
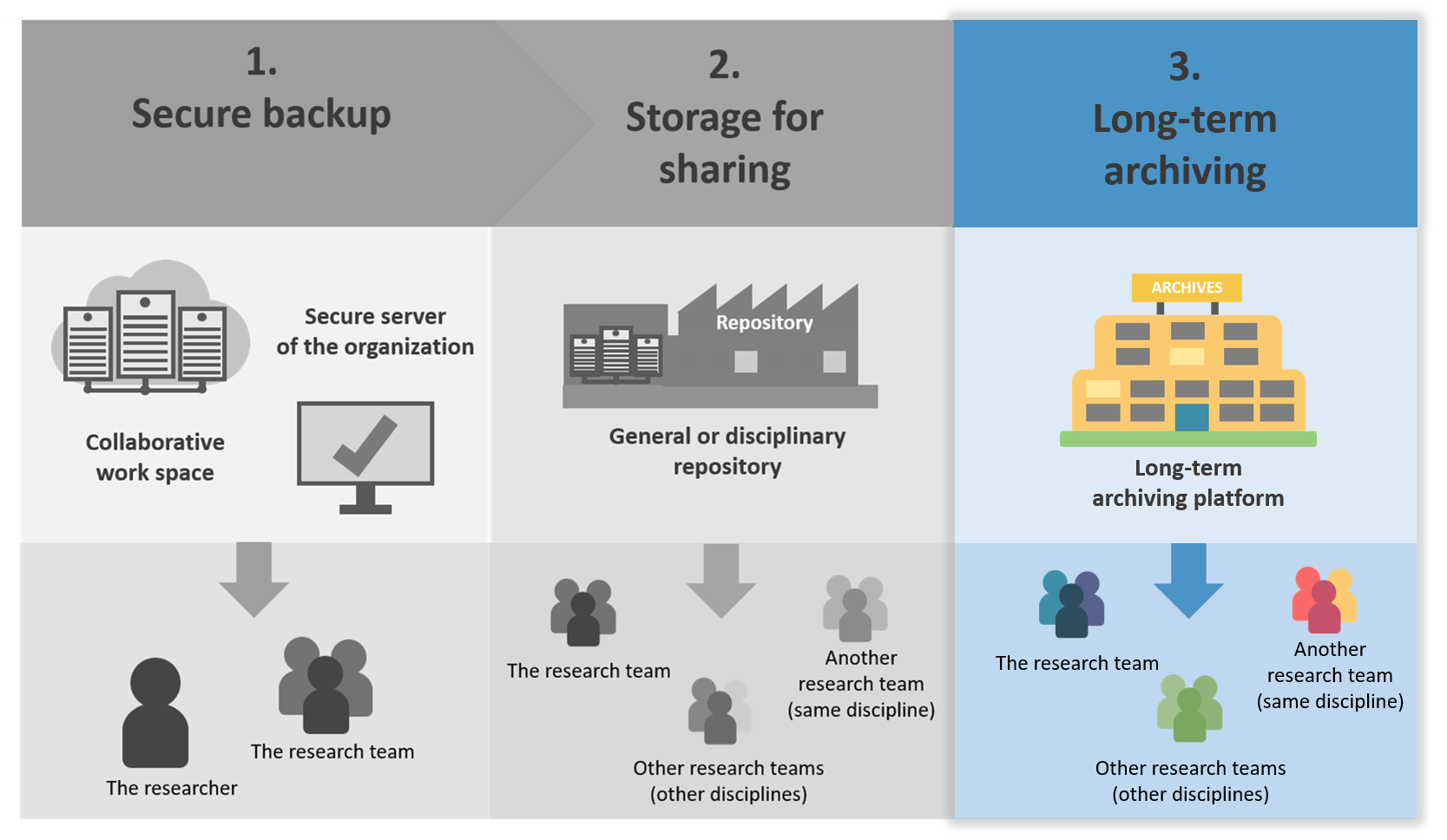
2.7 Three distinct steps (secure backup, depositing in a repository, long-term archiving)
Section outline
-
-
Storage and secure backup, sharing, long-term archiving occur at different steps of the data lifecycle, and have distinct functions.
