Langues minorisées à corpus restreint : partager pour survivre
Résumé de section
-
-
Les quatre principes FAIR sont un ensemble de principes directeurs établis pour gérer les données de la recherche. Ils visent à faciliter la découverte et l'accès aux données, ainsi qu'à favoriser leur interopérabilité et leur réutilisation.
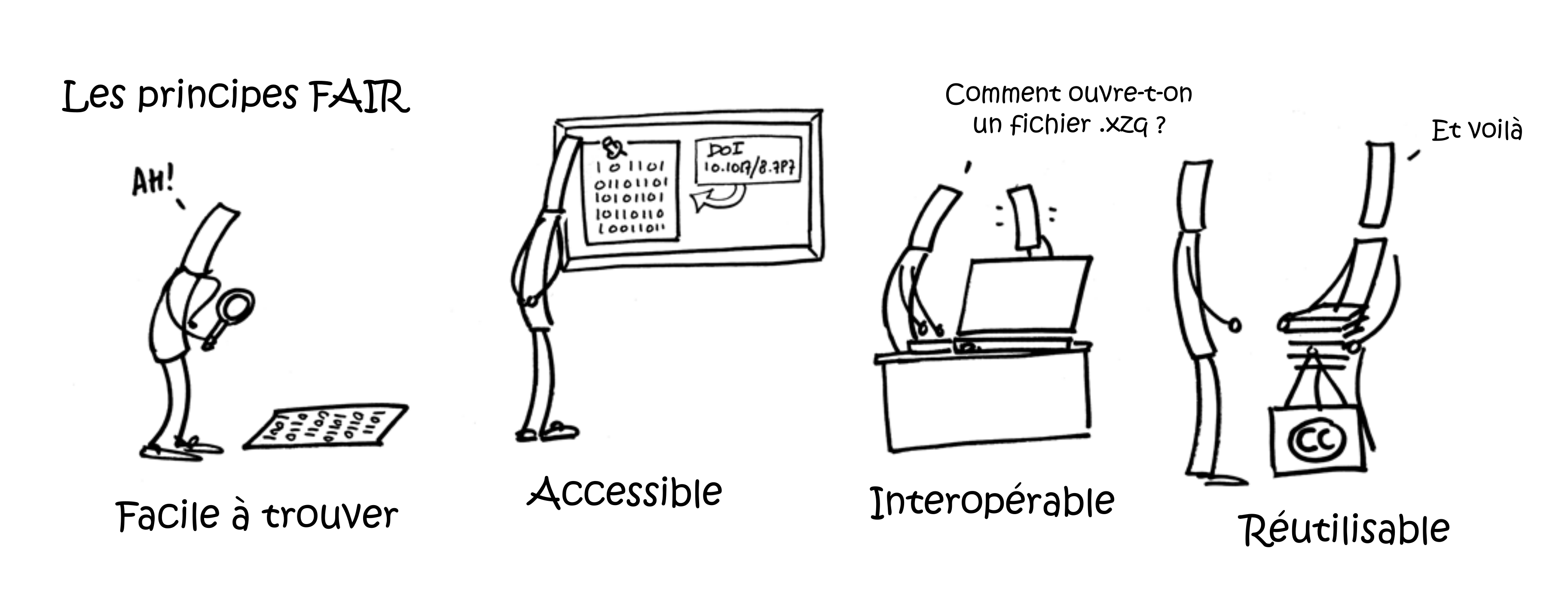
Licence : CC-BY 4.0
Illustrations : Patrick Hochstenbach / Modifié par : DoRANum -

