Pour échanger sur le forum, vous devrez vous inscrire au cours.
S'inscrire au cours -
Les données biologiques sont souvent très volumineuses et complexes, et leur analyse nécessite des méthodes et des outils informatiques sophistiqués pour extraire des informations utiles. Elles sont aussi hétérogènes et proviennent de différentes sources, ce qui nécessite des méthodes pour les intégrer et les analyser de manière cohérente.
-
Avec l’avènement des nouvelles techniques de production de données en Biologie, deux phénomènes sont apparus :
- Un accroissement massif du volume des données à traiter, on parle de tsunami de données ou de datanami. L'article "Big data : Astronomical or Genomical ? " illustre le changement important de la production des données en Biologie. Les auteurs comparent les caractéristiques des données de l'Astronomie, Youtube, Twitter et de la Génomique. Ils arrivent à la conclusion que la Génomique présente des caractéristiques propres en ce qui concerne la production des données, leur stockage, leur distribution et leur analyse. Cela se traduit par une croissance explosive, répartie sur de multiples sites, et des besoins nouveaux pour le stockage, la diffusion et l'analyse des données.
- Le recours de plus en plus fréquent à l’outil informatique, étant donné que les données générées sont sous forme numérique, a un impact très important sur les pratiques des biologistes qui vont devoir développer une expertise additionnelle en Bio-informatique et en Informatique.

La Biologie et la Bio-Informatique doivent donc relever plusieurs défis depuis ces dernières années :
- La gestion efficace de cette masse de données ;
- L'intégration de ces données hétérogènes (données de type séquences, images, données d'expression, etc.) ;
- Le nombre croissant des outils d'analyse ;
- La mise en place de procédures efficaces pour une reproductibilité des traitements.
-
Accroissement de la quantité de données
Les statistiques des banques de données généralistes donnent une idée de la croissance des données en Biologie. Si l’on prend le cas de GenBank (figure ci-contre), on s’aperçoit qu’à partir des années 2002 démarre la production de génomes entiers (WGS: Whole Genome Shotgun).
Cette rupture est provoquée par l’apparition des séquenceurs de nouvelle génération qui vont modifier considérablement le paysage en Génomique et en Bio-Informatique. La Biologie était auparavant une discipline produisant assez peu de données. Depuis l'apparition des nouvelles techniques, il est possible de générer massivement des données sans avoir besoin de main d'œuvre supplémentaire. L’impact sur l’activité Bio-Informatique se fait sentir notamment en terme d’utilisation de ressources croissantes, qu’elles soient de calcul ou de stockage.
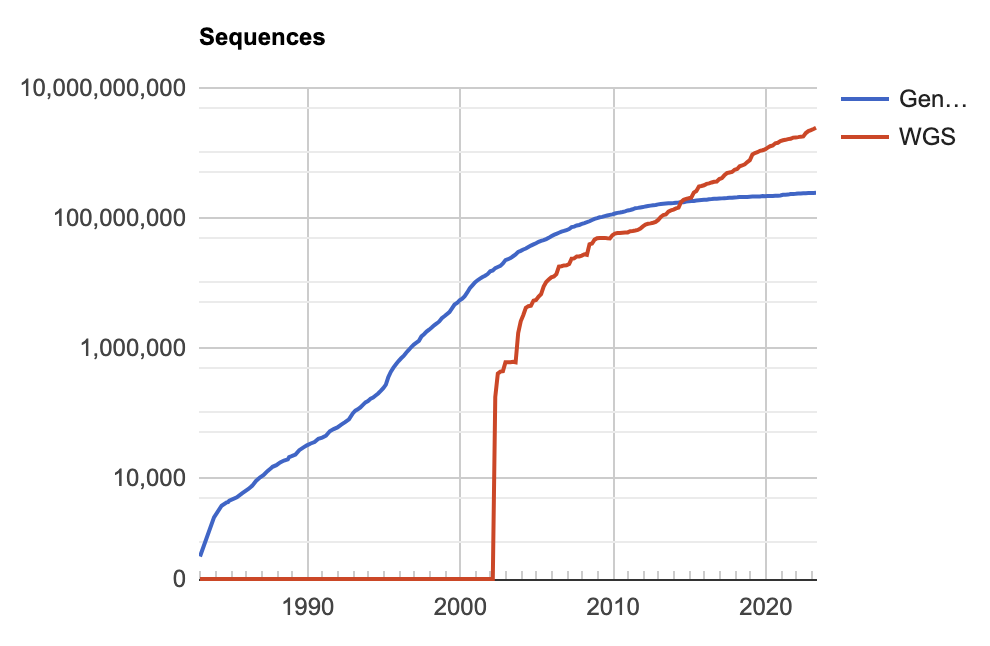
Accroissement du nombre de données disponibles sur GenBank. Source : statistiques de GenBank
-
L’accroissement des capacités de génération des données ne se manifeste pas qu’avec les techniques de séquençage puisque, dans bien des domaines, l’arrivée de nouvelles technologies ou bien de nouvelles pratiques d'ouverture des données (FAIR data, Science Ouverte) déclenche les mêmes phénomènes.
Le cas de la base EMDB (Electron Microscopy Data Bank) illustre ce phénomène comme le montre le graph ci-dessous.

