
Cohortes en santé : données ouvertes en imagerie médicale
Résumé de section
-
Ce cours examine en profondeur les cohortes en santé et l'utilisation des données d'imagerie médicale en recherche. Il couvre les enjeux techniques, juridiques et éthiques de l'ouverture des données d'imagerie au sein de cohortes, ainsi que les défis liés à l'évolution des librairies de programmation et de l'environnement d'exécution dans le contexte des pipelines de traitement.
Objectifs
- Comprendre la structure du format DICOM.
- Identifier les obligations et contraintes en termes de RGPD.
- Identifier les étapes des pipelines de traitement.
- Identifier les techniques pour interagir avec les données.
Ce cours est en libre accès !
Aucune création de compte ou d'inscription n'est nécessaire, toutefois vous ne pourrez le parcourir qu'en lecture seule.
Pour participer aux activités (exercices, forum...), vous devez vous inscrire au cours
S'inscrire au cours -
Qu'est-ce qu'une cohorte et quelles sont les particularités de ces données ?
-
Les cohortes en santé
En épidémiologie, une cohorte est un groupe de personnes qui partagent une (ou plusieurs) caractéristique(s) commune(s) et qui sont suivies dans le temps pour étudier l'incidence de certaines maladies, l'effet de facteurs de risque ou l'efficacité d'interventions médicales.
Il est important d'avoir une large population pour être suffisamment générique ou statistiquement pertinent, bien qu'il soit difficile pour certaines pathologies de regrouper un nombre important de patients (maladies rares notamment).

-
Enjeux de l'ouverture des données de cohortes en santé
L'ouverture des données consiste en la mise à disposition des données brutes et des informations associées provenant d'études de cohortes à la communauté scientifique. Cette pratique vise à favoriser la transparence, la collaboration et l'avancement de la recherche en santé.
Exemple de données de cohorte ouvertes : l'OFSEP
L'OFSEP (Observatoire Français de la Sclérose en Plaques) est une cohorte nationale française regroupant des patients atteints de sclérose en plaques. Elle a été créée dans le but de collecter des données longitudinales sur la maladie, de suivre l'évolution des patients et d'étudier les facteurs liés à la sclérose en plaques.

L'OFSEP rassemble les données biologiques des patients (sang, urine, liquide cérébro-spinal) ainsi que des IRM. Les chercheurs ont la possibilité de solliciter l'accès aux données et aux échantillons collectés par l'OFSEP en soumettant un projet de recherche. Les demandes de projet sont évaluées conformément au processus de soumission établi.
L'OFSEP a contribué à améliorer les connaissances sur la sclérose en plaques et à influencer les pratiques cliniques et la prise en charge des patients. Les données recueillies dans cette cohorte sont précieuses pour les chercheurs et les professionnels de la santé dans le domaine de la sclérose en plaques.
-
France Cohortes : une initiative française visant à fédérer et à promouvoir les cohortes françaises en santé
Créée en 2011, l'initiative France Cohortes vise à promouvoir l'utilisation des données de cohortes en santé, à encourager la recherche inter-cohortes et à renforcer les collaborations entre les chercheurs et les cohortes. Elle vise également à améliorer la visibilité et l'accessibilité des cohortes françaises, notamment en facilitant l'accès aux données pour la communauté scientifique et en promouvant la transparence et la rigueur scientifique.

-
-
DICOM est un format standard qui a la particularité de contenir données et métadonnées au sein d'un même fichier.
-
Le format DICOM (Digital Imaging and Communications in Medicine) est de facto le standard de communication et de stockage d'images médicales numériques depuis 1985. Il permet de stocker, de transférer et de partager de manière standardisée des images médicales (IRMs, scanners, radiographies, échographies, …) ainsi que les métadonnées associées (informations sur le patient : âge, sexe, paramètres d'imagerie, clinicien, …). Ce format permet d'assurer la compatibilité et l'interopérabilité des systèmes d'imagerie médicale des différentes institutions hospitalières quel que soit le fabricant.

