Rédiger et publier un Data Paper
Résumé de section
-
Ce cours a pour but de donner un panorama des questions que soulèvent la rédaction et la publication d'un data paper. Vous trouverez dans cet espace de cours des ressources ainsi qu'un accompagnement méthodologique dans la rédaction d'un data paper.
Objectifs :
à l'issue de la formation, vous serez en mesure de :
- Appréhender les spécificités d'une publication de jeu de données.
- Différencier les différents éléments composants un data paper.
- Appréhender l'écosystème d'outils dédiés à la publication de jeux de données.
- Identifier les questions à se poser dans le choix d'une revue ou d'un entrepôt de données.
- Comprendre l'enjeu de standards de métadonnées partagés et lisibles à la fois par des humains et des machines.
- Appréhender les particularités du processus de soumission d'un data paper.
Plan :
- Introduction
- Structure d'un data paper
- Ouvrir les données de la recherche
- Choisir une revue
- Sélectionner un entrepôt
- Affiner ses métadonnées
- Procédures soumission et évaluation
- Conclusion

Ce cours est en libre accès !
Aucune création de compte ou d'inscription n'est nécessaire, toutefois vous ne pourrez le parcourir qu'en lecture seule.
Pour participer à certaines activités (test, forum...), vous pouvez vous inscrire au cours.
-
Objectif : appréhender le concept de data paper
30 minutes de lecture
-

L’humanité est à un tournant de son histoire. La masse des données acquises est formidable. Il faut de nouveaux instruments pour les simplifier, les condenser ou jamais l’intelligence ne saura ni surmonter les difficultés qui l’accablent, ni réaliser les progrès qu’elle entrevoit et auxquels elle aspire.
-
Définitions

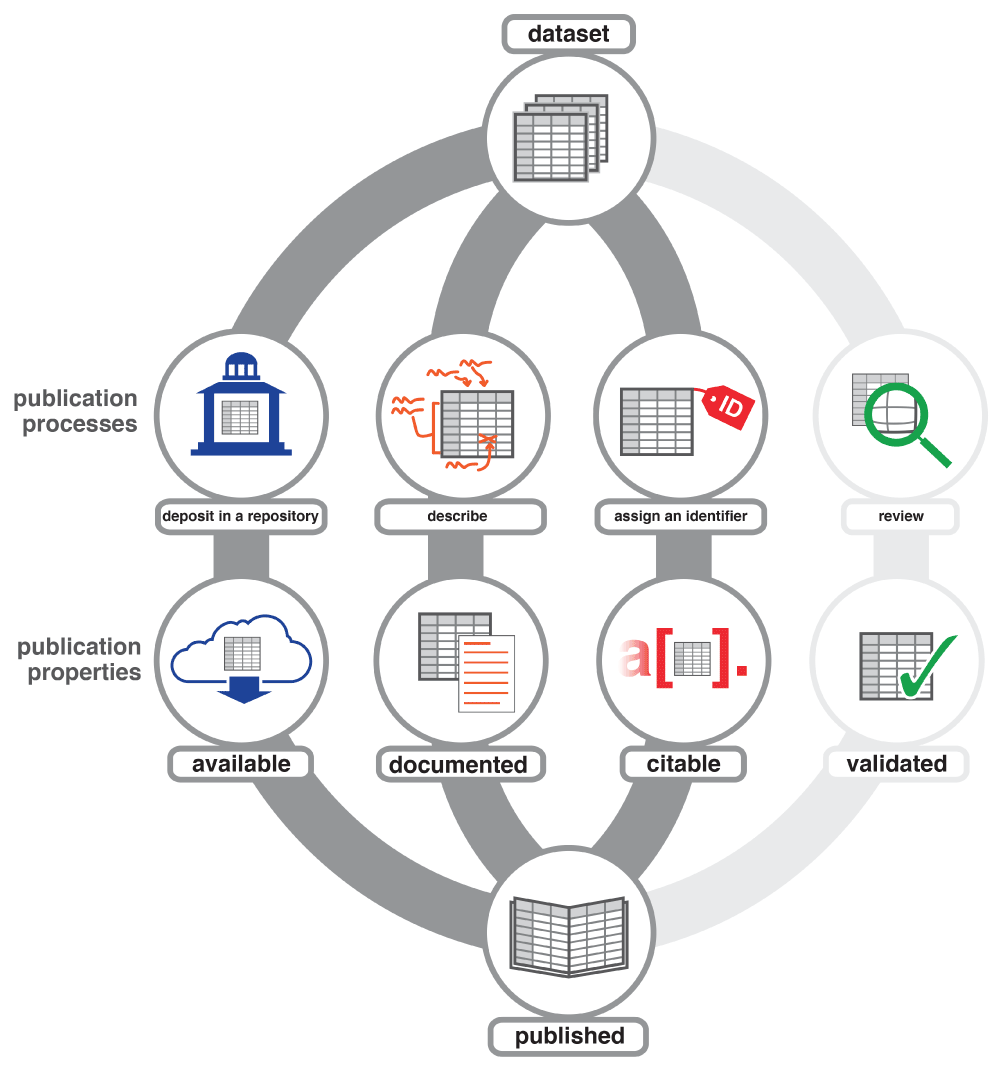
Le Data Paper décrit un jeu de données et son contexte, la méthode d’obtention et le potentiel de réutilisation.
Un data paper est un article décrivant un ou plusieurs jeux de données publié dans une revue à comité de lecture, ainsi que des informations structurées appelées métadonnées.
La préparation, la gestion et la description des données prennent du temps. Les Data papers permettent à cet effort d’être reconnu et valorisé par l’intermédiaire d’un article académique. Contrairement aux articles de recherches classiques, les data papers fournissent une voie formalisée pour le partage des données plutôt qu'un espace où tester des articles de recherche classiques ou présenter de nouvelles analyses.
Nous utilisons ici le terme data paper (article de données en français) mais de multiples appellations existent. Aussi n’hésitez pas à regarder dans les revues que vous avez l’habitude de consulter si une appellation se rapproche de data paper. Voici quelques exemples :
- Data paper (Annals of Forest Science (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet), Zookeys (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet)...),
- Data notes (F1000 Research (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet), Gigascience (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet)),
- Data article (Data in Brief) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet),
- Data descriptor (Scientific Data (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet)),
- Dataset brief (Proteomics (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet)),
- Data in brief (Genomics Data (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet)),
- Database article – Software article (BMC (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet), Chemistry CentralJournal (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet)),
- Data reports (Frontiers in Plant Science (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet)),
- Resource article (Plant Journal (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet)),
- Database paper (Plant & Cell Physiology (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet)),
- Methods, software, databases, and Tools (Plos One (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet) (s'ouvre dans un nouvel onglet)).
Au-delà des données, ce sont également les métadonnées, les logiciels, les scripts permettant l'exploitation des données qui peuvent également être décrits.
-

Un data paper permet « la diffusion des données de recherche, des métadonnées associées, de la documentation d'accompagnement et du code logiciel (dans les cas où les données brutes ont été traitées ou manipulées) en vue d'une réutilisation et d'une analyse, et d’une manière telle qu’elle permette de les découvrir sur le Web et d'y faire référence de façon unique et persistante »
-

L’objectif majeur du Data Paper est la réutilisation des données. Pour réussir, le Data Paper doit appliquer les bonnes pratiques, notamment disciplinaires, en termes de description, documentation et format ouvert, pour que les données soient trouvables, accessibles, compréhensibles, interprétables et réutilisables.
-
Intérêts du data paper
Pour quelles raisons rédiger et publier un data paper :
- Pour valoriser un travail peu visible dans un article scientifique classique.
- Pour garantir la reproductibilité et la qualité des données (leur vérification).
- Pour faciliter la répétabilité des données (leur réutilisation au-delà du champ disciplinaire original).
- Pour permettre d'agréger et d'analyser les données de recherche.
Pour les décideurs publics, les données ouvertes sont une source potentielle d'innovation et de nouvelles connaissances, à condition d'offrir des conditions de réutilisation des données et d'intégrer les citations de data papers dans les critères d'évaluation de la recherche.