Accroissement du nombre d'entrées de l'EMDB publiées par année et cumulées. Source : statistiques EMBD
-
L'adaptation des plateformes de Bio-Informatique
Les plates-formes Bio-Informatiques, occupant une place stratégique en tant que lieux de traitement de toutes ces données, sont des témoins privilégiés de cette évolution et doivent s’adapter pour accompagner au mieux les divers travaux de recherche. On constate que, depuis ces dernières années, les plates-formes Bio-Informatiques ouvertes aux communautés de recherche ont dû faire croître de manière importante leurs infrastructures pour accueillir des utilisateurs et utilisatrices toujours plus nombreux et dont les travaux d’analyses requièrent toujours plus de capacité de calcul et de stockage.
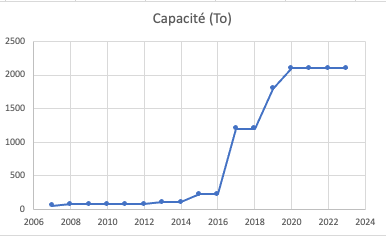
Accroissement de la capacité de stockage de la plate-forme Bio-informatique GenOuest, localisée à Rennes.
-
Hétérogénéité des données
La Biologie se caractérise par un grand nombre de types de données : séquences, motifs, graphes pour décrire les voies métaboliques ou les interactions, données quantitatives de suivi d'expression, données temporelles, images au contenu informationnel varié (résolution, traitements différents), informations spatiales et géographiques, modèles, données textuelles, etc.
Cette variété des données représente un défi en terme d'intégration pour les années à venir, d'autant plus que de nouvelles technologies de génération de données peuvent enrichir et compliquer ce paysage.
Pour aborder la question de l'hétérogénéité des données, on peut considérer à titre d'exemple la page dédiée aux ressources et aux outils de l'EBI (European Bioinformatics Institute).
En filtrant une recherche par "data resources", on a 63 résultats qui vont couvrir des catégories aussi diverses que de l'imagerie, des puces à ADN, des séquences...
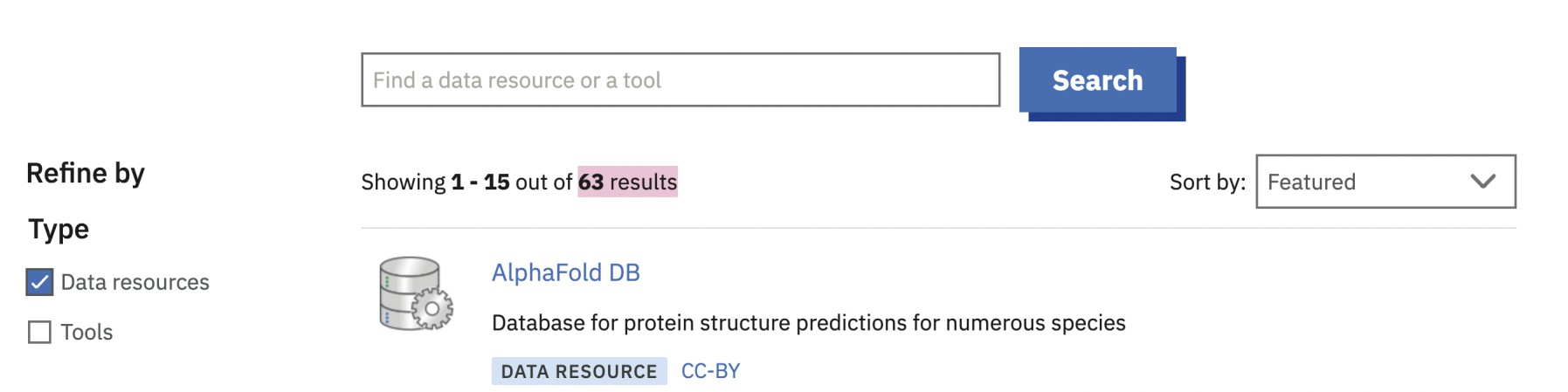
Tout cela complique de manière importante le travail du scientifique qui doit, à terme, intégrer / croiser les données pour pouvoir générer des informations significatives. Cette tâche est rendue plus complexe par le foisonnement de ressources à sa disposition. L'article annuel "NAR Database Issue" de la revue Nucleic Acids Research recense 1645 ressources dans sa 29ème édition publiée en décembre 2021.
-
Diversité des outils d'analyse
La diversité des outils d'analyse peut être traduite en considérant juste la page de bio.tools qui recense actuellement plus de 28 000 outils. Si l'on filtre notre recherche uniquement par le séquençage, on s'aperçoit qu'il y a environ 10 000 outils.
Cela signifie que les scientifiques sont amenés à un travail très important de sélection des outils afin d'identifier la ressource la plus adaptée à leur besoin. Le site bio.tools est d'ailleurs une solution à cette problématique puisqu'il permet de faire des recherches d'outils par catégorie.