Here is a scheme to understand the difference between these 3 steps: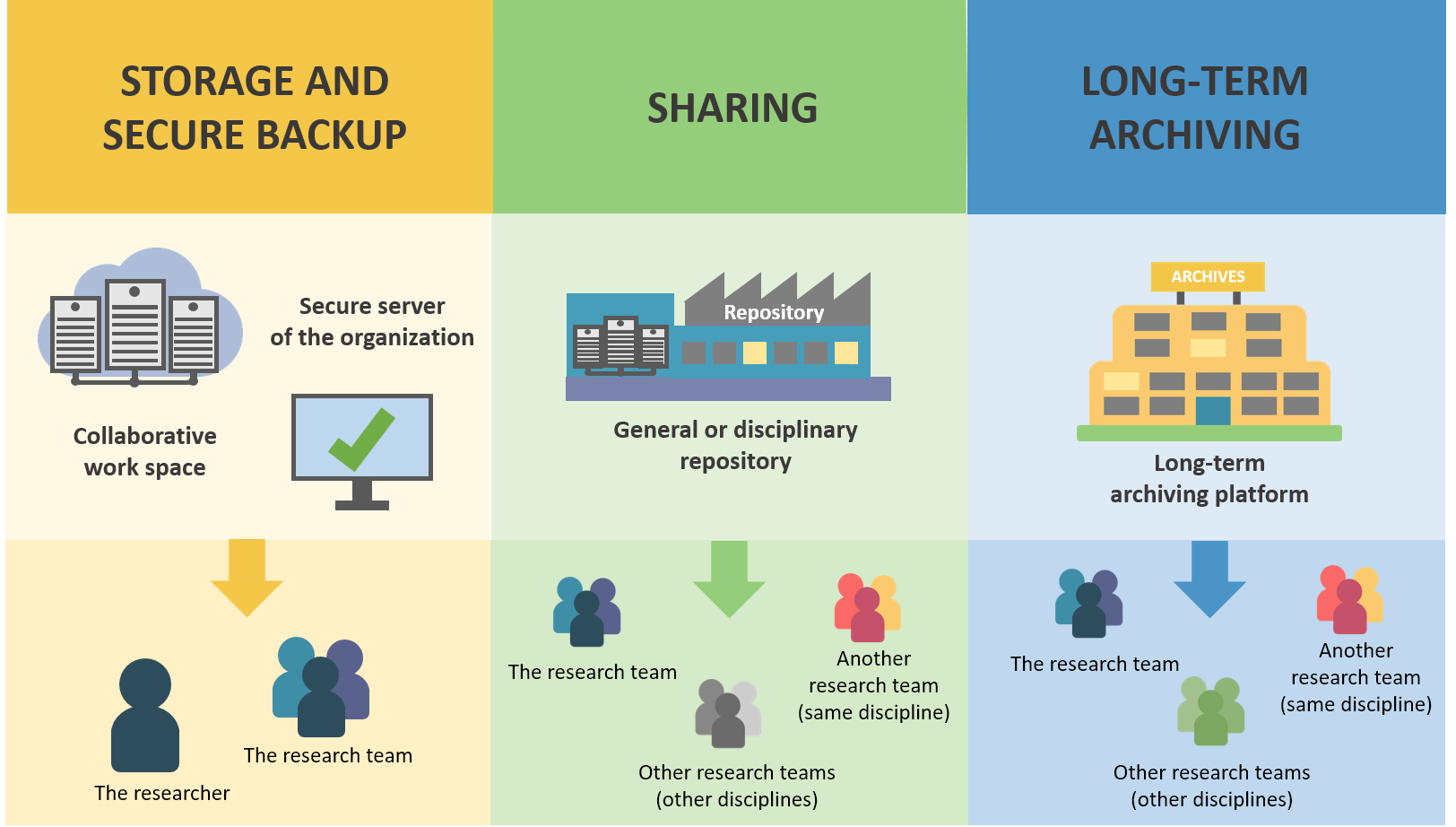
Source: DoRANum - Stockage, partage et archivage : quelles différences ?