-
Les images médicales stockées dans le format DICOM peuvent être visualisées à l'aide de logiciels spécialisés et les informations associées peuvent être facilement extraites pour l'analyse et la gestion des données médicales.
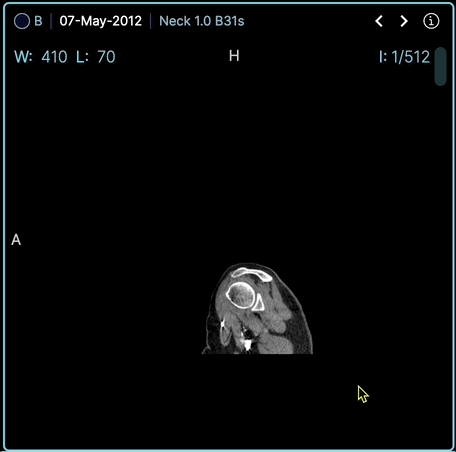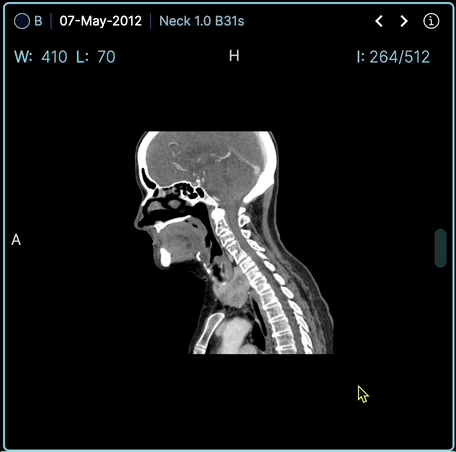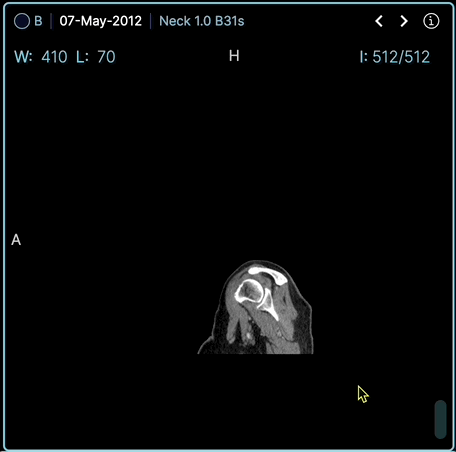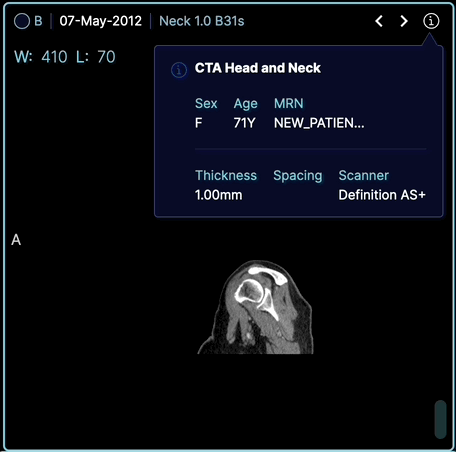
OHIF Viewer est une plateforme web d'imagerie médicale permettant de lire les images DICOM et les métadonnées associées.
Actuellement, la version du standard DICOM est la 3.0 intégrant des fonctionnalités pour stocker des données de segmentation, de classification, de planification de doses en radiothérapie et bientôt des modèles d'inférence en intelligence artificelle utilisées lors d’études sur cohortes.
-
Anatomie d'un fichier DICOM
Les fichiers DICOM sont constitués de deux parties distinctes : un en-tête et les données d'image.
L'en-tête
L'en-tête contient les métadonnées de l'image, sous forme de tags. On y retrouve les informations sur le patient, la modalité d'imagerie, la date et l'heure de l'acquisition, le type d'image, les paramètres d'acquisition et des identifiants uniques.
Chaque tag est défini par une clé unique en hexadécimal (ex: 0010, 0010) permettant d’identifier la valeur de la métadonnée associée.
Exemples de tags importants
- Patient Name (0010,0010) : Ce tag contient le nom du patient.
- Patient ID (0010,0020) : Ce tag contient un identifiant unique pour le patient.
- Patient Sex (0010,0040). Ce tag contient le sexe du patient.
- Patient Address (0010,1040). Ce tag contient l’adresse du patient.
- Modality (0008,0060) : Ce tag indique le type de modalité utilisé pour acquérir l'image, comme CT, MRI, etc.
- Study Description (0008,1030) : Ce tag contient une description du type d'étude pour laquelle l'image a été acquise.
- Series Description (0008,103E) : Ce tag contient une description de la série d'images acquises lors de la même étude.
- Pixel Data (7FE0,0010) : Ce tag contient les données de pixel brutes de l'image.
Les données d'image
Les données d'image elles-mêmes sont stockées en tant que tableau de pixels, où chaque pixel contient une valeur numérique qui représente l'intensité de l'image à ce point.
Exemple fictif de tableau de pixels

-
-
Comment anonymiser des images médicales sans perdre d'informations utiles ?
-
Méthodologies d'anonymisation
Dans le cadre des données de santé, différentes méthodologies sont applicables :

Suppression
On supprime l'ensemble des informations d'identification sur la donnée d’origine. Aucun mécanisme ne permet de remonter à la donnée d’origine.