28 190 outils au total sur bio.tools ( avril 2023)

10 749 outils dédiés à l'analyse de séquences sur bio.tools (avril 2023)
-
Abondance des données en Sciences de la Vie
Le graphe du LOD (Linked Open Data) présente les données publiques interconnectées grâce aux technologies du web sémantique. On constate que le domaine de la Biologie (entouré en rouge) est particulièrement bien représenté dans ce graphe avec un nombre important de ressources ouvertes et accessibles. Parmi les ressources disponibles, on peut citer :
- Les bases de données de référence (génomiques et protéiques) telles GenBank, UniProt, PDB (Protein Data Bank), KEGG (Kyoto Encyclopedia of Genes and Genomes), etc.
- Les bases de données d'expression génique comme GEO (Gene Expression Omnibus), ArrayExpress.
- Les bases de données des variations génétiques telles dbSMP (Single Nucleotide Polymorphism Database), GWAS Catalog (Genome Wide Association Studies).
- Les bases de référence des ontologies et des taxonomies comme GO, NCBI (National Center for Biotechnology Information).
Les bases de données en Sciences de la Vie se caractérisent par une connectivité importante (liens gris entre les ressources) qui devrait favoriser l'intégration des données.
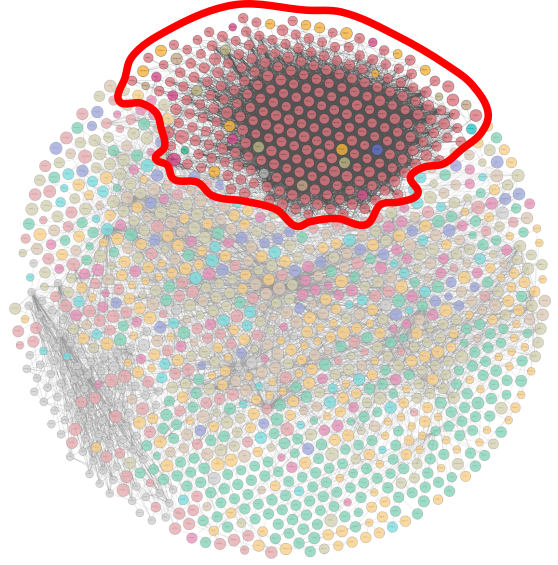
Visualisation des données interconnectées en sciences de la vie - source : The Linked Open Data
-

Bio
C'est au niveau de la couche métier de la Biologie que sont posées les questions et que sont générées les données. Avec les évolutions technologiques, les données sont le plus souvent sous format numérique et sont analysées avec les outils Bio-Informatiques.