Un livre sans métadonnées 
Un livre avec métadonnées -
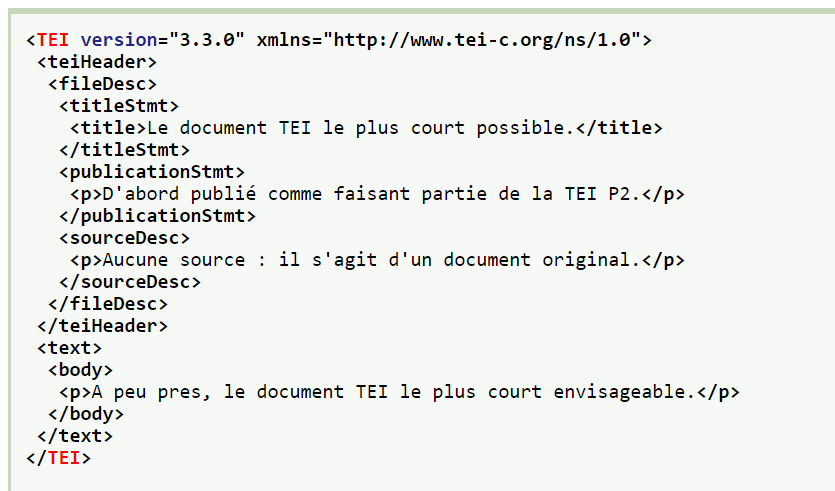
La TEI (Text Encoding Initiative) est un ensemble de recommandations et un format pour l'encodage numérique des documents textuels. Cet encodage, basé sur le XML (Extensible Markup Language, un métalangage informatique de balisage), permet, sans modifier le texte original, de le rendre lisible par les machines grâce à l'ajout de balises.L'en-tête TEI (TEI header) contient un ensemble de métadonnées utilisées pour décrire des ressources textuelles.
Ce format de balisage est largement utilisé et reconnu à l'international en linguistique et, plus largement, en Sciences Humaines et Sociales (SHS).Pour en savoir plus sur la TEI (intérêts, exemples, applications...), vous pouvez visionner cette vidéo réalisée par Lo Congrès permanent de la lenga occitana qui a formaté ses données en TEI.
Ci-dessous, un exemple de balisage au format TEI contenant l'en-tête TEI:
Le standard de métadonnées OLAC (Open Language Archives Community) est une extension d'un standard de métadonnées générique utilisé en SHS, le Dublin-Core. OLAC propose des extensions pour certains champs de métadonnées du Dublin-Core qualifié, permettant ainsi une description plus précise des ressources linguistiques. Ces extensions sont liées à des vocabulaires contrôlés en linguistique.Il s'agit d'un standard de métadonnées relativement simple à appréhender. Il est proposé par les entrepôts de données français CoCoOn et ORTOLANG pour la description de ressources linguistiques.
Pour vous faire une idée, vous trouverez ici l'exemple d'un corpus (Corpus Oral de Français de Suisse Romande) décrit avec le standard OLAC dans l'entrepôt CoCoOn.
Ci-dessous, une capture d'écran de la notice de métadonnées de ce corpus déposé dans l'entrepôt CoCoOn :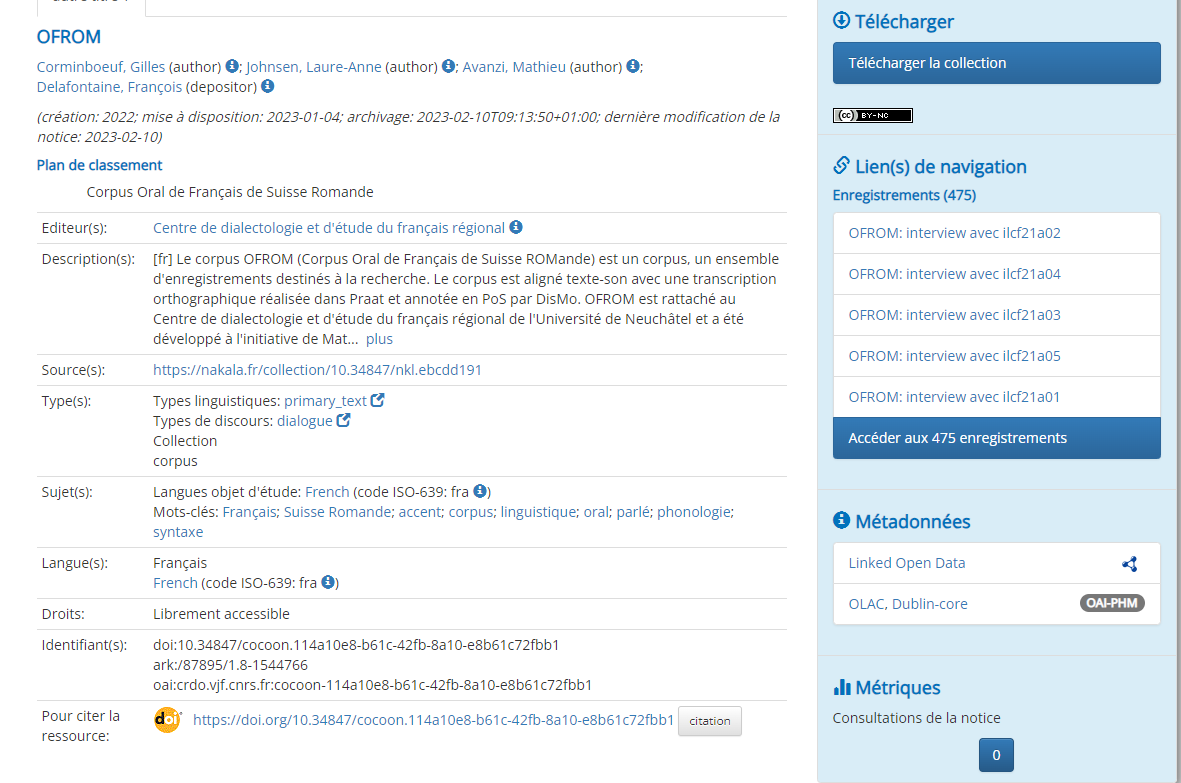