-
Un enjeu de reproductibilité
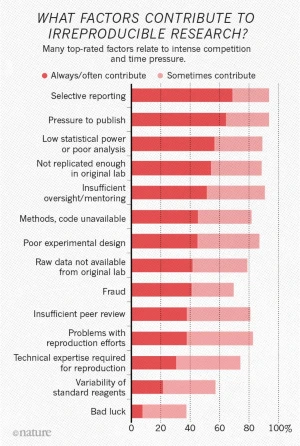
Un data paper ne permet pas seulement la valorisation de données de recherche, il répond aussi à des enjeux de science ouverte et des facteurs de reproductibilité.
En 2016, 1576 chercheurs ont répondu à un court questionnaire en ligne sur la reproductibilité de la recherche. Si plus de 60 % des interrogés soulignent la pression à la publication, la compétition pour les postes, les financements, etc., ils citent de nombreux problèmes concernant autant les données « brutes » que les méthodes et la disponibilité du code.
Source :1,500 scientists lift the lid on reproducibility
-
Nombre de téléchargements sans ou avec data paper
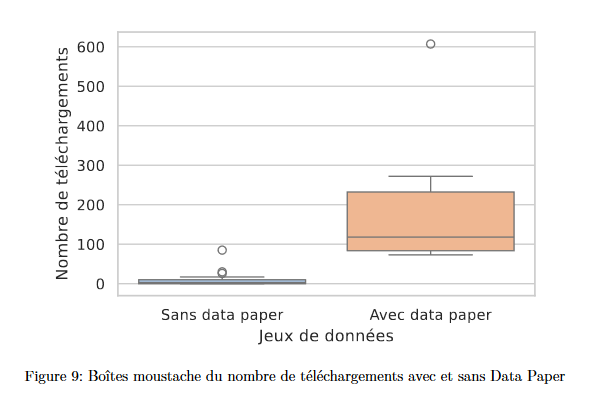
Rémy Decoupes. Analyse de l'impact des data papers de l'UMR TETIS. UMR TETIS, 500 rue Jean-François Breton, 34000 Montpellier. 2024. ⟨hal-04428092v2⟩
Des études encore exploratrices tentent à montrer que les jeux de données associés à un data paper sont plus téléchargés que les jeux qui ne sont pas associés avec un data paper.
Un data paper est un article qui est de plus en plus considéré comme une publication scientifique. Qui dit article, dit potentiel de citation et donc par conséquent plus de visibilité pour vos travaux et vos recherches.
Il s'agit d'une démarche qui s’inscrit dans une politique publique de mutualisation qui favorise l’innovation et la création de nouvelles connaissances.
-
Un enjeu éditorial
Les politiques éditoriales intègrent de plus en plus le dépôt et le partage de données mais dans un contexte d’augmentation des volumes des données, les éditeurs :
- imposent parfois des limites de taille aux données fournies comme matériel supplémentaire des articles (500 MB chez Elsevier),
- externalisent la gestion la curation et le stockage des données en recommandant souvent des entrepôts spécifiques (ex : Groupe Nature).
Certains font de la mise à disposition des données une condition préalable à l’acceptation de l’article (Nature ou PLoS One).
-
Des réponses variables
Les politiques éditoriales des revues sont variables. Certaines revues exigent le dépôt du jeu de données dans un entrepôt spécifique, modéré par la communauté scientifique qui vérifie la conformité des métadonnées par exemple. Les conseils ou interrogations portent sur la présentation du jeu de données, pour en améliorer la qualité. Certaines revues font le choix de ne pas vérifier les données. Ces informations doivent être prises en compte au moment du choix de la revue, notamment pour les questions liées au choix de l’entrepôt : entrepôt national, lié à la communauté, lié à son employeur, etc.
Types de politiques d’archivage des données publiques (ADP)

Source: Scholler et al., 2019
-
-
Objectifs :
- appréhender le concept de Plan de Gestion des Données,
- identifier les éléments composant la structure d'un data paper,
- différencier les différentes politiques éditoriales des revues.
30 minutes de lecture
-
Le plan de gestion des données
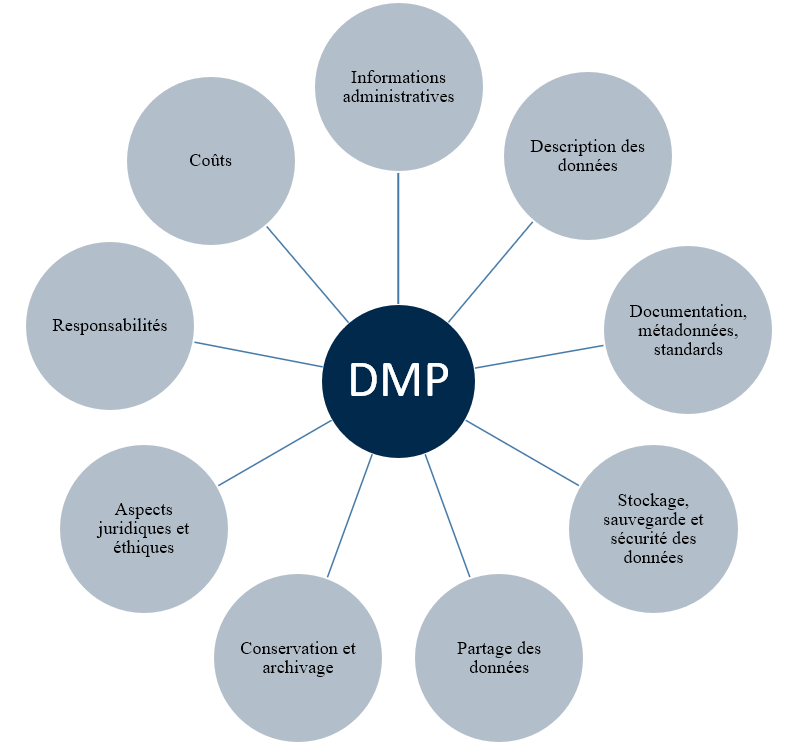
La rédaction d'un data paper permet la valorisation d'une bonne gestion des données de recherche. La gestion des données de recherche peut commencer par la rédaction d'un plan de gestion, autrement appelé Data Management Plan. Ce document souvent vu comme une formalité administrative dans le cadre d'un financement sera une aide pour votre rédaction d'un data paper.
Le Data Management Plan (DMP) ou Plan de Gestion de Données (PGD) est un document synthétique qui aide à organiser et anticiper toutes les étapes du cycle de vie de la donnée. Il explique pour chaque jeu de données comment seront gérées les données d’un projet, depuis leur création ou collecte jusqu’à leur partage et leur archivage.
Il n’existe pas de trame unique, mais de nombreux modèles de DMP ont toutefois été établis par des organismes, instituts, financeurs à destination de leurs utilisateurs : par exemple le modèle de DMP Science Europe ou celui du Cirad. Les outils d’aide à la rédaction comme DMP OPIDoR donnent accès à des modèles et facilitent la rédaction du DMP grâce à des guides et des exemples personnalisés.
Le degré de précision et l’agencement des champs à compléter peuvent varier d’un modèle à l’autre. Dans tous les cas, il s’agit d’une série de questions organisées en grands chapitres. On retrouve systématiquement les mêmes éléments principaux.
-