Bio-Info
C'est au niveau de la couche métier Bio-Informatique que sont prises en charge les données pour être analysées avec l'ensemble des logiciels développées par la communauté, le plus souvent mis en œuvre au sein de workflows avant de délivrer les résultats qui vont permettre de répondre aux questions biologiques.
-
-
Dans le cadre de la structuration des projets de recherche, la gestion des flux de données en Biologie et en Bio-Informatique est un enjeu majeur pour les chercheurs qui devront mettre en place une organisation allant de la génération des données jusqu'à leur pérennisation, en passant par leur analyse. Dans un tel objectif, l'identification des infrastructures de génération, d'analyse et de pérennisation des données mais également l'adoption de bonnes pratiques de gestion de données est essentielle.
-
Des ressources d'auto-formation
Voici quelques ressources d'auto-formation accessibles librement :
DoRANum
Une plateforme de formation sur la gestion et le partage des données de la recherche réalisée par l’Inist-CNRS et le GIS Réseau Urfist.
FAIRcookbook
Diverses recettes pour une démarche FAIR.
The Turing Way
Une ressource pour la mise en place d'une science des données reproductible, éthique et collaborative.
-
Autres outils de gestion
Dans le cas de projets incluant une composante de développement logiciel, il faut garder à l'esprit qu'existent désormais des Plans de Gestion des Logiciels (Software Management Plan : SMP). Le réseau ELIXIR promeut la mise en place de SMP dans le domaine de la Bio-Informatique et dispose d'une page où sont consultables les travaux.
Parallèlement à l'utilisation d'outils de planification tels que les DMP ou les SMP, l'outil SEEK, développé dans le cadre du projet FAIRDOM, peut être d'une grande aide pour mieux structurer la gestion des données dans une perspective de partage et de collaboration. FAIRDOM-SEEK est une plate-forme de catalogage et de communs open source, basée sur le Web, permettant de partager des ensembles de données de recherche hétérogènes, des modèles ou des simulations, des processus et des résultats de recherche. Il préserve les associations entre eux, ainsi que des informations sur les personnes et les organisations. Il permet de capturer les divers éléments clés d'un projet de recherche en les représentant sous forme graphique.
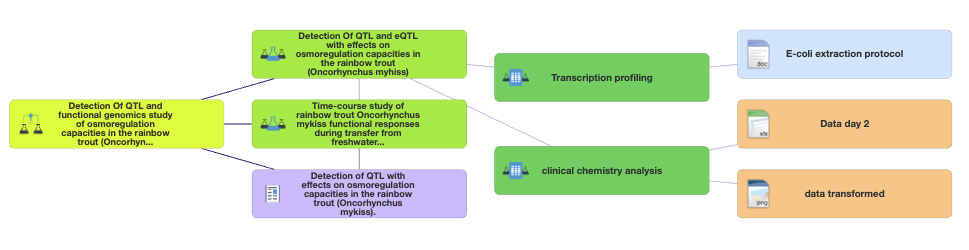
Vue graphique offerte par SEEK permettant de visualiser l'arborescence ISA (Investigation Study Assay).
-
Cette section aborde la question de la gestion des données en Biologie et en Bio-Informatique, de leur génération à leur réutilisation. Elle traite des défis liés aux formats, au stockage, aux licences et aux transferts de données, mettant en avant les pratiques et les solutions pour une gestion optimale des données scientifiques.
-
La génération / réutilisation de données
À l'heure de l'intégration des données, les projets combinent très souvent une phase de génération de données et une phase de réutilisation de données.
Génération de données
Pour la phase de génération de données vont se poser diverses questions concernant l'adoption de pratiques concernant les formats, le nommage des fichiers, etc. afin de pouvoir, tout au long du cycle de vie du projet, gérer efficacement ces données dans la perspective de leur valorisation par un partage auprès de la communauté scientifique.
Si l'on ne dispose pas des ressources de génération / traitements de données adaptés au sein de son laboratoire, on pourra se retourner vers les plates-formes offrant les services adaptés. Ces plates-formes se dotent, elles-aussi, de DMP structure : Cat-OPIDoR, IBiSA, Génotoul, Biogenouest...
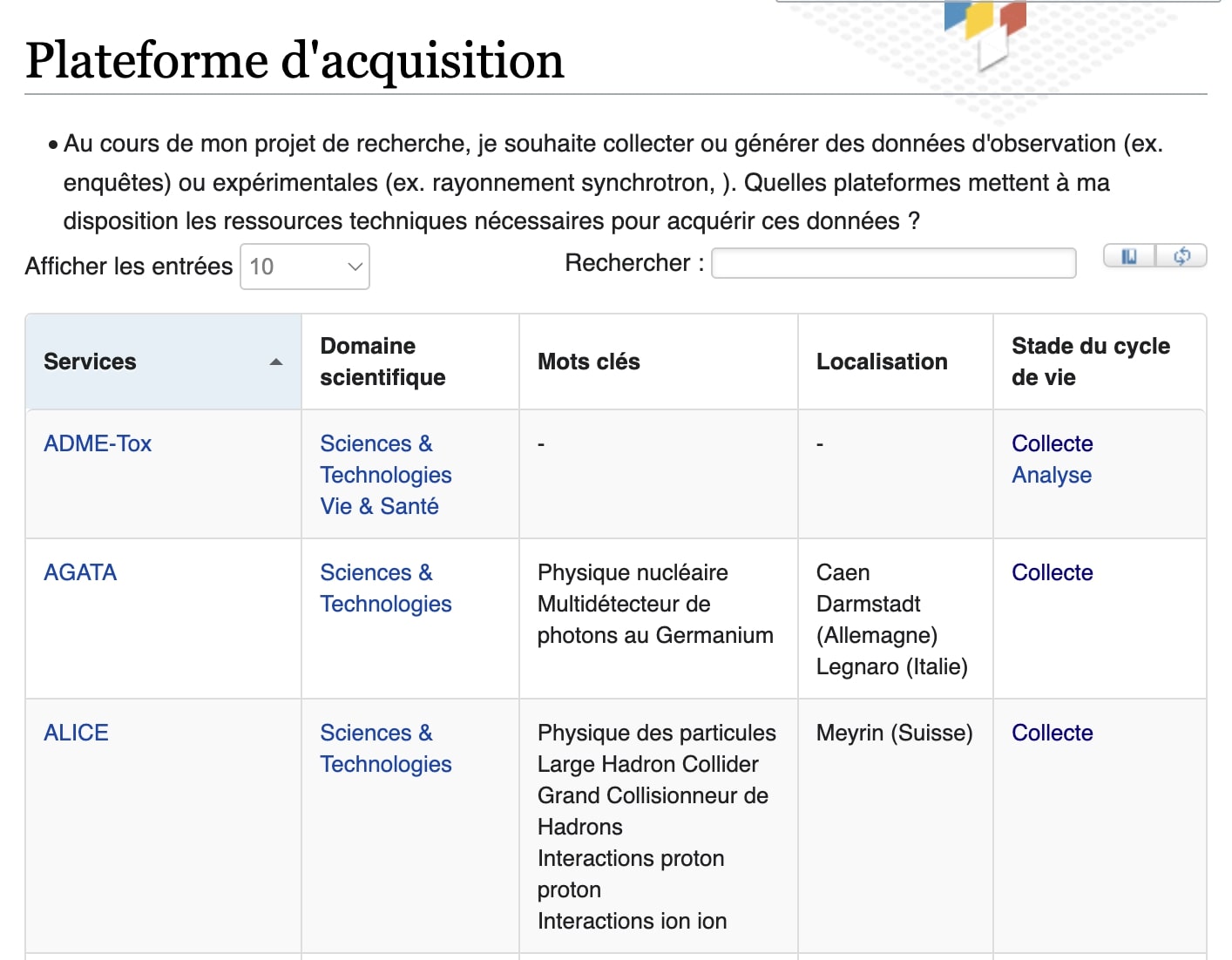 Extrait de la liste des plateformes d'acquisition sur Cat OPIDoR
Extrait de la liste des plateformes d'acquisition sur Cat OPIDoR Extrait de la liste des données disponibles sur ELIXIR Core Data Ressource
Extrait de la liste des données disponibles sur ELIXIR Core Data RessourceRéutilisation de données
Pour identifier des jeux de données réutilisables, en plus du travail classique de bibliographie, on pourra explorer les banques de données généralistes, consulter les ressources et dépôts sur re3data (Registry of Research Data Repositories) ou encore consulter les listes de dépôts d'éditeurs de journaux scientifiques (Nature, ASM, etc.). ELIXIR propose également une liste de ses ressources.
En cas de téléchargement de données potentiellement volumineuses, on risque de rencontrer la problématique du transfert et du stockage de ces données (voir les chapitres ci-dessous).
Pour cette phase de réutilisation des données existantes, il faudra également se poser la question de la licence attribuée à ces données afin de savoir si elles sont réutilisables. Si aucune licence n'est associée aux données, elles ne sont pas réutilisables.
-
Le stockage des données
Une des plus grandes difficultés pour le chercheur ou la chercheuse est de bien estimer le volume des données afin de s'assurer qu'elles pourront être hébergées sans dépasser les capacités de stockage des plates-formes d'analyse mais également des capacités de calcul.
Il faut bien évidemment considérer les données brutes mais également toutes les données intermédiaires qui peuvent faire exploser les besoins en stockage et en analyse, sans compter également les données de référence issues des entrepôts ou des banques.

