
Les pipelines de traitement
Résumé de section
-
Les pipelines de traitement sont des étapes nécessaires pour exploiter les images médicales.
-
Les changements de format dans les pipelines
Les formats utilisés dans les pipelines de traitement en imagerie médicale peuvent varier en fonction des besoins spécifiques et des outils logiciels utilisés. On peut citer le format NIFTI (Neuroimaging InFormatics Technology Initiative) en neuroimagerie principalement pour des images 3D ou 4D et les régions d’intérêts associés, ou encore le format MHD/RAW.

Ces formats peuvent être convertis les uns en les autres à l'aide de logiciels et de bibliothèques appropriés, afin de permettre l'intégration et l'interopérabilité entre les différents outils et les plates-formes.
Dans le cas de cohortes en imagerie médicale, les données en DICOM sont souvent converties pour une plus grande facilité de manipulation et d’interpolation au niveau des pipelines. Cependant, des résultats peuvent être in fine converties en DICOM pour exploiter des visualisations avancées par exemple.
-
Structurer des données d'imagerie cérébrale avec BIDS
Depuis quelques années, afin d’assurer une plus grande portabilité et reproductibilité des pipelines en neuroimagerie (et récemment pour d’autres applications), une structuration des données au format NIFTI a été proposée : BIDS (Brain Imaging Data Structure).
Entre autres caractéristiques : les données sont organisées dans une arborescence de répertoires spécifiques, les fichiers sont nommées en suivant une norme significative et précise, les métadonnées sont associées au format json, nommage explicite des variables...
Comparaison entre une organisation classique de fichiers et l'organisation des fichiers avec BIDS. Source : https://bids.neuroimaging.io/
-
Problématiques des pipelines
Gestion des données volumineuses
Dans le contexte de la recherche en imagerie médicale, notamment les cohortes, il est fréquent de collecter une grande quantité de données. Cela est particulièrement vrai pour les données longitudinales, qui impliquent la collecte répétée d'images ou d'examens médicaux sur une période de temps prolongée.
Pour donner un exemple, un ensemble de données d'imagerie CT collectées pendant la pandémie de COVID-19 dans le cadre du COVID-CTPRED project a atteint une taille de 2 téraoctets (To) pour 800 patients.
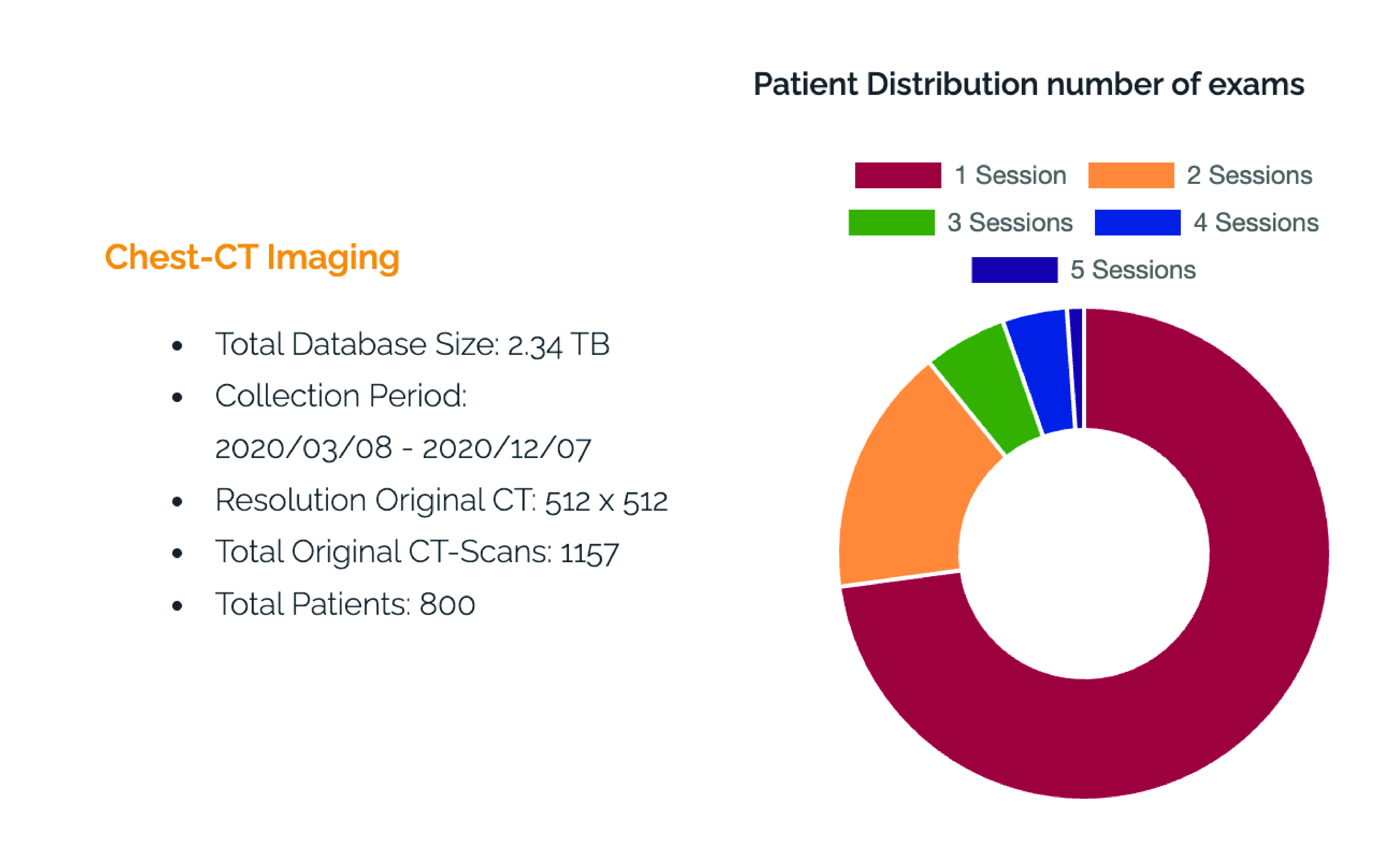
La volumétrie des données peut rapidement devenir importante, ce qui nécessite des ressources de stockage considérables et des infrastructures informatiques robustes pour le traitement et l'analyse de ces données massives.
-
Rétraction de patients de l'étude
Parfois, un patient participant à une étude médicale peut décider de se retirer de l'étude pour diverses raisons (préoccupations personnelles, effets secondaires indésirables...). Lorsqu'un patient se retire, les données pour lesquelles il a contribuées ne seront plus disponibles pour de futures analyses ou traitements.
Les pipelines de traitement peuvent avoir utilisé les données de ce patient pour créer des modèles de diagnostic ou pour effectuer d'autres analyses. Il devient alors essentiel d'identifier quels pipelines ont utilisé ces données.
Si les données de ce patient ont été utilisées pour établir un modèle de diagnostic, leur retrait pose la question de la validité et de la performance continue de ce modèle. En conséquence, il peut être nécessaire de régénérer le modèle en utilisant les données disponibles à partir d'autres patients ou de mettre à jour le modèle en l'adaptant aux données restantes.

Il est donc important de suivre de près les données des patients retirés, d'identifier les pipelines qui ont utilisé ces données, et de prendre des mesures pour régénérer ou mettre à jour les modèles de diagnostic afin de maintenir la qualité et la validité des résultats dans le cadre d'études médicales longitudinales.