3. Ouvrir les données de la recherche
Résumé de section
-
Un data paper accompagne l'ouverture d'un jeu de données selon les principes FAIR. Afin d'expliciter les méthodes de collecte, de traitement et de contrôle de qualité des données pour favoriser leur réutilisation, il est alors nécessaire d'assurer la découvrabilité des données via un entrepôt de données.
Objectif : identifier les outils de l'écosystème dédié aux données de la recherche.
5 minutes de lecture
-
Les données de recherche déposées dans un entrepôt peuvent être explorées via des outils de visualisation des données. Certains entrepôts mettent à disposition des données sans partager un standard commun. Dans l’exemple suivant de GBIF, ce standard commun permet de visualiser les données de recherche dans un entrepôt qui est mentionné dans le data paper. En effet les revues qui publient les data paper sont liées à cet entrepôt pour la mise à disposition des données. Le data paper permet de documenter l'acquisition, les méthodes, les scripts liés aux données déposées dans l'entrepôt. Un entrepôt est donc un outil qui permet la mise en ligne des données, leur partage, mais aussi leur visualisation dans certains cas.
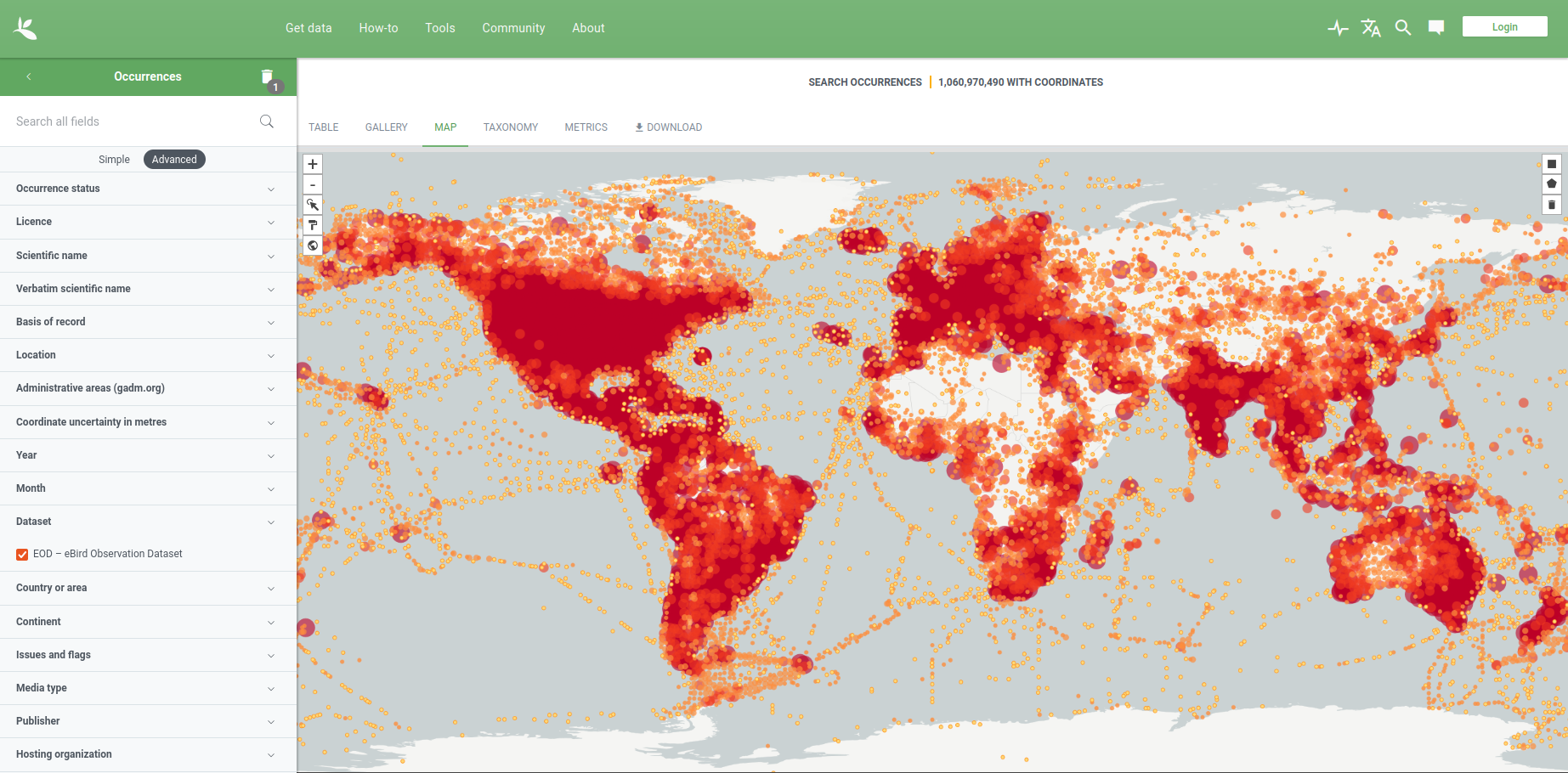 Capture d'écran de l'interface de visualisation GBIF
Capture d'écran de l'interface de visualisation GBIF -
On retrouve dans les data paper, comme le Biodiversity data journal, un standard de métadonnées commun à la communauté (Darwin Core) et un lien vers le jeu de données déposé dans un entrepôt.