Il est essentiel de toujours interagir en amont avec son service informatique ou bien sa plate-forme bio-informatique pour anticiper le stockage et les traitements nécessaires, surtout lorsque les jeux de données sont très volumineux (plusieurs dizaines de To). C'est également le service informatique ou les gestionnaires des infrastructures de calcul qui pourront prodiguer des conseils concernant les différents types de stockage (capacitif ou rapide) et ainsi de choisir la solution la plus adaptée.
Le coût du stockage
L'estimation du volume des données est très important pour le déroulement sans accrocs techniques mais également pour une gestion efficace des financements. Il est indispensable de se renseigner sur le coût des volumes. À titre d'exemple, certains sites proposent des outils d'évaluation des coûts de stockage, à l'image du DSW Storage Costs Evaluator.
-
-
Reposant sur l'utilisation de logiciels, au sein de divers environnements, cette étape va permettre de "faire parler les données". Ce passage de la donnée brute à l'information est une des étapes clés de la Bio-Informatique. Étant pratiquée in silico, elle doit être menée avec rigueur afin de pouvoir être reproductible.
-
Exemple pratique : aligner des séquences avec Clustal
Clustal (utilisé dans ses versions Omega et W dans les exemples) est un outil populaire en Bio-Informatique utilisé pour l'alignement multiple de séquences génomiques et protéiques. Il est largement utilisé pour analyser et comparer des séquences biologiques afin d'identifier les similarités, les motifs conservés et les relations évolutives entre les séquences.
Disponible sous forme de logiciel open source, Clustal peut être téléchargé sur son site officiel pour une exécution en local ou être utilisé en ligne via des serveurs web. On le retrouve notamment sur le portail Galaxy.
Nous vous proposons d'illustrer les différentes modalités d'utilisation avec un exemple simple : l'alignement des séquences des protéines Spike du coronavirus à l'aide du programme Clustal en passant par le terminal d'un ordinateur (en ligne de commande) et en passant par le portail Galaxy.
L'utilisation de Clustal en local demande d'utiliser le terminal de l'ordinateur. La vidéo ci-dessous vous montre comment aligner les séquences des protéines Spike du coronavirus à l'aide du programme Clustal en passant par les lignes de commande.
L'utilisation de Clustal en ligne, via des portails comme Galaxy, est une solution plus simple si vous n'êtes pas familier avec l'exécution de tâches en ligne de commande. Pour vous le montrer, nous vous proposons de le tester par vous-même. Pour cela :
- Téléchargez le fichier "spike_sequences.fasta"
- Rendez-vous sur le portail public de Galaxy
- Reproduisez la procédure indiquée dans le petit tutoriel ci-dessous. Notez que dans ce tutoriel, on utilise le portail Galaxy de la plateforme GenOuest, mais la procédure reste identique.
Galaxy Training
La communauté de Galaxy propose des cours en ligne pour s'initier à l'outil. Rendez-vous sur Galaxy Training pour une formation complète !
-