-
1.Storage and secure data backup during the project
The first step is the storage and secure backup of the data during all the project:
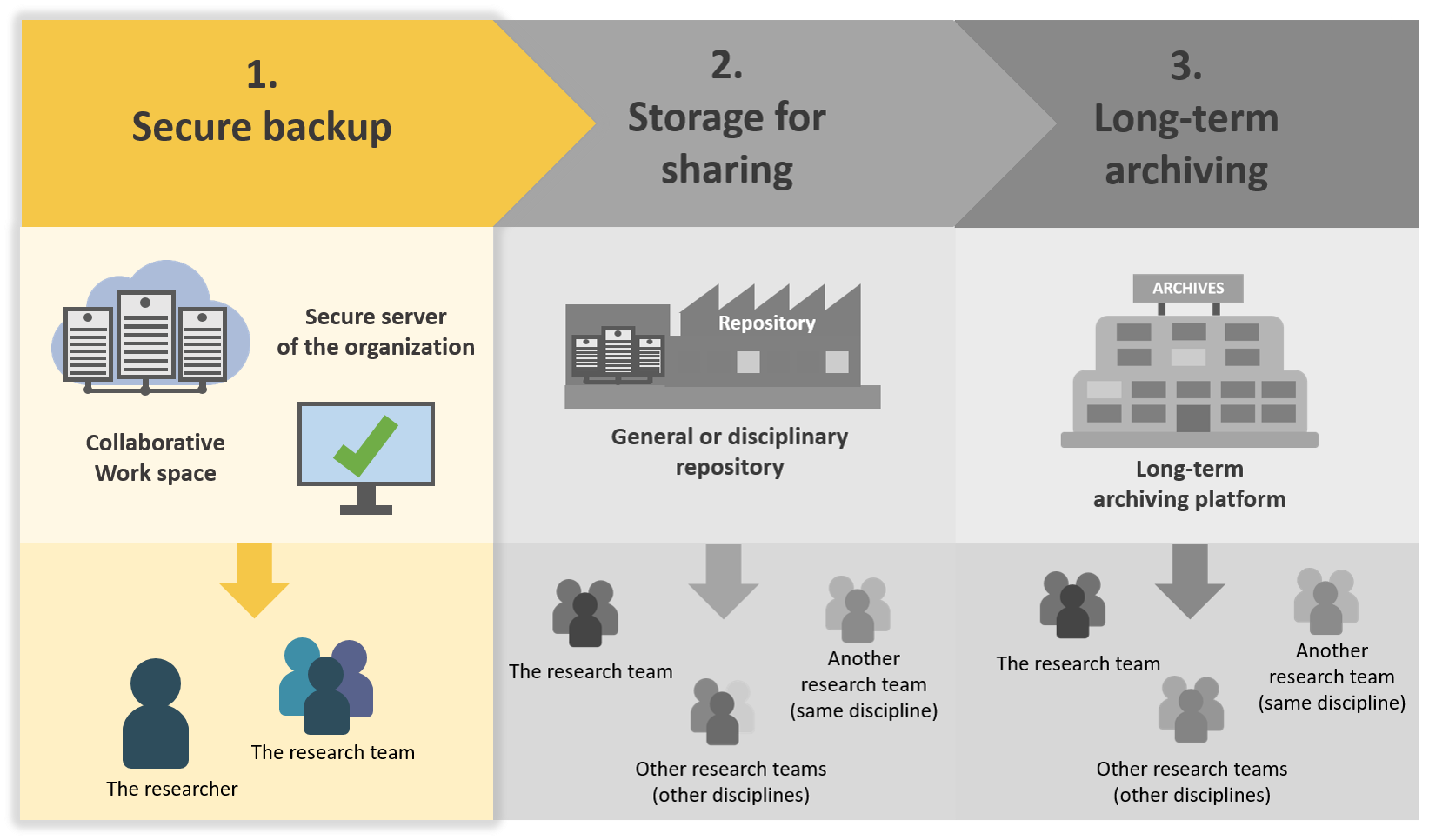
The objectives are to:
- ensure data security
- facilitate access for all project collaborators
Storage and secure data backup in the data lifecycle
This concerns the first part of the data life cycle.
