Langues minorisées à corpus restreint : partager pour survivre
Aperçu des sections
-
-
Bienvenue dans ce parcours destiné aux doctorantes, doctorants, chercheuses, chercheurs en sciences humaines et sociales qui produisent et/ou travaillent sur des corpus de langues minorisées ! Découvrez et comprenez comment les corpus peuvent être utilisés pour faire avancer la recherche, servir à la société et contribuer à la survie numérique de langues à corpus restreint.
Ce parcours a été pensé et conçu pour être suivi de façon linéaire et progressive. Un sommaire s'affiche à la gauche de votre écran et vous permet de naviguer à votre convenance.
Bonne visite !
Si vous rencontrez des difficultés à ouvrir certains liens du cours, essayez de les ouvrir dans un autre navigateur.
Objectifs
- Identifier les enjeux du partage des corpus pour les langues minorisées
- Comprendre la chaîne de développement des applications du TAL
- Distinguer différents types de corpus pouvant alimenter un développement en TAL
- Identifier quelques caractéristiques d’un bon corpus pour le TAL
- Intégrer les principes FAIR dans vos pratiques de partage des corpus
- Interroger le cadre juridique qui s’applique à votre corpus
Ce cours est en libre accès !
Aucune création de compte ou d'inscription n'est nécessaire, toutefois vous pouvez vous inscrire à ce cours si vous le souhaitez.
S'inscrire au cours
-
-
-
Licence : CC-BY 4.0
Le breton est utilisé ici comme exemple mais il peut être remplacé par toute autre langue minorisée à corpus restreint.
-

Le corpus est « une collection de données langagières qui sont sélectionnées et organisées selon des critères linguistiques explicites pour servir d’échantillon de langage ».
Delais-Roussarie E. Corpus et données en phonologie post-lexicale : forme et statut. Langages [En ligne]. 2008 [consulté le 27 juin 2023] ; 171(3) : 60. Disponible : https://doi.org/10.3917/lang.171.0060 -
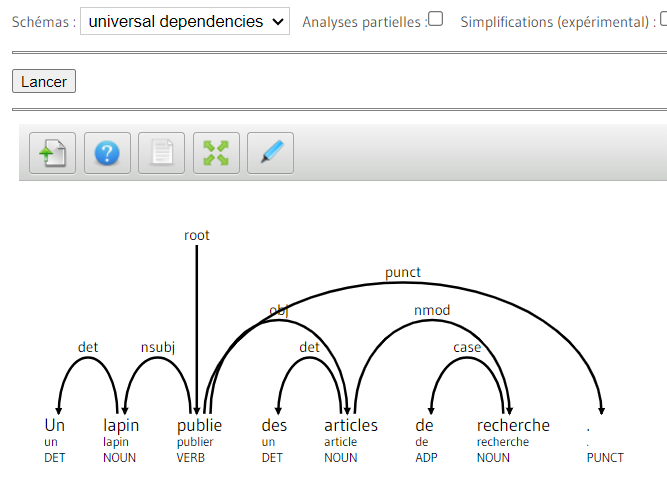
Capture d'écran d'une annotation linguistique réalisée par l'outil FrMG de l'INRIA au schéma universal dependencies
Capture d'écran d'une annotation au format CoNLL -CLARIN. LINDAT/CLARIAH-CZ [En ligne]. UDPipe ; [consulté le 26 sep 2023]. Disponible : https://lindat.mff.cuni.cz/services/udpipe/?data=https://switchboard.clarin.eu/api/storage/cb833e5f-943e-4957-8db5-5cab24b41970?mediatype=text%2Fplain&model=fra
-
Il est difficile de déterminer précisément la bonne taille pour un corpus. Est-ce 1000 mots ? 500 000 ? 1 000 000 ? En réalité, cela dépend fortement de la complexité de l'outil que l'on veut entraîner avec ledit corpus. En revanche, pour obtenir des résultats similaires, un corpus annoté nécessitera moins de mots qu'un corpus brut.
En effet, un corpus annoté demande un travail et un temps de conception non négligeable mais la richesse des annotations diminue la quantité de données nécessaire pour l'entraînement de l'outil. À l'inverse, un corpus brut doit être massif pour que l'algorithme puisse en déduire statistiquement des règles.C'est d'ailleurs ce qui se passe lorsque l'on apprend naturellement une langue par immersion. On entend des expressions incorrectes, des fautes de langage mais notre cerveau parvient à trier et à distinguer la forme la plus utilisée, qui est généralement la forme correcte.
C'est aussi en partie pour cette raison qu'il n'est pas nécessaire d'essayer de produire des corpus bruts dans une langue dite "parfaite". En effet, même si des corpus contiennent des "fautes" (formes typiques des apprenants, typos, données intraitables, fautes nombreuses, mais différentes d’un corpus à l’autre…), si la forme correcte est suffisamment représentée, alors l'algorithme saura trier le "bruit".
Ce qui est vrai pour un apprenant humain, l'est d'autant plus pour un algorithme qui n’est pas limité par sa mémoire. C'est pourquoi il est inutile de corriger l'intégralité des dissonances.
Licence : CC-BY 4.0
-