Mieux contrôler ses données
Vue sous l'angle de l'analyse, la gestion des données pour un projet s'intéresse aux données de référence mais également aux données du projet.
Gestion des données de référence
Ces données sont susceptibles de varier au fil du temps. Dans le cas de l'utilisation de banques de données, on s'attachera à toujours documenter les numéros des versions. Les plates-formes de Bio-Informatique proposent des méthodes automatisées de mise à jour de ces banques, par exemple avec l'outil BioMAJ.
Pour aller plus loin, consultez les Dix règles simples pour utiliser les données biologiques publiques pour votre recherche.
Gestion des données du projet
Tout commence par l'adoption d'un plan de nommage et de désignation des fichiers. Afin de se faciliter la vie, il est souhaitable d'adopter quelques règles de base pour nommer ses fichiers. Ces règles permettent d'obéir à trois grands principes :
- Les noms des fichiers doivent être lisibles par les machines ;
- Les noms des fichiers doivent être compréhensibles par les humains ;
- Les noms des fichiers doivent permettre le tri et la sélection des fichiers.
Les dates dans les noms des fichiers doivent respecter le format de la norme ISO8601 (YYYY-MM-DD).
Ensuite il faut rationaliser l'organisation des fichiers au sein de l'arborescence des fichiers avec des répertoires homogènes. Par exemple, pour un projet de bioanalyse, on peut envisager l'arborescence suivante :
↳ _README ↳ docs ↳ raw_data ↳ Homo_sapiens ↳ Rattus_rattus ↳ _README ↳ results ↳ scripts ↳ tools ↳ work ↳ 2023-03-01_Assembly
Suivant la nature des projets des variations sont possibles. En effet, en fonction du nombre de personnes, le recours à des outils collaboratifs comme Git, va modifier profondément l'arborescence de travail qui pourra se réduire à un tryptique : données brutes / travaux / résultats.
Pour aller plus loin, vous pouvez consulter :
-