Il s'agit d'une approche développée par l'infrastructure européenne dédiée au partage de ressources et d’outils autour du langage, CLARIN (Common Language Resources and Technology Infrastructure).Le CMDI (Component MetaData Infrastructure) permet la création et l'utilisation d'un schéma de métadonnées flexible et modulable. Il permet de sélectionner, parmi des standards existants, les métadonnées jugées pertinentes pour la description d'une ressource, voire d'en créer de nouvelles, et de les assembler dans un modèle appelé "profil". Chaque utilisateur obtient ainsi un profil au plus près des besoins spécifiques de description de ses ressources tout en préservant une relative interopérabilité. Pour préserver cette dernière, les utilisateurs sont encouragés à partager les profils ainsi créés dans le Registre des Composants.
-
Licence : CC-BY 4.0
-
Il existe plusieurs entrepôts de données en linguistique qui sont adaptés au dépôt de corpus oraux et/ou écrits. En France, il y a par exemple :

Pangloss
Offre, en libre accès, des documents linguistiques sonores, avec une spécialité de langues rares ou peu étudiées. Pangloss a également mis en place des outils pour faciliter les recherches en linguistique et en TAL


ORTOLANG
Un entrepôt de données pour les ressources et outils sur la langue écrite et orale.
Par ailleurs, CLARIN propose, à l'échelle européenne, une liste d'entrepôts certifiés pour la linguistique. Les entrepôts ORTOLANG et CoCoOn cités précédemment en font partie.
Il existe aussi :

Nakala
Un entrepôt de données multidisciplinaire en Sciences Humaines et Sociales (SHS) porté par la IR* (très grande infrastructure de recherche) Huma-Num
-
Pour des raisons de sécurité, de confidentialité, de respect de la vie privée ou autres, il peut être nécessaire de limiter l'accès aux données à un groupe restreint de personnes. Dans ce cas, pour rester FAIR, l'accès aux corpus doit pouvoir se faire via authentification et/ou demande d'autorisation. Le protocole d'accès doit être clair et explicite (qui contacter, comment, etc.).
Licence : CC-BY 4.0
-

Licence : CC-BY 4.0
-