
1. Introduction
Résumé de section
-
Objectif : appréhender le concept de data paper
30 minutes de lecture
-

L’humanité est à un tournant de son histoire. La masse des données acquises est formidable. Il faut de nouveaux instruments pour les simplifier, les condenser ou jamais l’intelligence ne saura ni surmonter les difficultés qui l’accablent, ni réaliser les progrès qu’elle entrevoit et auxquels elle aspire.
-
Définitions

Le Data Paper décrit un jeu de données et son contexte, la méthode d’obtention et le potentiel de réutilisation.
Un data paper est un article décrivant un ou plusieurs jeux de données publié dans une revue à comité de lecture, ainsi que des informations structurées appelées métadonnées.
La préparation, la gestion et la description des données prennent du temps. Les Data papers permettent à cet effort d’être reconnu et valorisé par l’intermédiaire d’un article académique. Contrairement aux articles de recherches classiques, les data papers fournissent une voie formalisée pour le partage des données plutôt qu'un espace où tester des articles de recherche classiques ou présenter de nouvelles analyses.
Nous utilisons ici le terme data paper (article de données en français) mais de multiples appellations existent. Aussi n’hésitez pas à regarder dans les revues que vous avez l’habitude de consulter si une appellation se rapproche de data paper. Voici quelques exemples :
- Data paper (Annals of Forest Science (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet), Zookeys (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet)...),
- Data notes (F1000 Research (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet), Gigascience (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet)),
- Data article (Data in Brief) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet),
- Data descriptor (Scientific Data (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet)),
- Dataset brief (Proteomics (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet)),
- Data in brief (Genomics Data (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet)),
- Database article – Software article (BMC (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet), Chemistry CentralJournal (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet)),
- Data reports (Frontiers in Plant Science (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet)),
- Resource article (Plant Journal (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet)),
- Database paper (Plant & Cell Physiology (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet)),
- Methods, software, databases, and Tools (Plos One (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet)).
Au-delà des données, ce sont également les métadonnées, les logiciels, les scripts permettant l'exploitation des données qui peuvent également être décrits.
-

Un data paper permet « la diffusion des données de recherche, des métadonnées associées, de la documentation d'accompagnement et du code logiciel (dans les cas où les données brutes ont été traitées ou manipulées) en vue d'une réutilisation et d'une analyse, et d’une manière telle qu’elle permette de les découvrir sur le Web et d'y faire référence de façon unique et persistante »
-

L’objectif majeur du Data Paper est la réutilisation des données. Pour réussir, le Data Paper doit appliquer les bonnes pratiques, notamment disciplinaires, en termes de description, documentation et format ouvert, pour que les données soient trouvables, accessibles, compréhensibles, interprétables et réutilisables.
-
Intérêts du data paper
Pour quelles raisons rédiger et publier un data paper :
- Pour valoriser un travail peu visible dans un article scientifique classique.
- Pour garantir la reproductibilité et la qualité des données (leur vérification).
- Pour faciliter la répétabilité des données (leur réutilisation au-delà du champ disciplinaire original).
- Pour permettre d'agréger et d'analyser les données de recherche.
Pour les décideurs publics, les données ouvertes sont une source potentielle d'innovation et de nouvelles connaissances, à condition d'offrir des conditions de réutilisation des données et d'intégrer les citations de data papers dans les critères d'évaluation de la recherche.

-
Un enjeu de reproductibilité
Un data paper ne permet pas seulement la valorisation de données de recherche, il répond aussi à des enjeux de science ouverte et des facteurs de reproductibilité.
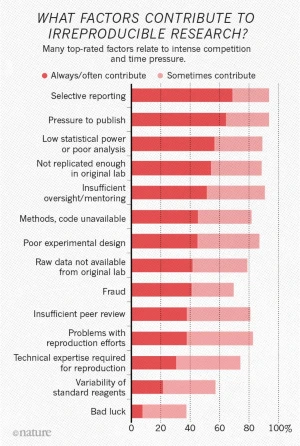
En 2016, 1576 chercheurs ont répondu à un court questionnaire en ligne sur la reproductibilité de la recherche. Si plus de 60 % des interrogés soulignent la pression à la publication, la compétition pour les postes, les financements, etc., ils citent de nombreux problèmes concernant autant les données « brutes » que les méthodes et la disponibilité du code.
Source :1,500 scientists lift the lid on reproducibility
-
Nombre de téléchargements sans ou avec data paper
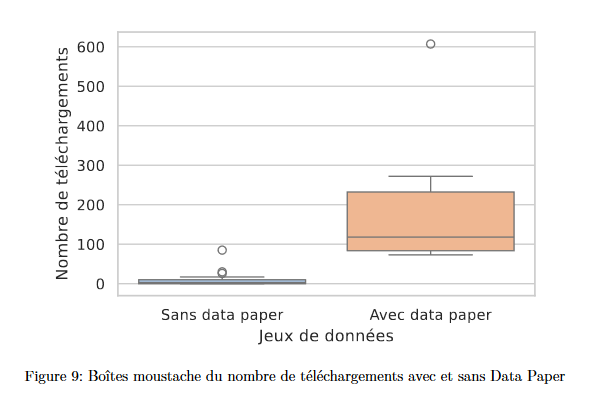
Rémy Decoupes. Analyse de l'impact des data papers de l'UMR TETIS. UMR TETIS, 500 rue Jean-François Breton, 34000 Montpellier. 2024. ⟨hal-04428092v2⟩
Des études encore exploratrices tentent à montrer que les jeux de données associés à un data paper sont plus téléchargés que les jeux qui ne sont pas associés avec un data paper.
Un data paper est un article qui est de plus en plus considéré comme une publication scientifique. Qui dit article, dit potentiel de citation et donc par conséquent plus de visibilité pour vos travaux et vos recherches.
Il s'agit d'une démarche qui s’inscrit dans une politique publique de mutualisation qui favorise l’innovation et la création de nouvelles connaissances.
-
Un enjeu éditorial
Les politiques éditoriales intègrent de plus en plus le dépôt et le partage de données mais dans un contexte d’augmentation des volumes des données, les éditeurs :
- imposent parfois des limites de taille aux données fournies comme matériel supplémentaire des articles (500 MB chez Elsevier),
- externalisent la gestion la curation et le stockage des données en recommandant souvent des entrepôts spécifiques (ex : Groupe Nature).
Certains font de la mise à disposition des données une condition préalable à l’acceptation de l’article (Nature ou PLoS One).
-
Des réponses variables
Les politiques éditoriales des revues sont variables. Certaines revues exigent le dépôt du jeu de données dans un entrepôt spécifique, modéré par la communauté scientifique qui vérifie la conformité des métadonnées par exemple. Les conseils ou interrogations portent sur la présentation du jeu de données, pour en améliorer la qualité. Certaines revues font le choix de ne pas vérifier les données. Ces informations doivent être prises en compte au moment du choix de la revue, notamment pour les questions liées au choix de l’entrepôt : entrepôt national, lié à la communauté, lié à son employeur, etc.
Types de politiques d’archivage des données publiques (ADP)

Source: Scholler et al., 2019
-