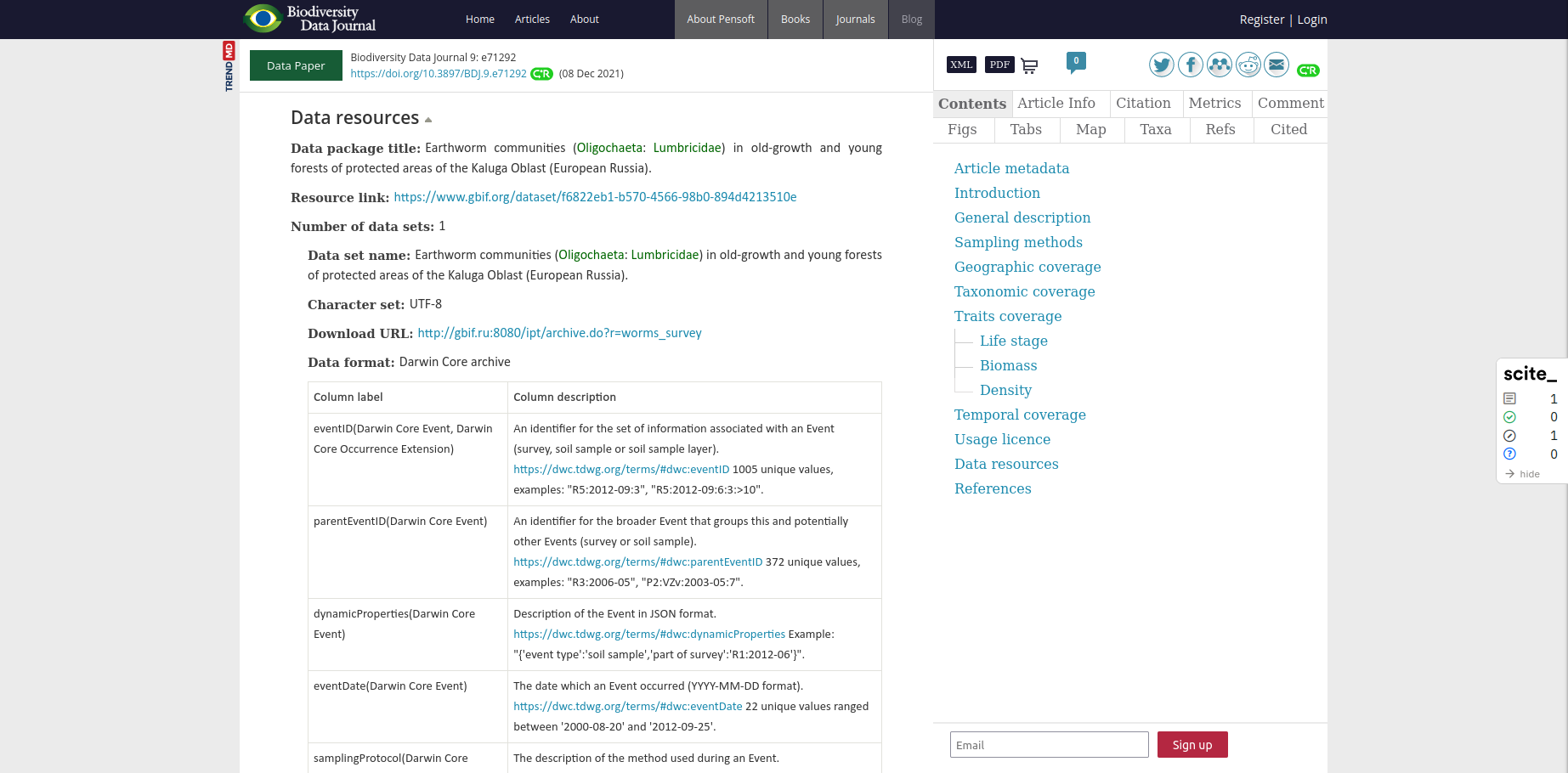 Source : Shashkov et al., 2021
Source : Shashkov et al., 2021Il est donc important d'avoir en tête qu'en amont de la rédaction d'un data paper, les chercheurs doivent déposer toutes les données et toute la documentation associée.