Mieux contrôler ses outils logiciels
Pour exercer un meilleur contrôle sur les diverses versions d'outils utilisés pour vos analyses, il est possible d'utiliser un gestionnaire de package comme Conda et son extension dédiée à la Bio-Informatique Bioconda.

Conda permet d'installer des logiciels pré-compilés disponibles sous forme de paquets. Ces paquets sont déposés dans des canaux ("channels") thématiques.
Le canal Bioconda recense plus de 7000 paquets pour les communautés des Sciences de la Vie.
Conda permet également de créer des environnements au sein desquels on peut installer des outils spécifiques. Le fait que ces outils soient installés au sein d'un environnement permet d'éviter qu'il n'y ait des interférences avec l'environnement du système. Ces environnements peuvent être activés ou désactivés à la demande.
Il existe également Mamba, un gestionnaire offrant plus de rapidité que Conda.

D'autres solutions comme Guix et Nix (et son pendant "bio", BioNix), existent aussi.

-

Mieux contrôler ses workflows
Une des caractéristiques de l'analyse des données en Bio-Informatique est le fait qu'il est nécessaire de combiner une multitude d'outils qui représentent alors un workflow. Pour reproduire un traitement il s'agira d'être capable de conserver le paramétrage de chaque outil tout en conservant l'ordonnancement des différents outils utilisés.
Il existe de nombreux systèmes de gestion de workflows. Les plus populaires en Bio-Informatique sont :Chaque environnement de workflow va proposer un dépôt pour permettre aux utilisateurs et utilisatrices de partager leurs workflows. Dans le cas de Nextflow, il s'agit de nf-core. Pour Snakemake, un catalogue existe également, tandis que Galaxy utilise le dépôt de l'Interagalactic Workflow Commission pour partager les workflows.
À noter que se mettent en place de nouvelles ressources comme WorkflowHub pour partager les workflows scientifiques. -