Valoriser sa gestion des données : du DMP au data paper, il n'y a qu'un pas ?
Le PGD peut être un document exigé, notamment dans le cadre de financements nationaux ou européens. Ce document vise à décrire les jeux de données, la sauvegarde, les exigences éthiques, etc. Un data paper reprend un grand nombre d’informations présentes dans un PGD, n’hésitez donc pas à vous appuyer sur ce document.
-
Structure d'un data paper
Ce type d'article n’est pas construit sur le schéma “hypothèse / résultats” comme dans un article scientifique traditionnel, mais plutôt en complément. Dans un data paper, on peut par exemple mettre à disposition le code utilisé, ce qui n’est pas quelque chose que l’on met forcément dans un article. Il faut donc s’interroger sur les données que l’on souhaite transmettre, ainsi que leurs canaux de transmission (entrepôts de données, articles, data paper).
Voici les différents points à renseigner dans un data paper. Cette liste n'est pas exhaustive, ces éléments et leur succession peuvent varier d'une revue à une autre.
Le titre est le premier contact du lecteur avec votre article. Il doit être court afin d’être attractif pour le lecteur et les moteurs de recherche et contenir les termes spécifiques comme data/données ou dataset/jeux de données. Il est recommandé de ne pas donner au data paper le même titre que celui du jeu de données pour différencier les deux ressources en cas de recherche d’information sur le web et de citations.
On parle d'auteur pour les personnes qui rédigent le data paper, là où le terme contributeur pourra désigner les personnes ayant participé à la collecte des données.
- Nom(s) de l'auteur ou des auteurs et leur identifiant ORCID
- Affiliation(s) et mail de contact.
- Rôle(s) des auteurs.
Les différentes dates du processus de publication de l'article :- date de la soumission,
- date de l'acceptation,
- date de la publication.
Vous pourrez constater que ce processus de publication est souvent plus rapide que pour un article classique.
Un bref résumé (court en général, environ 300 mots) du jeu de données décrivant ce que couvrent les données, la manière dont elles ont été collectées, dont elles sont stockées, et présentant leur potentiel de réutilisation. Précisez les mots-clés associés. Vous pouvez mettre par exemple, les mots clés que vous n’avez pas pu mettre dans le titre ici. Rappelez vous que le résumé peut être lu sans l’article.
Vous pouvez aussi proposer un résumé graphique ou visuel.
L'introduction présente l’étude dans laquelle s’insère le jeu de données décrit (contexte, enjeux), les questions de recherche à l’origine de la collecte ou la production des données, ainsi que l’intérêt apporté par cette collecte ou production (originalité, importance et potentiel d’utilisation en recherche).
Vous pouvez également préciser le contexte de production à travers les questions suivantes :- Ces données ont-elles été produites dans le cadre d'un projet de recherche, d'une thèse, de travaux en cours?
- Sont-elles utilisées dans un ou des articles de recherche ?
La description des données a pour objectif de faciliter leur réutilisation : leur structure, le format, l’accès à ces données, l’explication des données qui peuvent paraître aberrantes…
Il est possible de compléter par des informations sur la fiabilité et la rigueur des données, si besoin en accompagnant de l’analyse, de la discussion de figures / tableaux ainsi que la validation de la procédure de collecte de données, analyses statistiques de l'erreur expérimentale…
- Le nom du/des jeu(x) de données déposés dans un entrepôt de données.
- Informatique, économie, sociologie…
- Catégorie disciplinaire : informatique théorique, économie internationale, sociologie des sciences et des techniques…
Format des données
- "Raw", analyzed, filtered,...
- Par exemple, CSV, JPEG…
- Par exemple, un tableau, une image, un graphe, un texte...
Méthodes d'acquisition des données
- Enquête, observation, instrumentales,...
Lieu d'acquisition des données
- Pays, région, ville,...
- Les dates de début et de fin de création des données.
- Le(s) nom(s) de toute personne ayant contribué à la création du jeu de données (qui peut ne pas être un auteur de l’article de données), y compris leurs rôles et affiliations.
- La ou les langue(s) utilisée(s) dans le jeu de données (par exemple, pour les noms de variables).
- La licence ouverte sous laquelle les données ont été déposées (par exemple, CC0).
- DOI, Handle, Purl, ARK
- Le nom de l’entrepôt où sont déposées les données.
- La date à laquelle le jeu de données a été publié dans l’entrepôt.
Une description des méthodes utilisées, du matériel employé, des protocoles expérimentaux déployées de façon à permettre la reproduction de l’étude à l’origine des données décrits (méthode d'échantillonnage, procédures de contrôle…).
Il est possible de compléter par des informations sur la fiabilité et la rigueur des données, si besoin en accompagnant l’analyse et la discussion de figures et de tableaux et la validation de la procédure de collecte de données, analyses statistiques de l'erreur expérimentale…
Recommandations :
- Justifiez l'utilisation d'un logiciel (prioritaire ou autre), ou d'un format de fichier spécifique.
- Indiquez la présence ou l'absence de tests de reproductibilité ainsi que de la présence données non reproductibles.
- Évitez autant que possible les fichiers propriétaires. Retrouvez la liste des formats ouverts et fermés via le bouton ci-dessous.
En rédigeant un data paper, vous contribuez aux enjeux de science ouverte et de capitalisation des connaissances, en permettant à des collègues de les mobiliser dans leur propre recherche. Cette section peut également inclure les limitations ou les barrières potentielles à la réutilisation de ces données.Qui a fait quoi ? Cette question éthique définie par la COPE par exemple vise à clarifier les rôles et le niveau d'implication de chaque auteur. Vous pouvez retrouver la liste de différents types de contributions, comme par exemple la conceptualisation, la méthodologie, la supervision, l'écriture de l'article original, la curation des données, etc. Vous pouvez reprendre ici les catégories proposées par la revue, si elle l'exige.
Si les données résultent d'une recherche financée, indiquer le nom du financeur et l'identifiant de la subvention.Si l'un des auteurs a des conflits d'intérêts, ceux-ci doivent être déclarés, s'ils ont influencés son travail. S'il n'y a pas de conflits d'intérêts à déclarer, la déclaration suivante doit être présente : « L'auteur (ou les auteurs) déclare(nt) ne pas avoir de conflits d'intérêts à déclarer ».Les revues peuvent limiter ou autoriser l'utilisation de l'IA générative pour l'amélioration de la lisibilité et de la langue. En cas d'utilisation, l'usage doit se faire sous supervision et contrôle humain, il n'est donc pas possible d'utiliser une IA dans le traitement des données.Cette partie permet de rappeler la référence à un article et le dépôt des données dans un entrepôt. - Nom(s) de l'auteur ou des auteurs et leur identifiant ORCID
-
Data policy standardisation
Le nombre d’informations requises augmente en fonction du niveau.
Tableau 1 : les types de politiques et leurs caractéristiques
Obligatoire

Optionnel

Non requis

Caractéristiques
Explication
Type 1
Type 2
Type 3
Type 4
Instructions sur le partage des données via des entrepôts
Les détails du partage via les dépôts sont mentionnés dans le guide de soumission de la revue.