Substitution / généralisation
Par exemple, on généralise les dates de naissance en les remplaçant par une plage de valeurs ("1974" devenant [1970-1975]). La difficulté vient de la conservation de l’information ou de la statistique pertinente.

Pseudonymisation
On remplace un ensemble de tags par des valeurs nulles, ou sans aucun lien avec les valeurs d’origine ou selon un template. Par exemple : COHORTE_PAT_001 pour remplacer le nom du patient.

Perturbation
On introduit du bruit dans les données en modifiant des valeurs tout en préservant les statistiques générales. Par exemple : si une cohorte se comporte de 70% de patients entre 20-40 ans et 30 % de 40 ans et plus, il suffit de modifier les dates de naissance tout en conservant cette distribution.
-
Anonymisation des images DICOM
Concernant les images médicales au format DICOM, l’anonymisation consiste à utiliser un ensemble de mesures de manière à rendre impossible toute identification de la personne par quelque moyen que ce soit et ce, de manière irréversible. Ce qui consisterait à la suppression de la donnée image d’origine.
Dé-identification / Ré-identification des images DICOM
La dé-identification est une autre méthode qui, comme l'anonymisation, supprime les identifiants personnels d'un ensemble de données par la suppression ou le cryptage. La différence est qu'il est possible d'inverser le processus : c'est la ré-identification.

La ré-identification DICOM peut être nécessaire dans certaines situations cliniques ou de recherche où l'accès aux informations d'identification personnelles est crucial pour une prise en charge médicale adéquate ou pour des études longitudinales. Cependant, elle doit être effectuée avec prudence pour éviter tout risque pour la vie privée des patients et en conformité avec les réglementations sur la protection des données.
-
Que dit la loi concernant le traitement des données d'imageries médicales ?
-
Obligations liées au RGPD
Les obligations liées au RGPD sur les données de santé sont assez nombreuses. On trouve notament les points suivants :
Consentement éclairé
Obtenir le consentement explicite et éclairé des individus avant de collecter, traiter ou stocker leurs données de santé.


Transparence
Fournir des informations claires et compréhensibles sur les finalités du traitement des données de santé, les types de données collectées, les destinataires des données, etc.
Sécurité des données
Mettre en place des mesures techniques et organisationnelles appropriées pour assurer la sécurité et la confidentialité des données de santé, en prévenant les accès non autorisés, les divulgations ou les altérations.


Conservation limitée dans le temps
Ne conserver les données de santé que pendant la durée nécessaire aux finalités pour lesquelles elles ont été collectées.
Gestion des droits des individus
Permettre aux individus d'exercer leurs droits, tels que le droit d'accès, le droit de rectification, le droit à l'effacement, le droit à la portabilité des données.


Désignation d'un responsable de la protection des données (DPO)
Un DPO doit être désigné/identifié afin d’être le garant de la protection des données et du respect des obligations.
Inscription dans le registre des traitements
Toute constitution d’une base de données de santé dans un cadre de recherches doit faire l’objet d'une inscription en base de registres.


Plan d’Analyse d'impact sur la protection des données (PAI)
Effectuer un PAI pour évaluer les risques potentiels pour la vie privée et mettre en place des mesures pour atténuer ces risques.
Notification des violations de données
En cas de violation des données de quelque nature, notifier les autorités de protection des données compétentes et, dans certains cas, les individus concernés, dans les meilleurs délais.


Gestion des sous-traitants
Veiller à ce que les sous-traitants qui traitent des données de santé respectent également les mêmes exigences liées au RGPD par le biais de contrats de sous-traitance et d'accords appropriés.
-
Cet exercice vous permet de tester l'anonymisation d'un fichier DICOM à l'aide de la librairie PyDicom.
-
Présentation
Nous allons voir de façon concrète un exemple d'anonymisation d'une image DICOM. Pour ce faire, nous avons besoin de trois éléments :

Fichier DICOM
Le fichier DICOM contenant les tags à anonymiser.