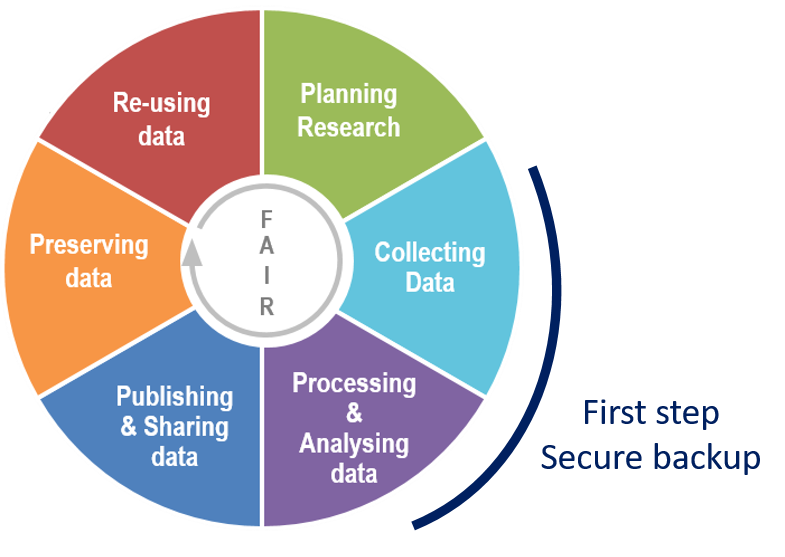
Adaptation of Research data lifecycle – UK Data Service
-
2. Depositing data in a repository for sharing
This step occurs often after the project (but you can share your data earlier): it is necessary to deposit the datasets in a repository.
A repository allow to storage, access and reuse of data.
The sharing of data in a repository provides a wide access to the scientific community, for a short and medium term (5 to 10 years).