
Gestion et diffusion des données de la recherche
Résumé de section
-
Dans le cadre du mouvement de l’Open Science, la question de la gestion et du partage des données de la recherche devient centrale dans le montage de projets de recherche. De plus en plus d’organismes de financement public conditionnent le versement de leurs subventions à la diffusion de ces données. Afin d'y répondre, les porteurs de projets doivent réaliser des plans de gestion de données.
Cette formation vise ainsi à fournir des éléments méthodologiques, techniques et juridiques afin d’adopter de bonnes pratiques dans le cadre de la gestion de données de la recherche :
- Comprendre les enjeux liés à la gestion et à la diffusion des données de la recherche
- Comprendre les principes de la gestion des données de la recherche
- Acquérir les bases pour l’élaboration d’un plan de gestion de données
- Utiliser l’outil DMP OPIDor afin de rédiger un plan de gestion de données

Ce cours est en libre accès !
Aucune création de compte ou d'inscription n'est nécessaire, toutefois vous ne pourrez le parcourir qu'en lecture seule.
Pour participer à certaines activités (test, forum...), vous pouvez vous inscrire au cours.
-
-
Le cycle de vie des données de la recherche
La représentation du cycle de vie des données de la recherche est une aide à la gestion des données. En effet, ce cycle de vie décrit le processus d'utilisation des données de leur création à leur publication et ré-utilisation ultérieure.
C'est le cycle qui doit être décliné dans les plans de gestion de données au début de tout projet de recherche impliquant la création et/ou la réutilisation de données :
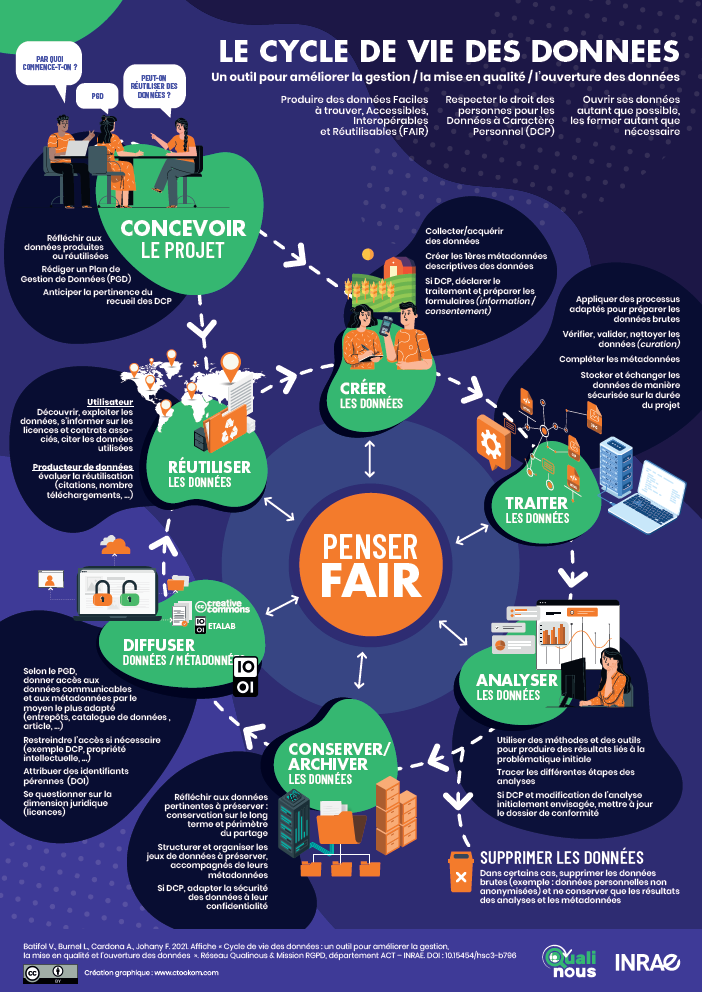
Batifol V., Burnel L., Cardona A., Johany F. 2021. Affiche « Cycle de vie des données : un outil pour améliorer la gestion, la mise en qualité et l’ouverture des données ». Réseau Qualinous & Mission RGPD, département ACT – INRAE. DOI : 10.15454/hsc3-b796
-
Les Plans de Gestion de Données
Callisto. (2024, 19 septembre). La Minute Plan gestion de données , in Les minutes DoRANum. [Vidéo]. Canal-U. https://doi.org/10.60527/rk86-ws89
À retenir :
Le Data Management Plan ou Plan de gestion de données est un document synthétique qui aide à organiser et anticiper toutes les étapes du cycle de vie de la donnée. Il explique pour chaque jeu de données comment sont gérées les données d’un projet, depuis leur création ou collecte jusqu’à leur partage et leur archivage :
- suivant un calendrier : le PGD est un document évolutif. Des mises à jour et des livrables précis peuvent être définis selon le financeur et/ou les projets ;
- au moyen d’outils : des outils existent pour aider dans la production de PGD comme DMPOPIDoR.