-
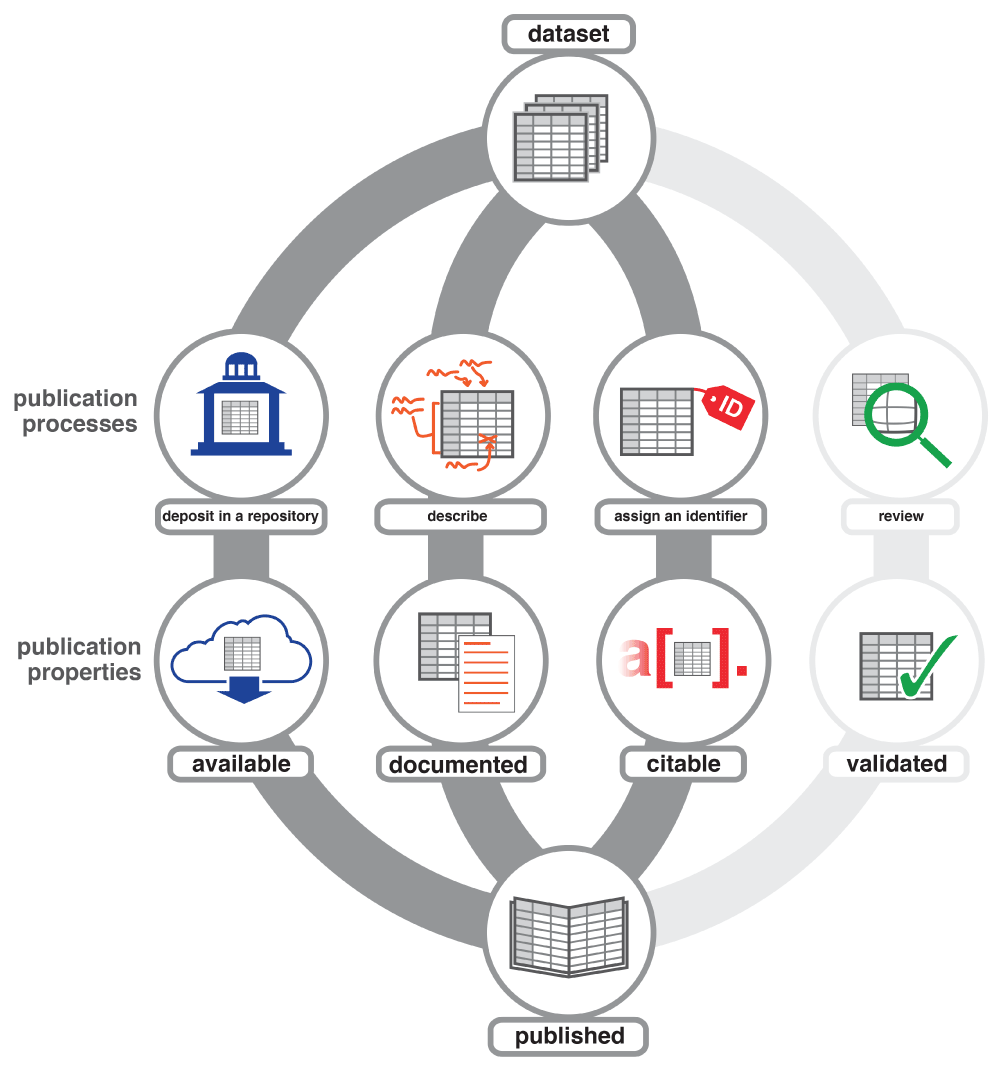
Données publiées
L’image présente ici la différence entre des données de recherche validées, préservées, citables et créditées. Toute la documentation qui accompagne les données peut varier en fonction du choix de l’outil de mise à disposition des données. Il faut donc distinguer des données “publiées” lorsque les données sont accessibles au public et réutilisables, mais ce terme peut ou non impliquer que les données ont été examinées par des pairs. L’ "examen des données par les pairs" comme nous avons pu le constater précédemment dans les attentes des revues peut être variable. Il en est de même pour un entrepôt de données.
La question devient d’autant plus complexe que les données peuvent être dynamiques ou appartenir à une base plus large. Leur enrichissement continu pose alors de nouvelles questions sur ce que sont les données de recherche.