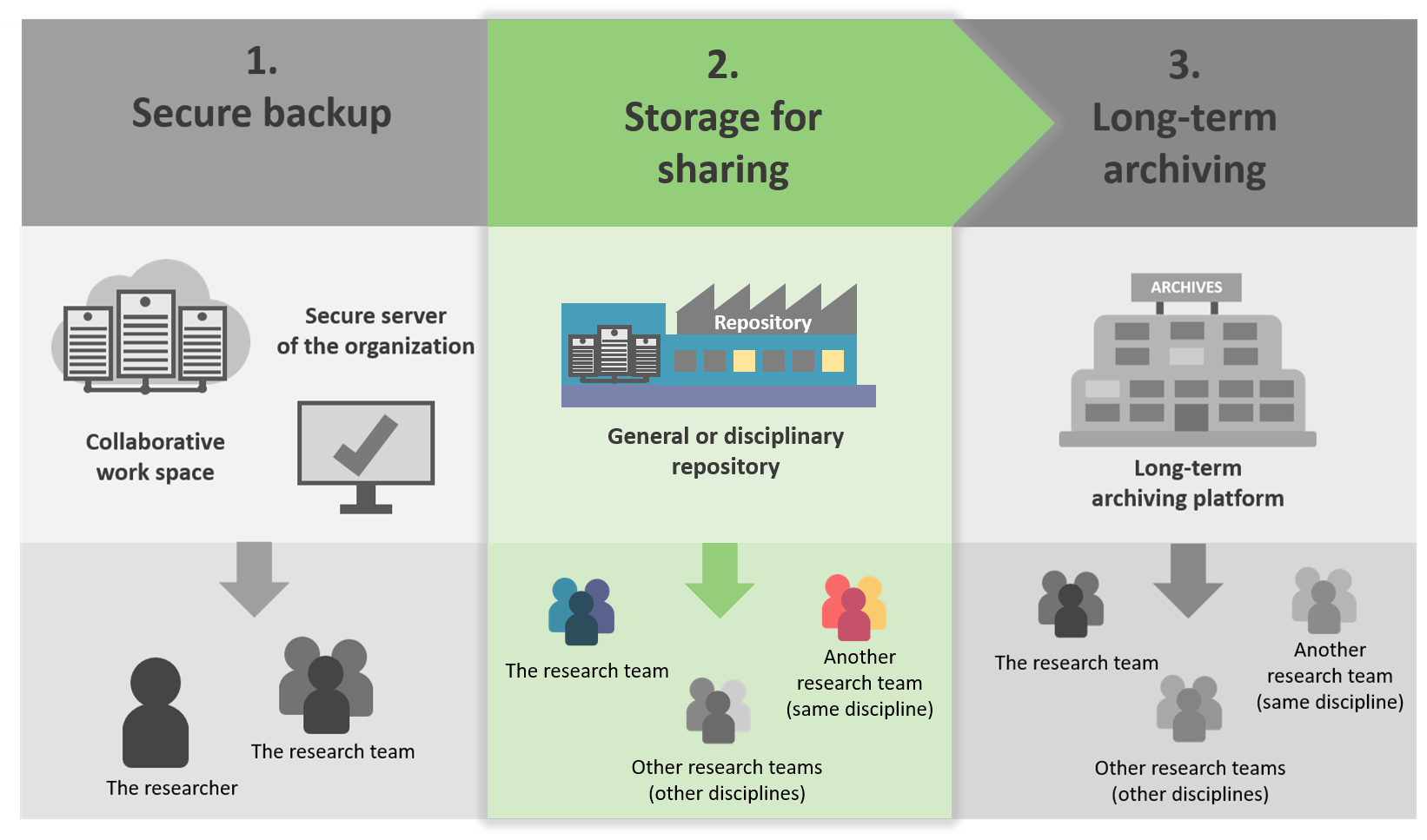
Sharing data in the data lifecycle
Data sharing is often complementary to scientific publication during and after the end of the research project.
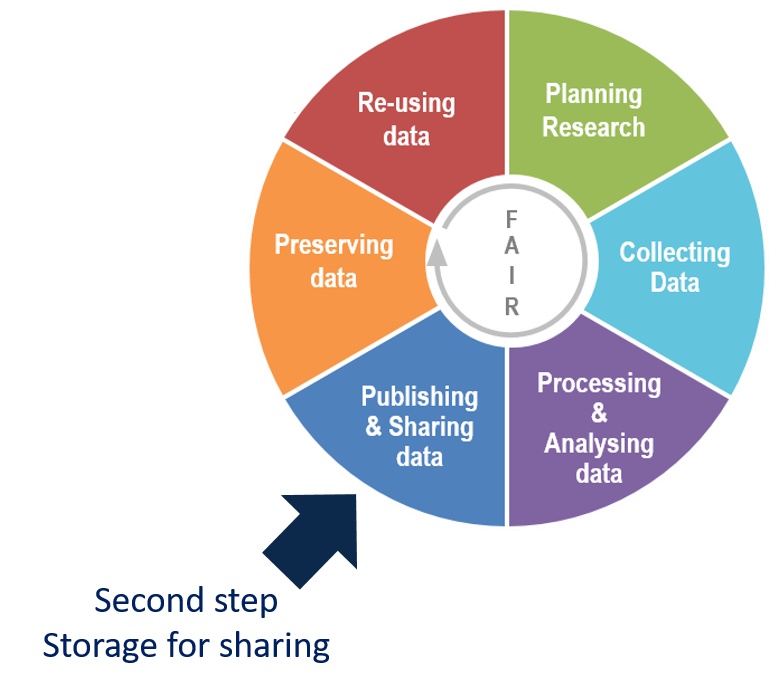
Adaptation of Research data lifecycle – UK Data Service
-
Example of a search in the re3data directory
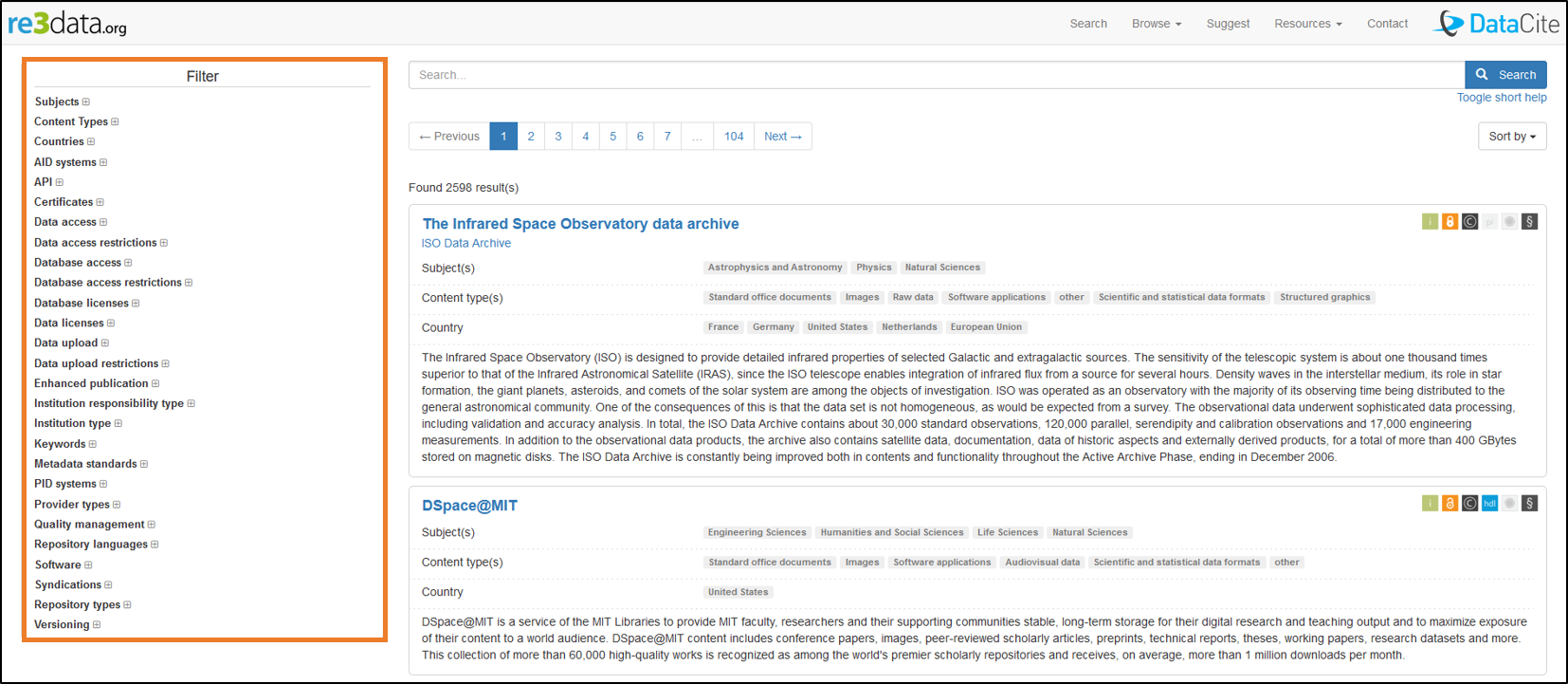
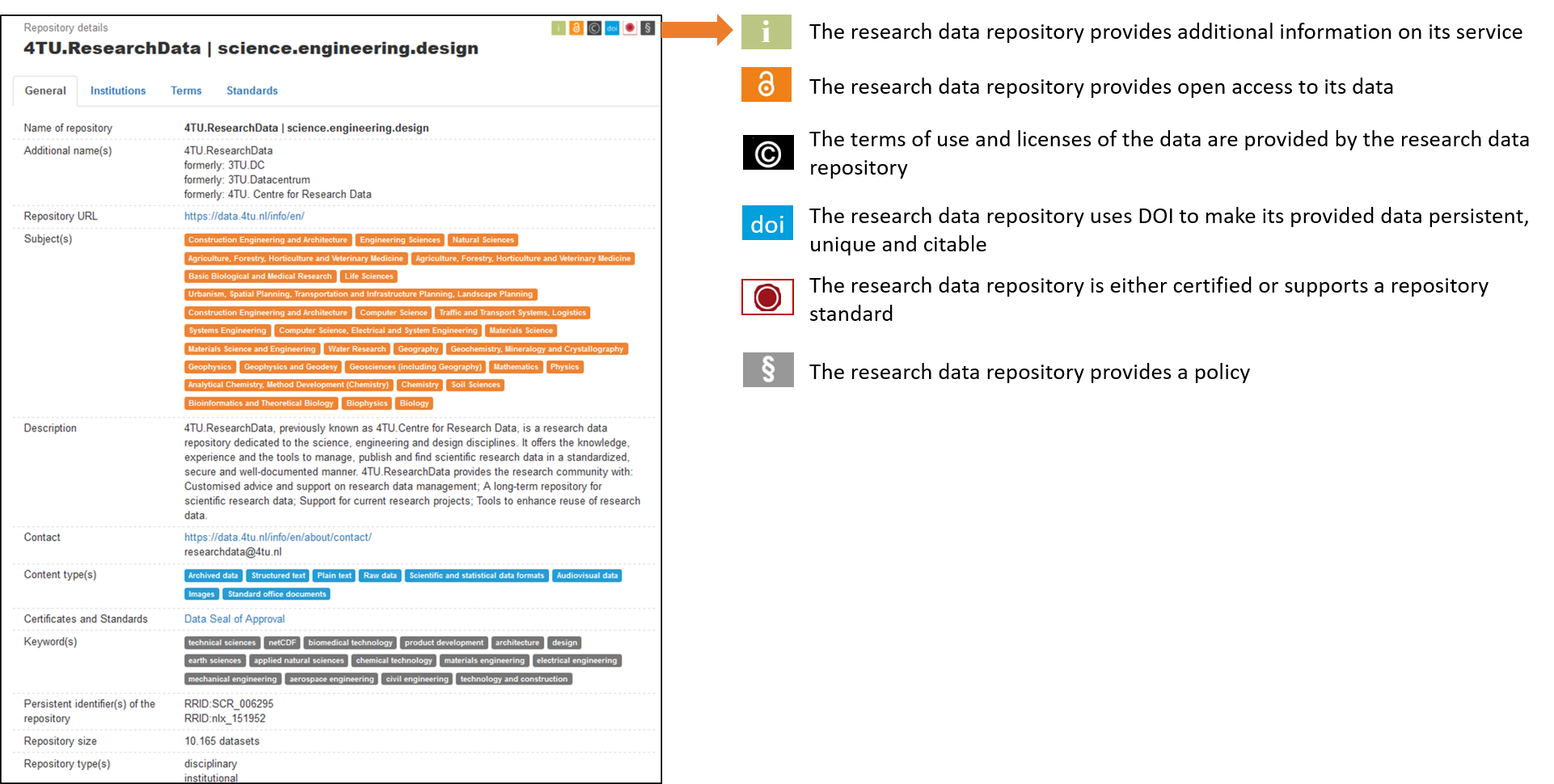