Jupyter NoteBook
L'environnement pour exécuter les commandes d'anonymisation sur le fichier DICOM.
Nous avons installé tous ces éléments dans un espace dédié du site Binder qui permet de créer, partager et exécuter des environnements de NoteBooks directement à partir d'un navigateur web, sans nécessiter d'installation locale.
En temps normal, dans le cadre d'un travail de recherche, il est nécessaire d'utiliser un environnement sécurisé propre à votre laboratoire. Ne travaillez jamais avec des données sensibles dans des environnements accessibles publiquement !
Tout est prêt, vous n'avez qu'à cliquer sur le bouton ci-dessous pour ouvrir Binder dans un nouvel onglet.
Le chargement de la page peut être long à cause de la génération des fichiers (pour suivre l'avancement, cliquez sur le lien "Show").
En parallèle, suivez le tutoriel ci-dessous pour découvrir l'interface et la manipulation des tags DICOM.
-
-
Les pipelines de traitement sont des étapes nécessaires pour exploiter les images médicales.
-
Les changements de format dans les pipelines
Les formats utilisés dans les pipelines de traitement en imagerie médicale peuvent varier en fonction des besoins spécifiques et des outils logiciels utilisés. On peut citer le format NIFTI (Neuroimaging InFormatics Technology Initiative) en neuroimagerie principalement pour des images 3D ou 4D et les régions d’intérêts associés, ou encore le format MHD/RAW.