Citation des données permise
Le guide de rédaction d'un article permet aux auteurs de citer des ensembles de données accessibles au public dans des listes de référence.
Service d'aide par les éditeurs
Coordonnées du service d’assistance incluses dans les informations de la revue pour les auteurs.
Dépôts de données publiques et contrôles de l’identifiant du jeu de données pour des types spécifiques de données
Vérification du dépôt des données dans le cadre du processus de publication par la communauté scientifique concernée.
Déclaration de disponibilité des données
Dans les articles publiés, déclaration indiquant comment accéder aux données.
Dépôt de données publiques et identifiant du jeu de données requis et vérifié
Données rendues publiques et identifiants des données fournis pour tous les articles publiés (avec des exceptions pour les données sensibles/personnelles).
Citation des données
Références de données pertinentes fournies et vérifiées.
Vérification des données par les pairs
Des recommandations sur l’accès aux fichiers de données et leur examen sont fournis pour la relecture par les pairs.
Entrepôt de données intégré
Système de soumission et/ou d’examen intégré, avec un entrepôt spécifique à la revue tel que figshare.
Source : traduit de l'article Hrynaszkiewicz et al, 2017
-
Un data paper accompagne l'ouverture d'un jeu de données selon les principes FAIR. Afin d'expliciter les méthodes de collecte, de traitement et de contrôle de qualité des données pour favoriser leur réutilisation, il est alors nécessaire d'assurer la découvrabilité des données via un entrepôt de données.
Objectif : identifier les outils de l'écosystème dédié aux données de la recherche.
5 minutes de lecture
-
Les données de recherche déposées dans un entrepôt peuvent être explorées via des outils de visualisation des données. Certains entrepôts mettent à disposition des données sans partager un standard commun. Dans l’exemple suivant de GBIF, ce standard commun permet de visualiser les données de recherche dans un entrepôt qui est mentionné dans le data paper. En effet les revues qui publient les data paper sont liées à cet entrepôt pour la mise à disposition des données. Le data paper permet de documenter l'acquisition, les méthodes, les scripts liés aux données déposées dans l'entrepôt. Un entrepôt est donc un outil qui permet la mise en ligne des données, leur partage, mais aussi leur visualisation dans certains cas.
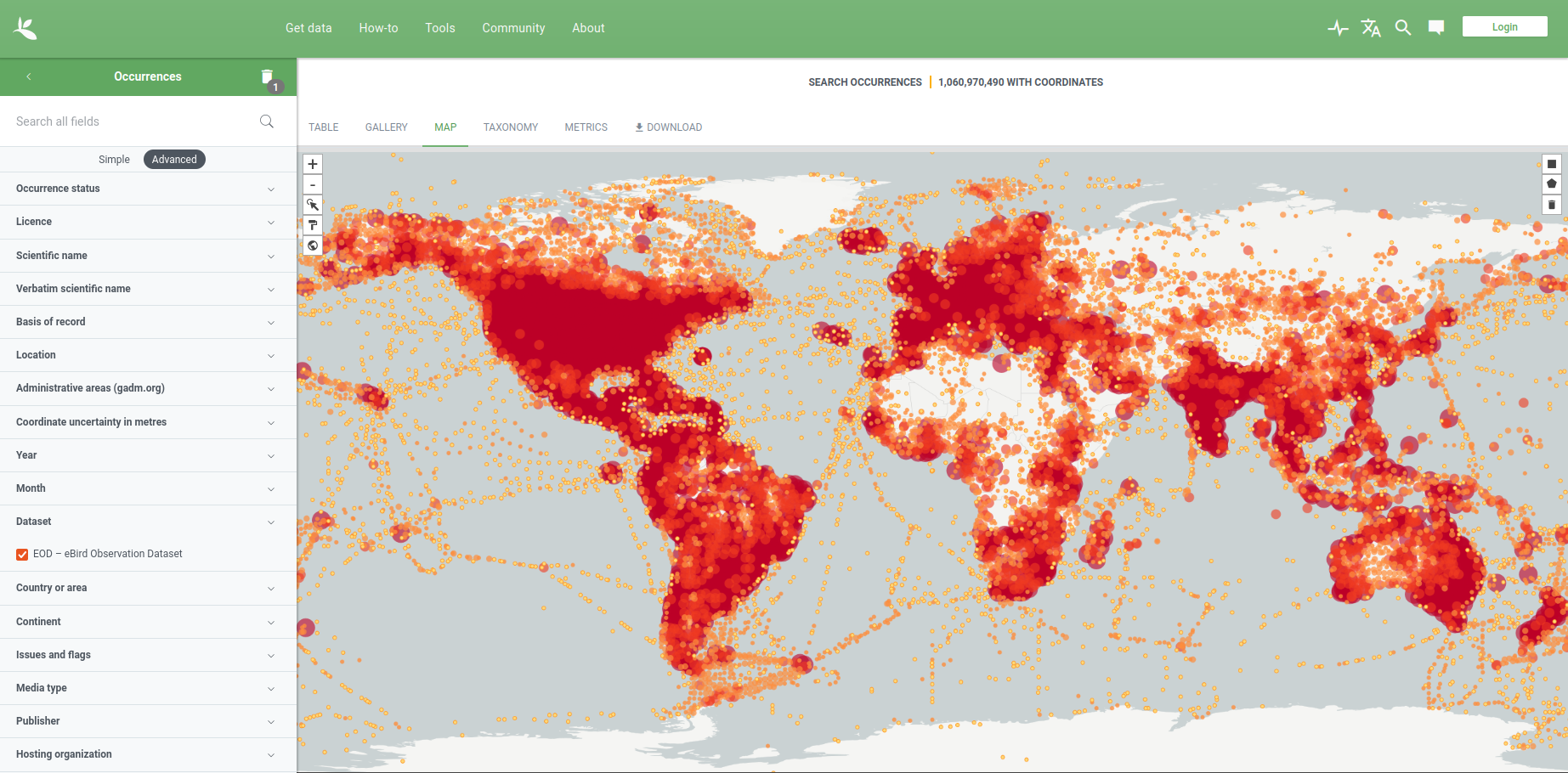 Capture d'écran de l'interface de visualisation GBIF
Capture d'écran de l'interface de visualisation GBIF -
On retrouve dans les data paper, comme le Biodiversity data journal, un standard de métadonnées commun à la communauté (Darwin Core) et un lien vers le jeu de données déposé dans un entrepôt.
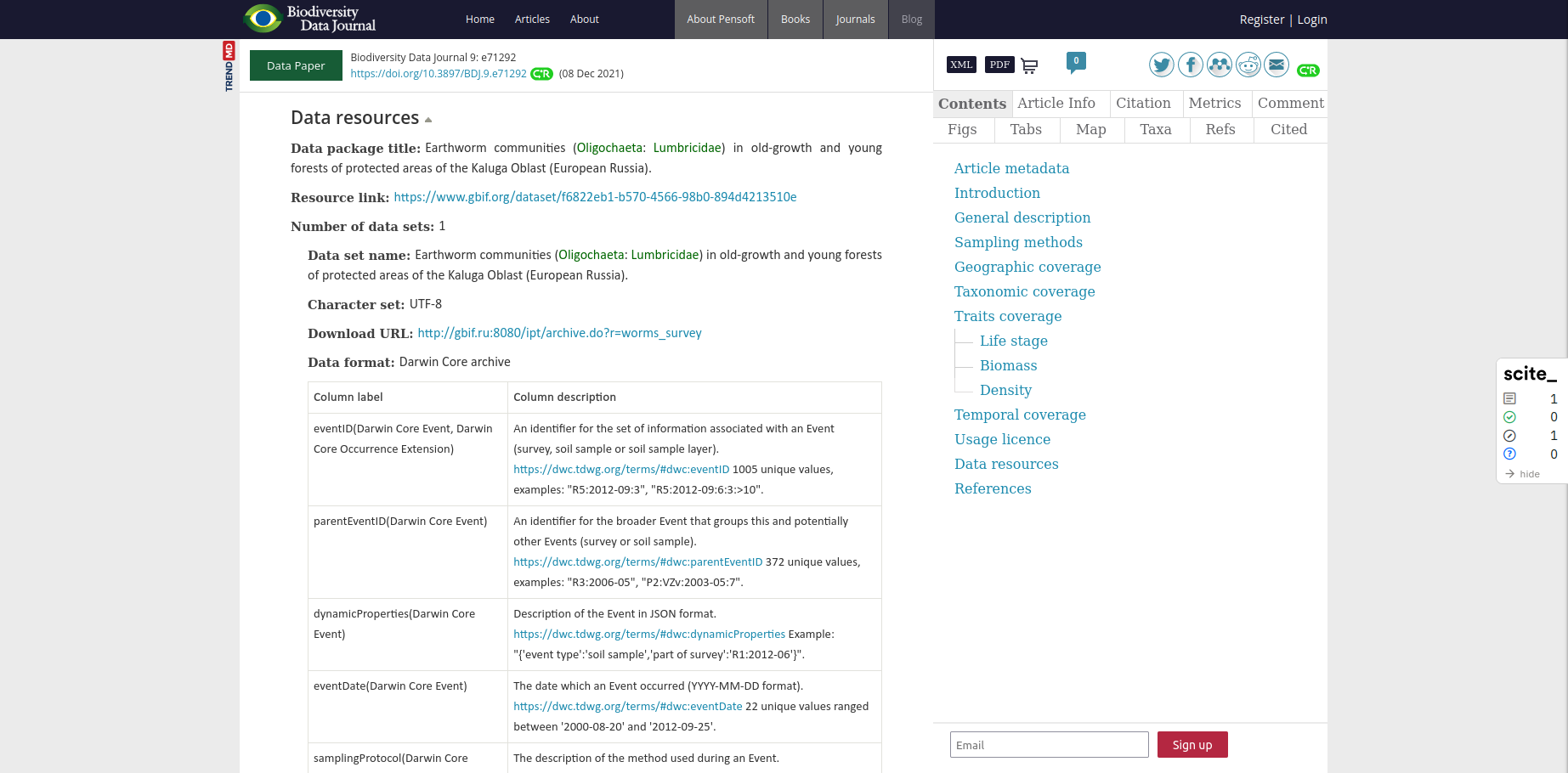 Source : Shashkov et al., 2021
Source : Shashkov et al., 2021Il est donc important d'avoir en tête qu'en amont de la rédaction d'un data paper, les chercheurs doivent déposer toutes les données et toute la documentation associée.
-
Données publiées
L’image présente ici la différence entre des données de recherche validées, préservées, citables et créditées. Toute la documentation qui accompagne les données peut varier en fonction du choix de l’outil de mise à disposition des données. Il faut donc distinguer des données “publiées” lorsque les données sont accessibles au public et réutilisables, mais ce terme peut ou non impliquer que les données ont été examinées par des pairs. L’ "examen des données par les pairs" comme nous avons pu le constater précédemment dans les attentes des revues peut être variable. Il en est de même pour un entrepôt de données.
La question devient d’autant plus complexe que les données peuvent être dynamiques ou appartenir à une base plus large. Leur enrichissement continu pose alors de nouvelles questions sur ce que sont les données de recherche.
-
Objectifs :
- appréhender le concept de curation des données,
- identifier les critères de sélection d'un entrepôt de données.
25 minutes de lecture
-
Curation des données
Une fois les données publiées, se pose alors la question de leur conservation. C'est là qu'entre en scène un nouvel acteur : l’archiviste mais aussi des scientifiques..