Mieux contrôler ses environnements de calcul
Une fois que l'on contrôle ses données, ses logiciels et ses workflows, il reste une dernière étape pour atteindre une bonne reproductibilité en s'affranchissant des contraintes imposées par le système d'exploitation. En effet, suivant la version du système d'exploitation, suivant les diverses installations de logiciels, certaines bibliothèques logicielles utilisées par les programmes peuvent différer et influer sur les résultats des analyses.
Il est donc nécessaire d'isoler ses environnements pour mieux les contrôler. Ceci est réalisable grâce aux techniques de virtualisation.
La virtualisation
Elle permet de faire fonctionner, sur une seule machine, un ou plusieurs systèmes d’exploitation en tant que logiciel. Les machines virtuelles (ou VM pour Virtual Machine) fonctionnent ainsi en créant un système d'exploitation complet et indépendant à l'intérieur d'un ordinateur physique. Cela signifie qu'une machine virtuelle est un environnement complet et autonome, avec son propre système d'exploitation, ses propres fichiers de configuration et ses propres ressources matérielles.

Les intérêts de la virtualisation sont multiples :
- Il devient possible de pouvoir exploiter les machines de manière optimale en rentabilisant au maximum leurs capacités.
- Le déploiement de nouvelles machines est facilité car il n'y a plus d'installation physique. Cela permet de mettre en place rapidement des environnements de tests ou de formation qui sont isolés.
- Il est possible de déployer les machines à la demande, en quelques minutes, pour mettre en place une infrastructure complète.
-
Ordinateur

Architecture classique d'un ordinateur. On remarque le rôle central du système d'exploitation (ici macOS) qui sert d'interface etnre les logiciels et le matériel. Il fournit une interface utilisateur, s'occupe du système de fichiers et gère les périphériques.
Machine virtuelle avec hyperviseur

Un hyperviseur est un logiciel qui permet de créer et de gérer des machines virtuelles en isolant les ressources matérielles, en abstrayant le matériel physique et en fournissant des fonctionnalités de gestion et de sécurité pour les VM.
Machine virtuelle avec conteneur

Apparue dans les années 2010, la conteneurisation est une virtualisation au niveau du système d'exploitation. Contrairement aux VM avec hyperviseur, les conteneurs sont plus légers et sont souvent privilégiés pour la portabilité et l'efficacité des ressources.
Les environnements de containeurisation sont variés : Docker (outil de conteneurisation polyvalent), Singularity / Apptainer (conçu spécifiquement pour les environnements de calcul scientifique et haute performance)...
-
Les notebooks
Les notebooks sont des documents mélangeant du texte enrichi avec des balises Markdown, des éléments de code exécutable ainsi que les résultats de l'exécution de ces éléments de code, le plus souvent des graphiques.
L'utilisation des notebooks se développe de manière importante pour apporter de la lisibilité et de la reproductibilité.
L'utilisation des notebooks permet de combiner code et représentation pour faciliter la lecture du code et en assurer ainsi une meilleure communication.
Parmi les outils, on peut citer :
- Jupyter notebooks ;
- Rmarkdown / Quarto ;
- Org-Mode.
Pour vous former, vous pouvez consulter cette introduction aux notebooks Jupyter sous Galaxy.
 Delphine Lariviere, Use Jupyter notebooks in Galaxy (Galaxy Training Materials) https://training.galaxyproject.org/training-material/topics/galaxy-interface/tutorials/galaxy-intro-jupyter/tutorial.html Online; accessed Thu Jun 08 2023
Delphine Lariviere, Use Jupyter notebooks in Galaxy (Galaxy Training Materials) https://training.galaxyproject.org/training-material/topics/galaxy-interface/tutorials/galaxy-intro-jupyter/tutorial.html Online; accessed Thu Jun 08 2023
-
Cette section met l'accent sur les principes fondamentaux de préservation, garantissant l'intégrité, la lisibilité et la réutilisabilité des données. Le partage des données est abordé, y compris les licences et les ressources pour faciliter ce processus. Des conseils sont donnés pour choisir des licences appropriées et des ressources sont fournies pour aider les scientifiques à archiver et partager leurs données de manière responsable et éthique.
-
Un forum est à votre disposition pour toute question. Vous pouvez aussi nous aider à améliorer ce cours en donnant votre avis.
-
Autres suggestions