
2.1 Understanding the data lifecycle
Section outline
-
-
What is the source of the data?
Observation data
Observation data are captured in real time. They are captured by observing a behaviour or activity and are therefore most often unique and impossible to reproduce. This is the case with sensor data, neuroimaging, astronomical photography or survey data.

Experimental data
Experimental data are obtained from laboratory equipment. They are often reproducible but this can be costly. Chromatographs and DNA chips fall into this category.

Computational or simulation data
Computational or simulation data are generated by computer or simulation models. They generate more important metadata. They are often reproducible provided that the model is properly documented. For simulations data, the test model wich is used is often as important than the data generated from the simulation and sometimes even more so. Examples include meteorological models, seismic simulation models and economic models.

Derived or compiled data
Derived or compiled data are derived from the processing or combination of raw data. They are often reproducible but expensive. This is the case for data obtained by text mining, 3D models or compiled databases.

Reference data
Collection or accumulation of small datasets that have been peer reviewed, annotated and made available.
-
What form does this data take?
 Textual data : Field or laboratory notes, survey responses...
Textual data : Field or laboratory notes, survey responses...  Digital data : Tables, measures...
Digital data : Tables, measures... Audiovisual data : Images, sounds, videos…
Audiovisual data : Images, sounds, videos… Computer codes
Computer codes Discipline-specific data : For example FITS in spatial data or CIF in crystallography...
Discipline-specific data : For example FITS in spatial data or CIF in crystallography... Specific data produced by some instruments
Specific data produced by some instruments -
4. Research Data Life Cycle
The data life cycle is the set of steps involved in the management, preservation and dissemination of the research data, associated with research activities. This cycle guides researchers through the research data management process to enable them and their stakeholders to make the most of the research data generated.Source : DoRANum
It can be divided into six different phases: Planning, Collecting, Analysing, Publishing, Preserving, and Reusing.
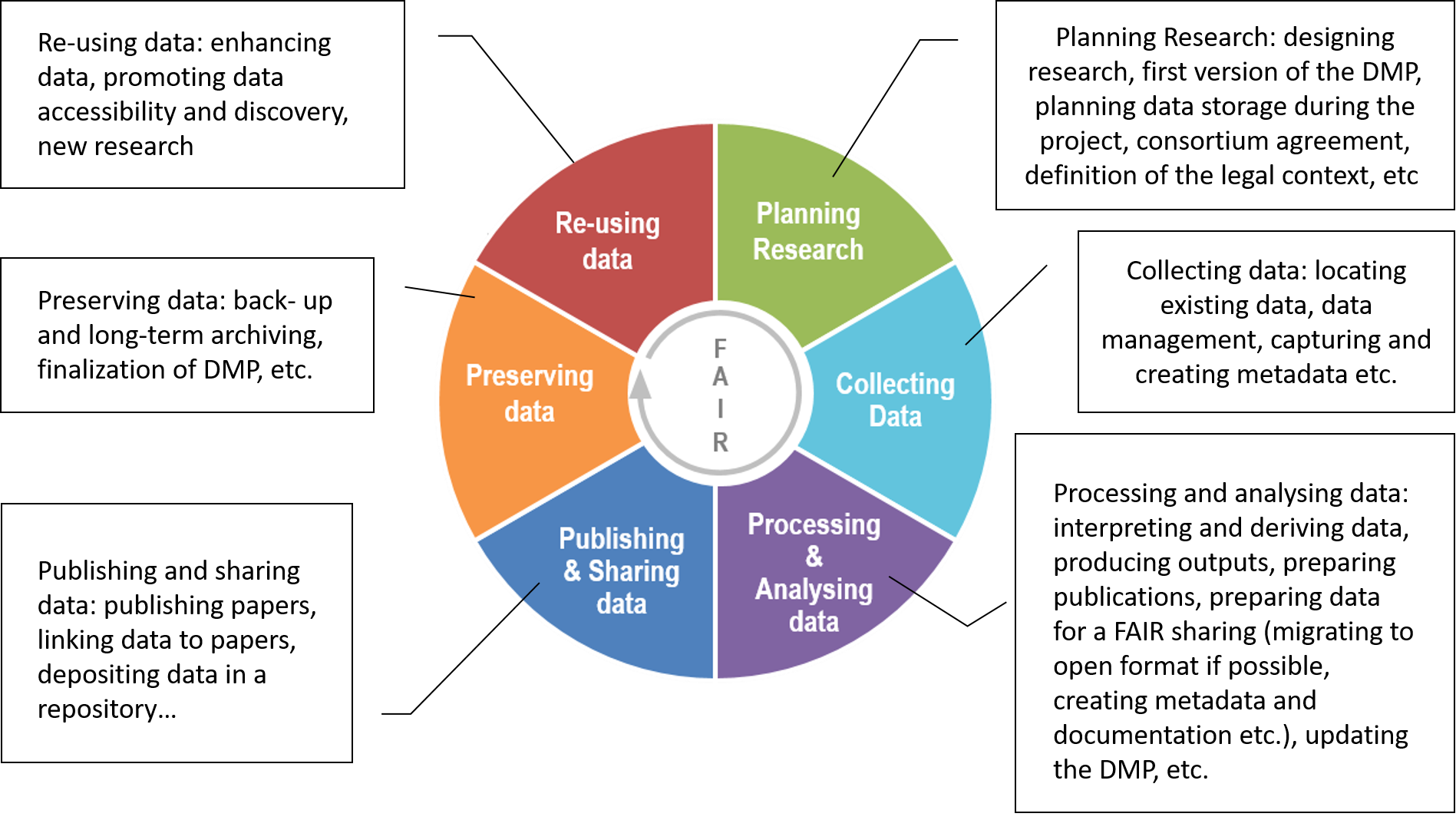
Source : Adaptation of Research data lifecycle – UK Data Service