La curation consiste à vérifier la conformité du jeu de données aux règles établies par le Centre de ressources entrepôt-catalogue et par l’administrateur de la collection. Elle vise à assurer une bonne compréhension des données publiées et à favoriser leur réutilisation, en accord avec les principes FAIR.
La conservation est la gestion et la promotion de l’utilisation des données dès leur création, afin de s’assurer qu’elles sont adaptées à un usage contemporain et disponibles pour être découvertes et réutilisées… Des niveaux de conservation plus élevés impliqueront également le maintien de liens avec l’annotation et avec d’autres documents publiés.
Les activités de conservation comprennent :
- L’archivage : une activité de conservation qui garantit que les données sont correctement sélectionnées, stockées, accessibles et que leur intégrité logique et physique est maintenue dans le temps, y compris la sécurité et l’authenticité.
- La préservation : une activité d’archivage dans laquelle des éléments spécifiques de données sont conservés dans le temps de sorte qu’ils puissent toujours être accessibles et compris grâce aux changements technologiques.
-
Critères de sélection
Avant de choisir l'entrepôt pour vos données, pensez à vérifier l'ensemble de ces points :
Quel est le nom de l’entrepôt et son adresse ? Vous pouvez identifier ici le type de propriétaire de l'entrepôt (institution, entreprise commerciale, etc.).
Comme pour une revue scientifique classique, un entrepôt peut avoir des attentes, soit en termes de disciplines, de documentation, de métadonnées, etc. Par exemple, voici la documentation pour l'entrepôt Nakala, développé par Huma-Num. D'autres comme Pangea (pengaea.de) mettent à disposition un wiki pour le dépôt des données.
Existe-t-il une personne contact pour l'entrepôt, si besoin d'assistance ? Si vous n'êtes pas familier avec ce genre de procédure, il peut être intéressant de privilégier un entrepôt proposant ce type d'accompagnement, comme sur Recherche Data Gouv par exemple.
Il existe différents types d'entrepôts de données :- Généraliste : Zenodo
- Disciplinaire : Nakala, le Centre de Données astronomiques de Strasbourg, etc.
- Institutionnel : Recherche data gouv
- Autre : git
 Existe il une certification de l'entrepôt comme "Core Trust seal"?
Existe il une certification de l'entrepôt comme "Core Trust seal"? La question est quelles sont les données acceptées, comme des formats spécifiques ou encore des données toujours en cours de traitement.
- un embargo possible, si vous ne souhaitez pas rendre disponibles immédiatement vos données ?
- un accès uniquement aux métadonnées ?
- un accès restreint, uniquement sur demande ?
- Quelles sont les attentes en termes de documentation ?
- Les métadonnées sont elles libres ou existe il un standard de métadonnées à utiliser, un vocabulaire spécifique ?
- DOI
- Handle
Quel est le coût de l'entrepôt pour le stockage de vos données ?
- La taille du jeu de données fait elle varier le coût ?
- Quelle est la durée du stockage des données ? La question ici est de définir la pérennité des données.
-
Dataverse Project
Dataverse Project est un logiciel de référentiel de données de recherche open source qui s'adresse aux chercheurs, aux revues, aux établissements ainsi qu'aux développeurs.
Dans le dataverse il est possible de déposer et associer à la fois les données, de la documentation, les codes et les data files, pour former un ensemble complet. Comme dans la plupart des entrepôts de données, le format utilisé est le Dublin core ou du Dublin Core enrichi (métadonnées associées directement).
Pour en savoir plus sur cet outil, vous pouvez consulter le guide Dataverse Project (s'ouvre dans un nouvel onglet)
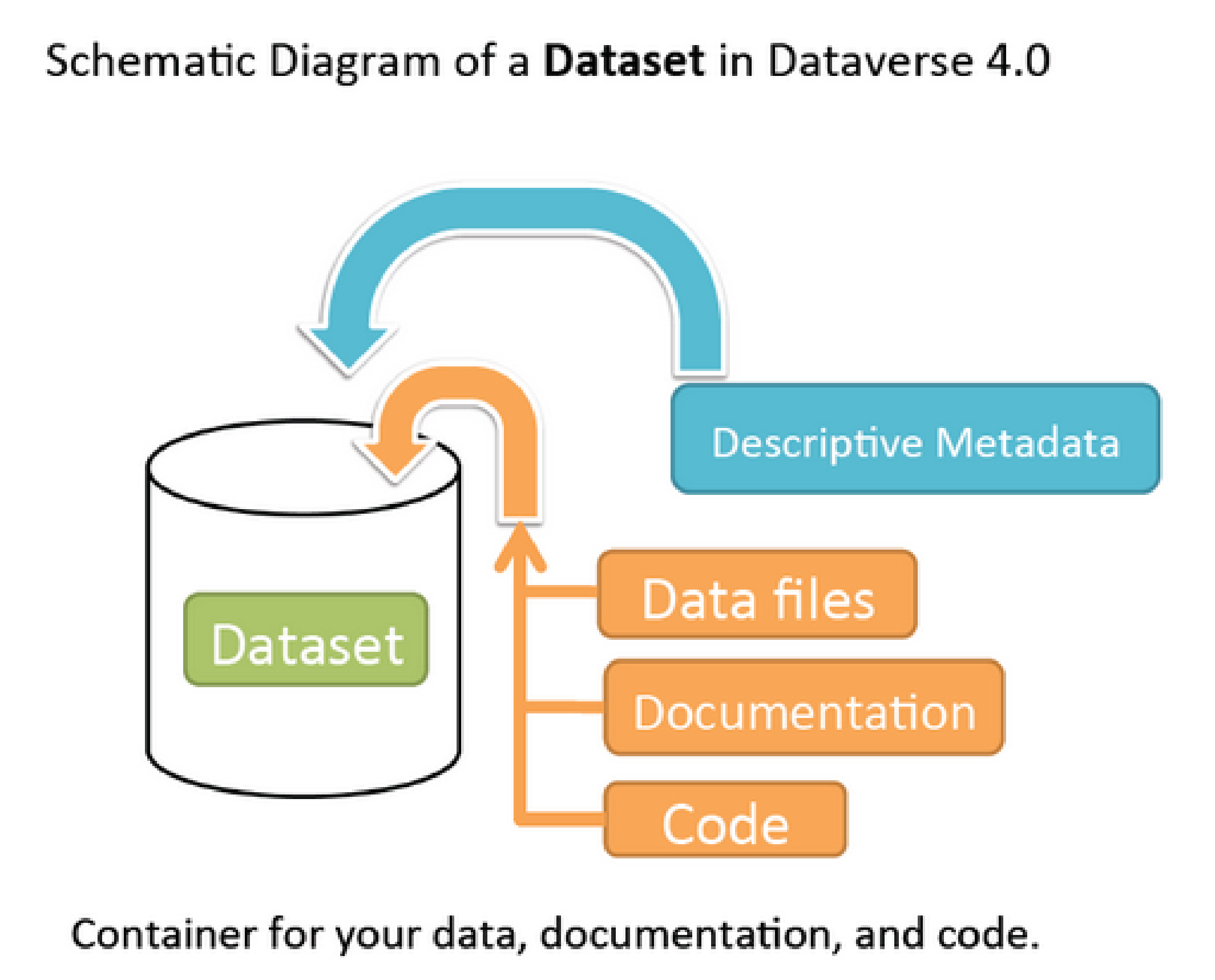
-
Fichier Readme
Un fichier "Lisez-moi" (Readme) donne des informations sur la façon d’interpréter un fichier de données et diminue les chances que les données soient mal comprises et/ou improprement utilisées par d’autres chercheurs. Il contient autant d’informations que possible sur les fichiers de données pour permettre aux autres de comprendre les données.Source : Données de recherche - Polytechnique MontréalNommez-le toujours README.txt ou README.md (Markdown) afin de respecter la nomenclature en vigueur et pensez à créer un fichier README.txt pour chacun de vos jeux de données.
Télécharger le gabarit recommandé de fichier Lisez-moi.