Ces formats peuvent être convertis les uns en les autres à l'aide de logiciels et de bibliothèques appropriés, afin de permettre l'intégration et l'interopérabilité entre les différents outils et les plates-formes.
Dans le cas de cohortes en imagerie médicale, les données en DICOM sont souvent converties pour une plus grande facilité de manipulation et d’interpolation au niveau des pipelines. Cependant, des résultats peuvent être in fine converties en DICOM pour exploiter des visualisations avancées par exemple.
-
Structurer des données d'imagerie cérébrale avec BIDS
Depuis quelques années, afin d’assurer une plus grande portabilité et reproductibilité des pipelines en neuroimagerie (et récemment pour d’autres applications), une structuration des données au format NIFTI a été proposée : BIDS (Brain Imaging Data Structure).
Entre autres caractéristiques : les données sont organisées dans une arborescence de répertoires spécifiques, les fichiers sont nommées en suivant une norme significative et précise, les métadonnées sont associées au format json, nommage explicite des variables...
Comparaison entre une organisation classique de fichiers et l'organisation des fichiers avec BIDS. Source : https://bids.neuroimaging.io/
-
Problématiques des pipelines
Gestion des données volumineuses
Dans le contexte de la recherche en imagerie médicale, notamment les cohortes, il est fréquent de collecter une grande quantité de données. Cela est particulièrement vrai pour les données longitudinales, qui impliquent la collecte répétée d'images ou d'examens médicaux sur une période de temps prolongée.
Pour donner un exemple, un ensemble de données d'imagerie CT collectées pendant la pandémie de COVID-19 dans le cadre du COVID-CTPRED project a atteint une taille de 2 téraoctets (To) pour 800 patients.
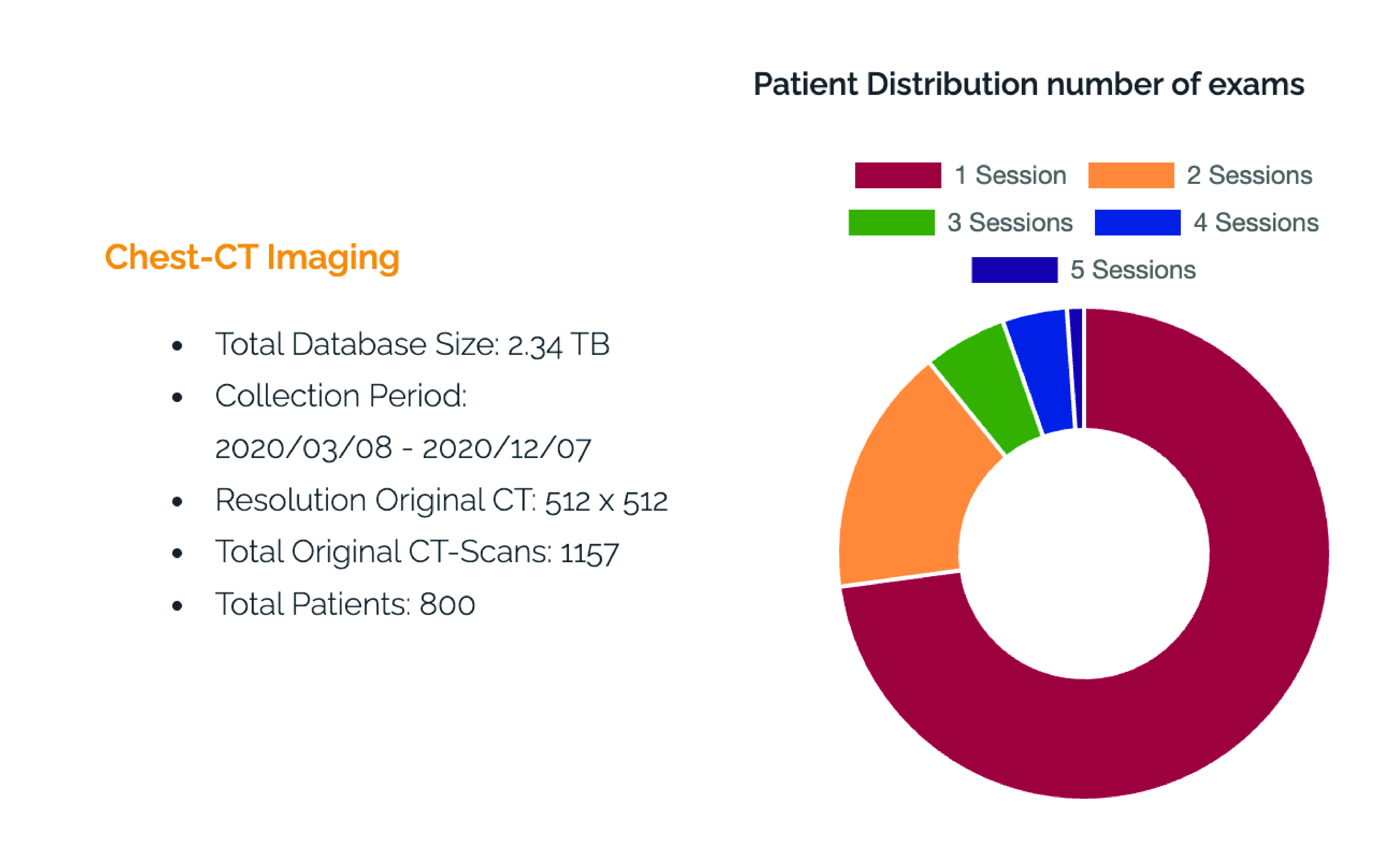
La volumétrie des données peut rapidement devenir importante, ce qui nécessite des ressources de stockage considérables et des infrastructures informatiques robustes pour le traitement et l'analyse de ces données massives.
-
Rétraction de patients de l'étude
Parfois, un patient participant à une étude médicale peut décider de se retirer de l'étude pour diverses raisons (préoccupations personnelles, effets secondaires indésirables...). Lorsqu'un patient se retire, les données pour lesquelles il a contribuées ne seront plus disponibles pour de futures analyses ou traitements.
Les pipelines de traitement peuvent avoir utilisé les données de ce patient pour créer des modèles de diagnostic ou pour effectuer d'autres analyses. Il devient alors essentiel d'identifier quels pipelines ont utilisé ces données.
Si les données de ce patient ont été utilisées pour établir un modèle de diagnostic, leur retrait pose la question de la validité et de la performance continue de ce modèle. En conséquence, il peut être nécessaire de régénérer le modèle en utilisant les données disponibles à partir d'autres patients ou de mettre à jour le modèle en l'adaptant aux données restantes.

Il est donc important de suivre de près les données des patients retirés, d'identifier les pipelines qui ont utilisé ces données, et de prendre des mesures pour régénérer ou mettre à jour les modèles de diagnostic afin de maintenir la qualité et la validité des résultats dans le cadre d'études médicales longitudinales.
-
Il existe de nombreux challenges en imagerie médicale qui sont souvent organisés lors de compétitions, de congrès ou de conférences. Ces challenges servent de plateformes pour évaluer et comparer les méthodes de traitement d'images médicales.
-
Sept questions revenant sur des notions clés abordées dans ce cours.
-
-
Ce forum est disponible pour lancer des discussions entre vous ou poser des questions relatives au cours.
-
-
Autres suggestions