Un PGD peut être établi aussi bien dans une optique de partage des données que pour des données en accès restreint ou fermé, total ou partiel. Le PGD mentionnera dans ce cas les raisons de non partage.
Les Plans de gestion de données dans les appels à projet financé
Les appels à projet Horizon Europe

Les bénéficiaires doivent gérer les données de recherche générées de manière responsable, conformément avec les principes FAIR :
- Établir un plan de gestion des données ("DMP") et le mettre à jour régulièrement.
- Déposer les données dans un entrepôt de confiance suivant le principe "aussi ouvert que possible aussi fermé que nécessaire".
Les métadonnées des données déposées doivent être ouvertes sous un Creative Common Public Domain (CC 0) ou équivalent, conformément aux principes FAIR et fournir des informations minimum.
Les appels à projet ANR :
- Plan d’action ANR 2022 : « Le coordinateur ou la coordinatrice du projet s’engage à fournir dans les 6 mois qui suivent le démarrage du projet, une première version du Plan de Gestion des Données (PGD) selon les modalités communiquées dans les conditions particulières ».
- Appel à projets générique - AAPG 2022 : Dans le cadre de la contribution de l’ANR à la promotion et à la mise en œuvre de la science ouverte, et en lien avec le Plan National pour la Science Ouverte au niveau français (PNSO) et le Plan S au niveau international, les bénéficiaires de l’ANR s’engagent à garantir le libre accès immédiat aux publications scientifiques évaluées par les pairs et à adopter, pour les données de la recherche, une démarche dite FAIR (Facile à trouver, Accessible, Interopérable, Réutilisable) conforme au principe « aussi ouvert que possible, aussi fermé que nécessaire ».
Connaissances et compétences nécessaires à l’élaboration d’un PGD
La rédaction d'un plan de gestion des données induit de :
- Connaître la réglementation concernant la production et la diffusion des données.
- Connaître les principaux formats de métadonnées selon sa discipline pour la description des données.
- Connaître les entrepôts pour la diffusion en libre accès des données.
- Savoir déterminer les besoins en matière de gestion et de stockage des données.
- Savoir prévoir les coûts et besoins pour la conservation et la diffusion des données.
Ainsi, cette rédaction nécessitent un travail collaboratif impliquant l'ensemble des acteurs intervenant dans le processus de gestion des données générées dans un projet de recherche. Selon les établissements de rattachement l'organisation peut différer mais les principaux acteurs sont :
-
2. La description des jeux de données
Nous trouverons dans cette rubrique l'ensemble des informations sur les types de données collectées ou générées dans le cadre du projet :
- description de chaque jeu de données ;
- l'origine des données (création/réutilisation) ;
- le format de chaque jeu de données.