-
Objectifs :
- appréhender l'enjeu des standards de métadonnées partagées dans une communauté de recherche,
- comprendre l'enjeu d'accompagner ses données par des métadonnées, lisibles par des humains et des machines.
15 minutes de lecture
-

Métadonnées
Les métadonnées, que l’on peut définir simplement comme « des données sur les données », sont un moyen de nommer les choses et de représenter les données et leurs relations.
-
Exemple de standard de métadonnées créé par une communauté scientifique

Document, Discover and Interoperate (DDI)
La Data Documentation Initiative (DDI) est une norme internationale pour décrire les données produites par les enquêtes et d’autres méthodes d’observation dans les sciences sociales, comportementales, économiques et de la santé. La DDI est une norme gratuite qui peut documenter et gérer différentes étapes du cycle de vie des données de la recherche, comme la conceptualisation, la collecte, le traitement, la distribution, la découverte et l’archivage. La documentation des données avec la DDI facilite la compréhension, l’interprétation et l’utilisation -- par les personnes, les systèmes logiciels et les réseaux informatiques.
-
 Source : Tuto@Mate, Danciu et Mairot,ressource : https://doi.org/10.5281/zenodo.4309815
Source : Tuto@Mate, Danciu et Mairot,ressource : https://doi.org/10.5281/zenodo.4309815La spécification DDI, écrite en XML, fournit un format pour le contenu, l’échange, et la conservation des informations liées à une étude, ses résultats et les données de l’étude elles-mêmes.
Depuis 1995, des membres de diverses institutions se réunissent pour développer ce standard. N'hésitez pas à consulter la page Wikipédia dédiée à ce standard pour en savoir plus.
-
Exemple de standard de métadonnées embarquées
Exchangeable image file format (EXIF)
EXIF est un format de fichier pour les images, utilisé par les appareils photographiques numériques, qui permet de décrire la nature d’autres données pour une réutilisation pertinente, (qui, quand, où, comment, pourquoi) par exemple :
- auteur,
- origine,
- nature,
- structuration,
- modèles,
- règles.
Il permet de renseigner manuellement ou automatiquement les métadonnées (carte d’identité des données, ressources, documents…) afin de faciliter la recherche d'informations, la réutilisation et l'identification des données pour les créateurs ou encore des tiers.
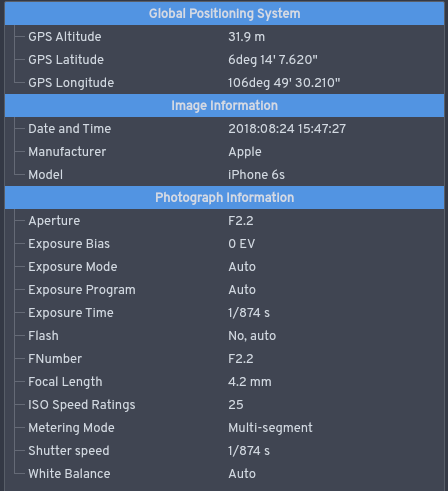 Par exemple, une suite de chiffres dans un tableau devient incompréhensible si l’on ne sait pas à quoi correspondent les abscisses et les ordonnées, dans quel but le tableau a été créé et à quelle date. Quand vous créez des métadonnées, vous documentez vos données, ce qui vous permet de :