For each repository, a short descriptive sheets presents
- the subject,
- the type of content,
- the country,
- a small summary,
- icons of the criteria.
Example for the 4TU repository: https://www.re3data.org/repository/r3d100010216
Tip: The search engine Google Dataset Search is also a simple tool to search for data repositories.
-
3. Long-term archiving
Long-term archiving is the ultimate step in saving and storage research data.
Long-term archiving in the data lifecycle
Long-term archiving generally concerns only a part of the data produced by a project. For some projects, it is not necessary to archive data.
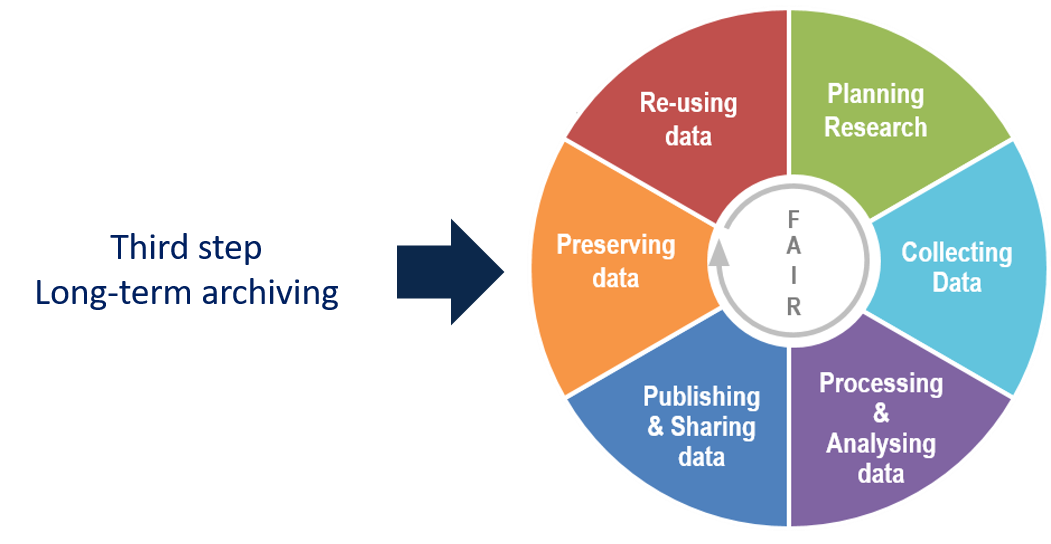
Adaptation of Research data lifecycle – UK Data Service
Definition
The question of long-term archiving only concerns data:
- with a scientific value for all the community
- requiring preservation for at least 30 years.