Focus sur le format des données
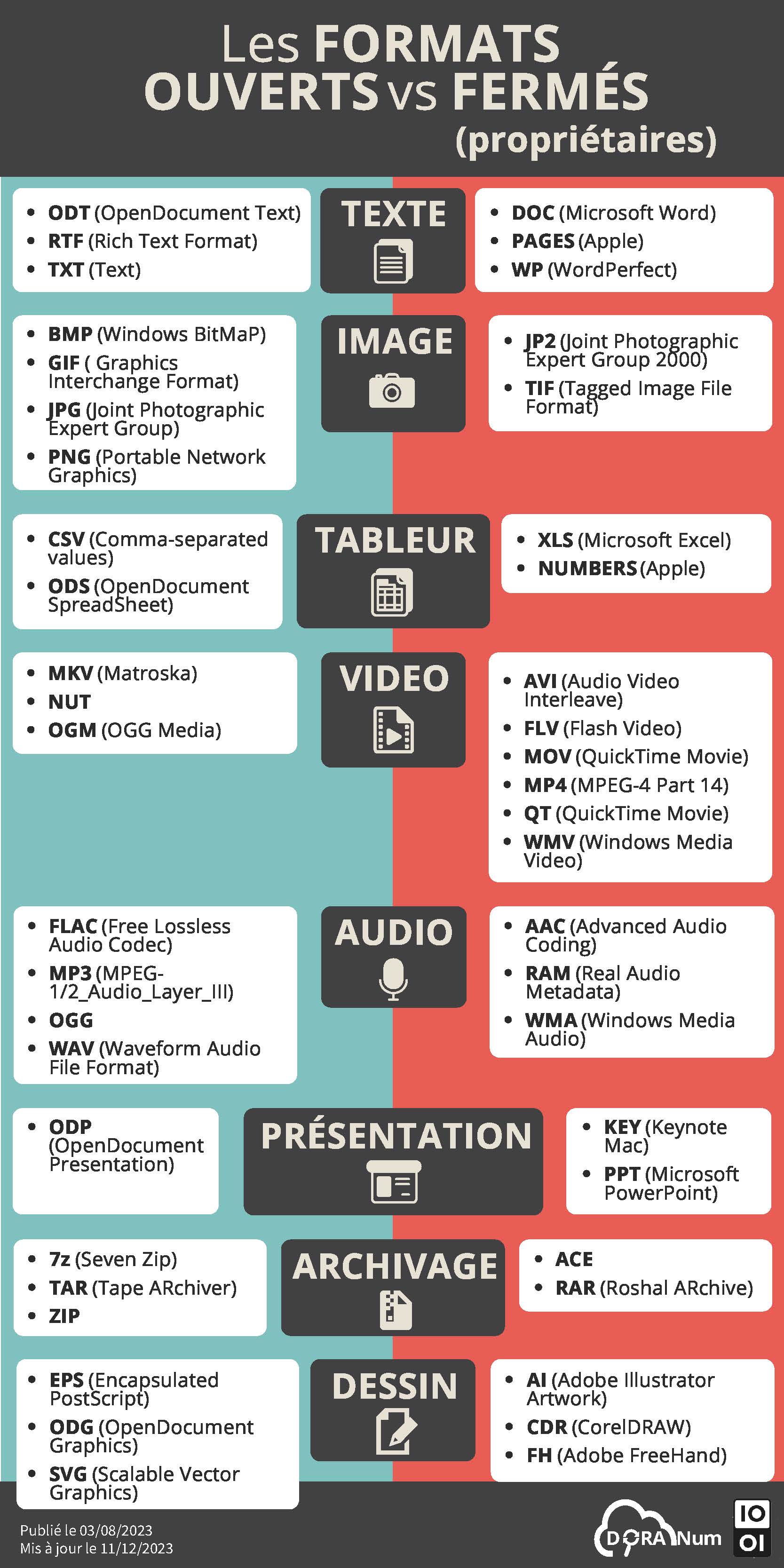
Savez-vous quels formats sont ouverts (accessibles et modifiables indépendamment d’un logiciel unique) et lesquels sont fermés (contraints par le recours à un logiciel, le plus souvent payant) ?
-
-
-