Par exemple, une suite de chiffres dans un tableau devient incompréhensible si l’on ne sait pas à quoi correspondent les abscisses et les ordonnées, dans quel but le tableau a été créé et à quelle date. Quand vous créez des métadonnées, vous documentez vos données, ce qui vous permet de :- retrouver et réutiliser facilement vos propres données ;
- découvrir, évaluer, et réutiliser les données produites par d’autres ;
- aider les autres à découvrir, reproduire, réutiliser, et citer vos données ;
- faciliter la préservation des données numériques, alors que les logiciels et les formats ne cessent d’évoluer au fil du temps.
La description de ces données permet de donner plus d'informations sur:- le contenu intellectuel : titre, résumé, domaine de recherche, mots-clés, type de ressource ;
- le contexte de production : date, créateur, projet, financeur, procédés de création ;
- les caractéristiques techniques des fichiers et des données : formats, taille, organisation ;
- les propriétés et droits d’usage : détenteurs des droits, conditions d’accès, conditions de partage, conditions d’usage, outils spécifiques pour accéder ou lire les données.
-
Objectifs :
- différencier les types de revues dédiées aux data paper,
- identifier les critères de sélection d'une revue.
30 minutes de lecture
-
Critères des choix de la revue
Pour trouver la revue qui correspond à vos besoins, à partir de la liste ci-dessus, répondez aux questions suivantes :
Liste des critères
Pour trouver la revue qui correspond à vos besoins, à partir de la liste ci-dessus, répondez aux questions suivantes :
- Quel est le type de cette revue ?
- À qui s'adresse cette revue ?
- Quelle est la renommée de cette revue ?
- La revue est-elle indexée dans une base de données bibliographiques (Scopus, Web of Science) ou des moteurs de recherche spécialisés (Dimensions par exemple)?
- Les données doivent elles êtres traduites en anglais?
- Pouvez-vous soumettre l’article en français?
- Les données sont-elles mises à disposition comme matériau supplémentaire, dans un entrepôt institutionnel, généraliste ou disciplinaire?
- Généraliste : Zenodo
-
Disciplinaire : Nakala
-
Institutionnel : Recherche data gouv
-
Autre : git
-
Quel est le volume de données autorisé?
-
Le format recommandé?
-
Les licences proposées,?
-
La pérennité de l’archivage?
-
La certification ?
-
Le standard de métadonnées est-il Libre ou imposé?
- Quelles sont les options d'identifications proposées par l'entrepôt (DOI, Handle) ?
-
La relecture est-elle en double aveugle ou ouverte?
Quel est le coût de l'entrepôt pour le stockage de vos données ?
- Taille du jeu de données
- Durée du stockage
-
Y a-t-il des templates ou des modèles proposés ?
Pour résumer :
- Quel est l'usage en vigueur dans ma discipline ?
- Quelle est la visibilité de la revue ?
- Quel est le mode de relecture (peer-reviewing) ?
- Où sont stockées les données et comment y accéder ?