It is an expensive operation that needs an allocated budget. This is the responsibility of the laboratory and not the researcher.
Concretely, long-term digital archiving consists of preserving the document and its content:- in its physical and intellectual aspects,
- over the very long term,
- to be always accessible and understandable.
Long-term archiving services in Europe
At the European level, there are several infrastructures that specifically propose long-term archiving services.
The European Open Science Cloud (EOSC) Portal is an integrated platform that allows easy access to lots of services and resources for various research domains along with integrated data analytics tools. It includes services for long-term archiving, for example:EGI Archive storage: Archive Storage allows you to store large amounts of data in a secure environment freeing up your usual online storage resources. The data on Archive Storage can be replicated across several storage sites, thanks to the adoption of interoperable open standards. The service is optimised for infrequent access. Main characteristics: Stores data for long-term retention; Stores large amount of data; Frees up your online storage.
B2SAFE: this is a robust, safe and highly available EUDAT service which allows community and departmental repositories to implement data management policies on their research data across multiple administrative domains in a reliable manner. A solution to: provide an abstraction layer which virtualizes large-scale data resources, guard against data loss in long-term archiving and preservation, optimize access for users from different regions, bring data closer to powerful computers for compute-intensive analysis.
Selection of data to be archived
To select the data that will be archived for the long term, it is important to consider the value of the data:
- Are the data unique, non-reproducible (or at too high a cost)?
- Do the data have historical value, i.e., do they represent a landmark in scientific discoveries?
- Do the data include changes in processing methods, new standards, or create precedents?
- Do the data support ongoing projects or scientific trends?
- Are the data likely to meet future needs/directions of the scientific community (reuse potential)?
- Are the data likely to be cited or referenced in a publication?
- ...
- The quality and compliance of data collection must be controlled and documented. This may include processes such as calibration, sample or measurement repetition, standardized data capture, data entry validation, peer review...
- Quality, physical integrity of data (undamaged, readable...)
- What is the policy of the funder, the institution?
- Are the data compliant with the institution's strategy?
- Is there a legal or legislative reason to preserve the data?
- Is there an obvious reason why the data might be used in litigation, public inquiries, police investigations, or any report or document that could be challenged in court?
- Are there financial or contractual obligations that require data preservation?
When considering data preservation, the cost of conservation (identified not only as storage, but also management, sharing, access, backup, and long-term data maintenance) must be weighed against evidence of potential data reuse.
Consult the research archives management reference guide, Association of French Archivists, Aurore Section.
Source :- NERC Data Value Checklist. https://www.ukri.org/publications/nerc-data-value-checklist/(opens in a new tab)
- DoRANum : Données de la recherche : apprentissage numérique [En ligne]. France : DoRANum; 2017. Le Référentiel de gestion des archives de la recherche [publié le 13/05/2019]. Disponible(opens in a new tab) i(opens in a new tab)ci(opens in a new tab).
Preparation of the data to be archived
Here is a checklist to prepare your data for long-term archiving:
- Selection of datasets: The datasets (and associated metadata) selected may be different from the shared datasets.
- Volume: Evaluate the volume of data and the necessary budget.
- Data treatment: Treatment of some data may be necessary. For example, personal data requires anonymization.
- File formats: Check the validity of data file formats according to the recommendations of the archive selected.
- Software: Document and perhaps also provide the software used to access the data.
- Metadata: Complete and enrich the metadata if necessary, according to the recommendations of the archive selected.
-