- Quelle est le niveau de pérennité et de fiabilité des données ?
- Quel est le public, le lectorat ?
-
Focus sur deux revues
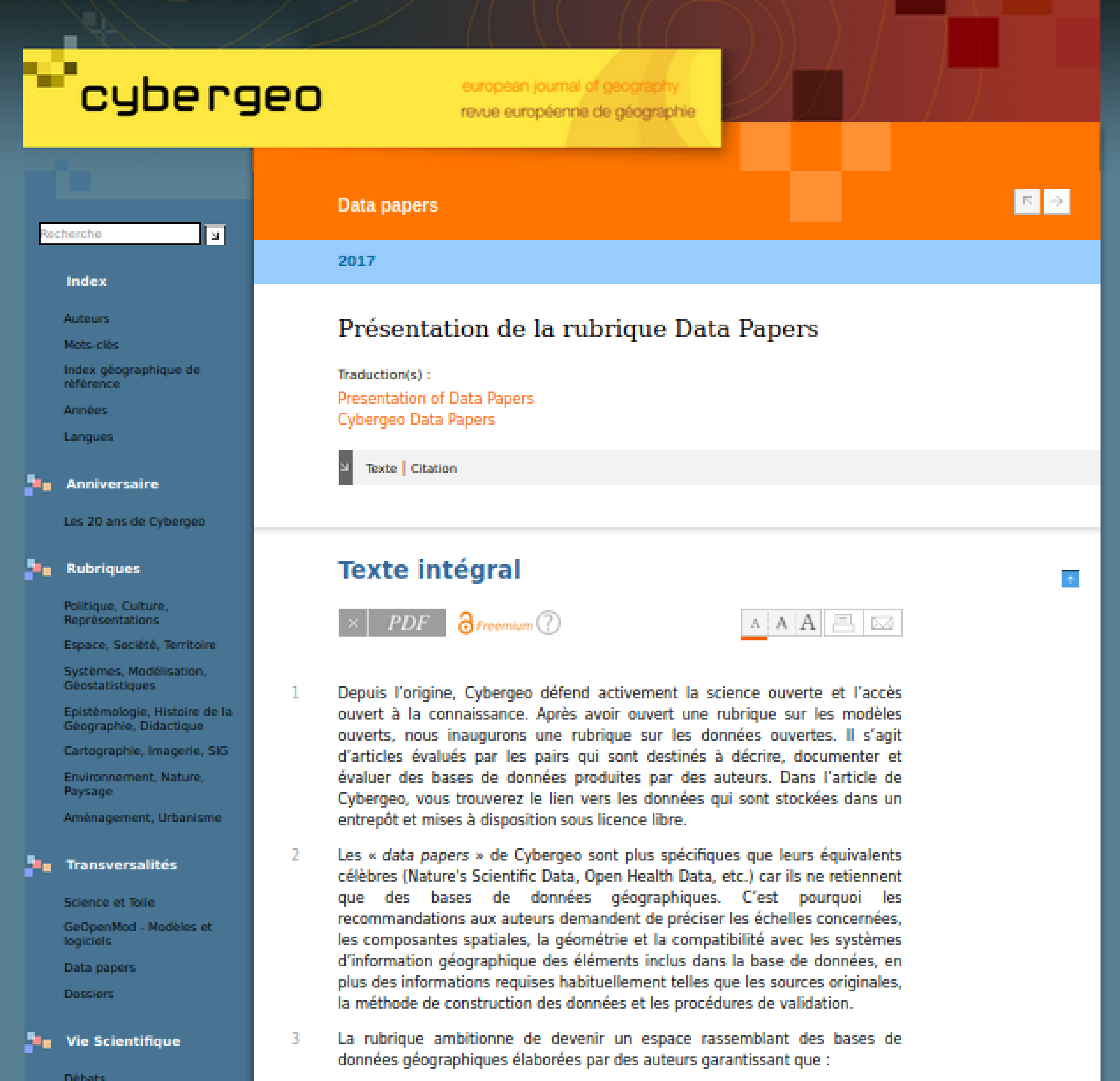
Cybergeo
Depuis ses débuts en 1996 Cybergeo défend activement la science ouverte et l’accès ouvert à la connaissance. Après avoir ouvert une rubrique sur les modèles ouverts, ils ont inauguré une rubrique sur les données ouvertes. Il s’agit d’articles évalués par les pairs qui sont destinés à décrire, documenter et évaluer des bases de données produites par des auteurs.
Dans les data papers de Cybergeo, vous trouverez le lien vers les données qui sont stockées dans un entrepôt et mises à disposition sous licence libre. Ce sont des bases de données géographiques. C’est pourquoi les recommandations aux auteurs demandent de préciser les échelles concernées, les composantes spatiales, la géométrie et la compatibilité avec les systèmes d’information géographique des éléments inclus dans la base de données, en plus des informations requises habituellement telles que les sources originales, la méthode de construction des données et les procédures de validation. Ils publient depuis 2017 des data papers.
-
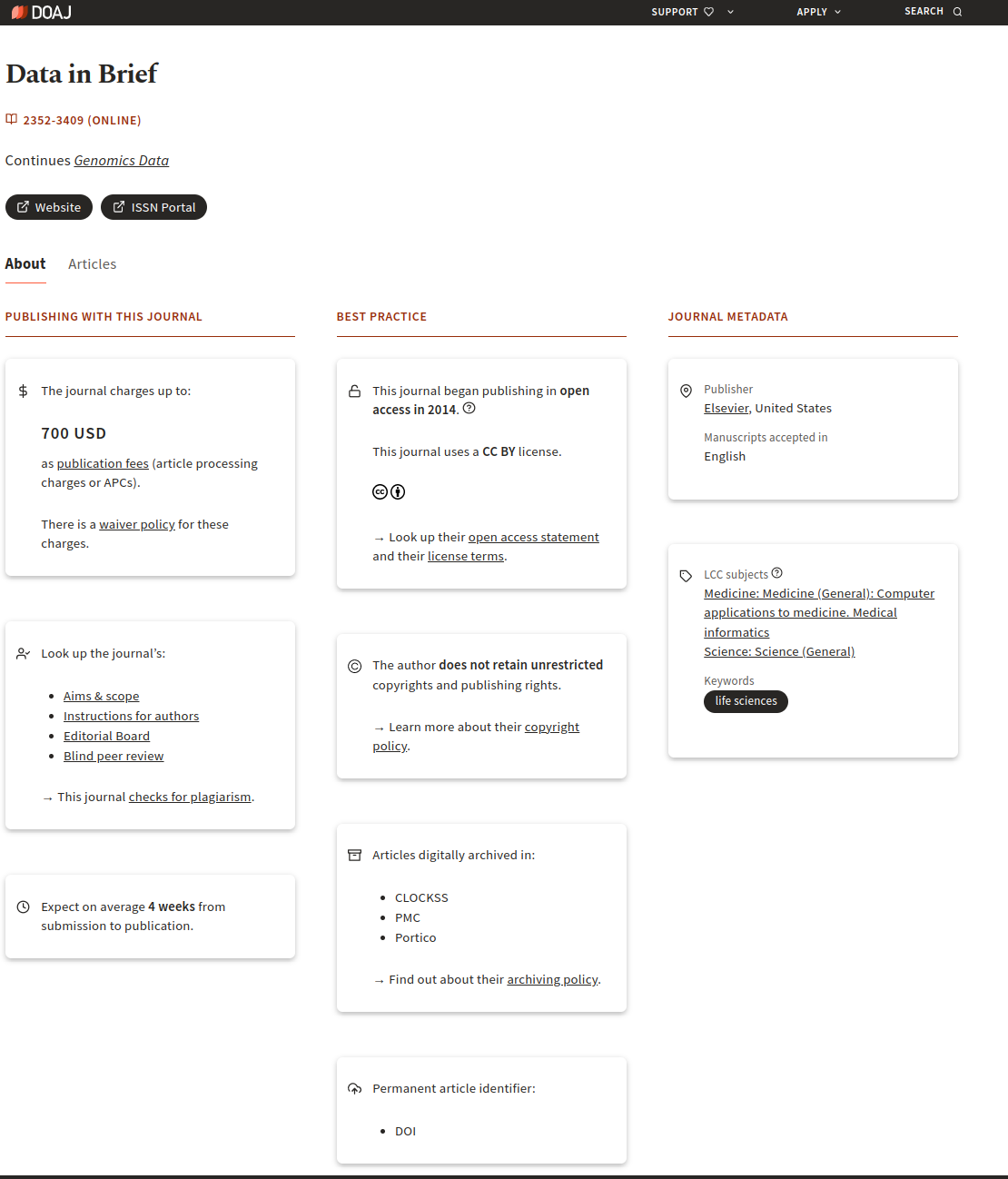
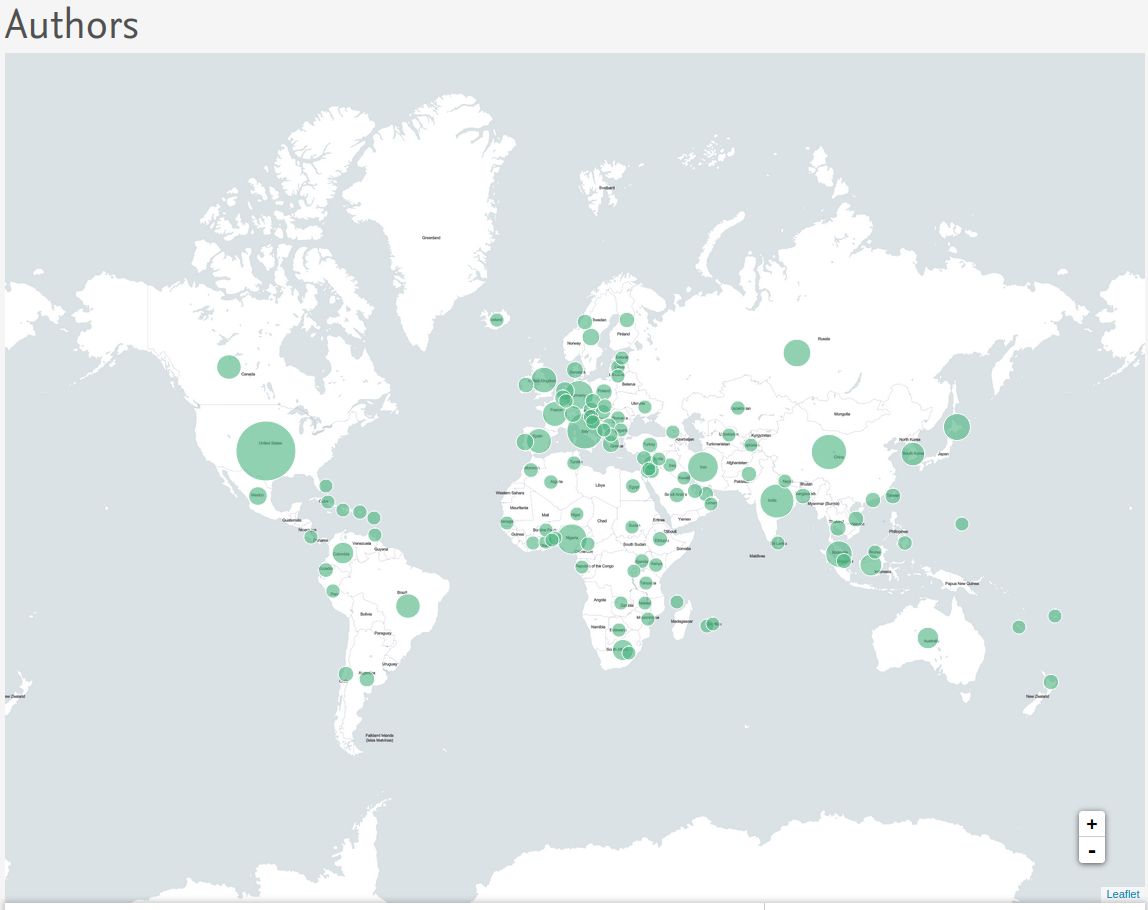
Data In Brief
L’image suivante présente une capture d’écran du site de la revue Data in brief. Une carte présente la répartition géographique des auteurs et trois sous-rubriques mentionnent les “Aims and scope”; “Editorial board” et “Abstracting and indexing”. Lisez ces points avant de soumettre pour la première fois dans une revue.
Vous pourrez également trouver des informations vous aidant à produire votre data paper.

Recommandations
On voit que la publication d'un article dans la revue Data In Brief est très formalisée, il faut donc bien prendre connaissance de son template avant de se choisir ce data journal par exemple. Tous les éléments attendus par la revue et les relecteurs sont listés. Leur oubli peut aboutir au rejet de votre article.
En consultant le template de 2024 de Data in Brief ci-dessous vous verrez des recommandations (comme indiquer "data" dans le titre) qui sont toujours utiles même en français et qui peuvent être une aide pour vous aider à structurer votre propos si la revue dans laquelle vous soumettez ne propose pas de modèle et que vous ne savez pas trop comment commencer.

-
Objectif : découvrir les modalités du processus de soumission d'un data paper.
10 minutes de lecture
-
5 minutes de lecture
-
10 minutes de lecture
Dans cette partie nous vous proposons de tester vos connaissances, à travers une étude de cas. Si vous obtenez un minimum de 60% de bonnes réponses au test, vous pourrez obtenir un badge attestant de votre bonne compréhension des enjeux et du processus de publication d'un Data Paper. Pour cela vous devez être inscrit·e au cours.