
4. Sélectionner un entrepôt
Résumé de section
-
Objectifs :
- appréhender le concept de curation des données,
- identifier les critères de sélection d'un entrepôt de données.
25 minutes de lecture
-
Curation des données
Une fois les données publiées, se pose alors la question de leur conservation. C'est là qu'entre en scène un nouvel acteur : l’archiviste mais aussi des scientifiques..

La curation consiste à vérifier la conformité du jeu de données aux règles établies par le Centre de ressources entrepôt-catalogue et par l’administrateur de la collection. Elle vise à assurer une bonne compréhension des données publiées et à favoriser leur réutilisation, en accord avec les principes FAIR.
La conservation est la gestion et la promotion de l’utilisation des données dès leur création, afin de s’assurer qu’elles sont adaptées à un usage contemporain et disponibles pour être découvertes et réutilisées… Des niveaux de conservation plus élevés impliqueront également le maintien de liens avec l’annotation et avec d’autres documents publiés.
Les activités de conservation comprennent :
- L’archivage : une activité de conservation qui garantit que les données sont correctement sélectionnées, stockées, accessibles et que leur intégrité logique et physique est maintenue dans le temps, y compris la sécurité et l’authenticité.
- La préservation : une activité d’archivage dans laquelle des éléments spécifiques de données sont conservés dans le temps de sorte qu’ils puissent toujours être accessibles et compris grâce aux changements technologiques.
-
Critères de sélection
Avant de choisir l'entrepôt pour vos données, pensez à vérifier l'ensemble de ces points :
Quel est le nom de l’entrepôt et son adresse ? Vous pouvez identifier ici le type de propriétaire de l'entrepôt (institution, entreprise commerciale, etc.).
Comme pour une revue scientifique classique, un entrepôt peut avoir des attentes, soit en termes de disciplines, de documentation, de métadonnées, etc. Par exemple, voici la documentation pour l'entrepôt Nakala, développé par Huma-Num. D'autres comme Pangea (pengaea.de) mettent à disposition un wiki pour le dépôt des données.
Existe-t-il une personne contact pour l'entrepôt, si besoin d'assistance ? Si vous n'êtes pas familier avec ce genre de procédure, il peut être intéressant de privilégier un entrepôt proposant ce type d'accompagnement, comme sur Recherche Data Gouv par exemple.
Il existe différents types d'entrepôts de données :- Généraliste : Zenodo
- Disciplinaire : Nakala, le Centre de Données astronomiques de Strasbourg, etc.
- Institutionnel : Recherche data gouv
- Autre : git
 Existe il une certification de l'entrepôt comme "Core Trust seal"?
Existe il une certification de l'entrepôt comme "Core Trust seal"? La question est quelles sont les données acceptées, comme des formats spécifiques ou encore des données toujours en cours de traitement.
- un embargo possible, si vous ne souhaitez pas rendre disponibles immédiatement vos données ?
- un accès uniquement aux métadonnées ?
- un accès restreint, uniquement sur demande ?
- Quelles sont les attentes en termes de documentation ?
- Les métadonnées sont elles libres ou existe il un standard de métadonnées à utiliser, un vocabulaire spécifique ?
- DOI
- Handle
Quel est le coût de l'entrepôt pour le stockage de vos données ?
- La taille du jeu de données fait elle varier le coût ?
- Quelle est la durée du stockage des données ? La question ici est de définir la pérennité des données.
-
Dataverse Project
Dataverse Project est un logiciel de référentiel de données de recherche open source qui s'adresse aux chercheurs, aux revues, aux établissements ainsi qu'aux développeurs.
Dans le dataverse il est possible de déposer et associer à la fois les données, de la documentation, les codes et les data files, pour former un ensemble complet. Comme dans la plupart des entrepôts de données, le format utilisé est le Dublin core ou du Dublin Core enrichi (métadonnées associées directement).
Pour en savoir plus sur cet outil, vous pouvez consulter le guide Dataverse Project (s'ouvre dans un nouvel onglet)
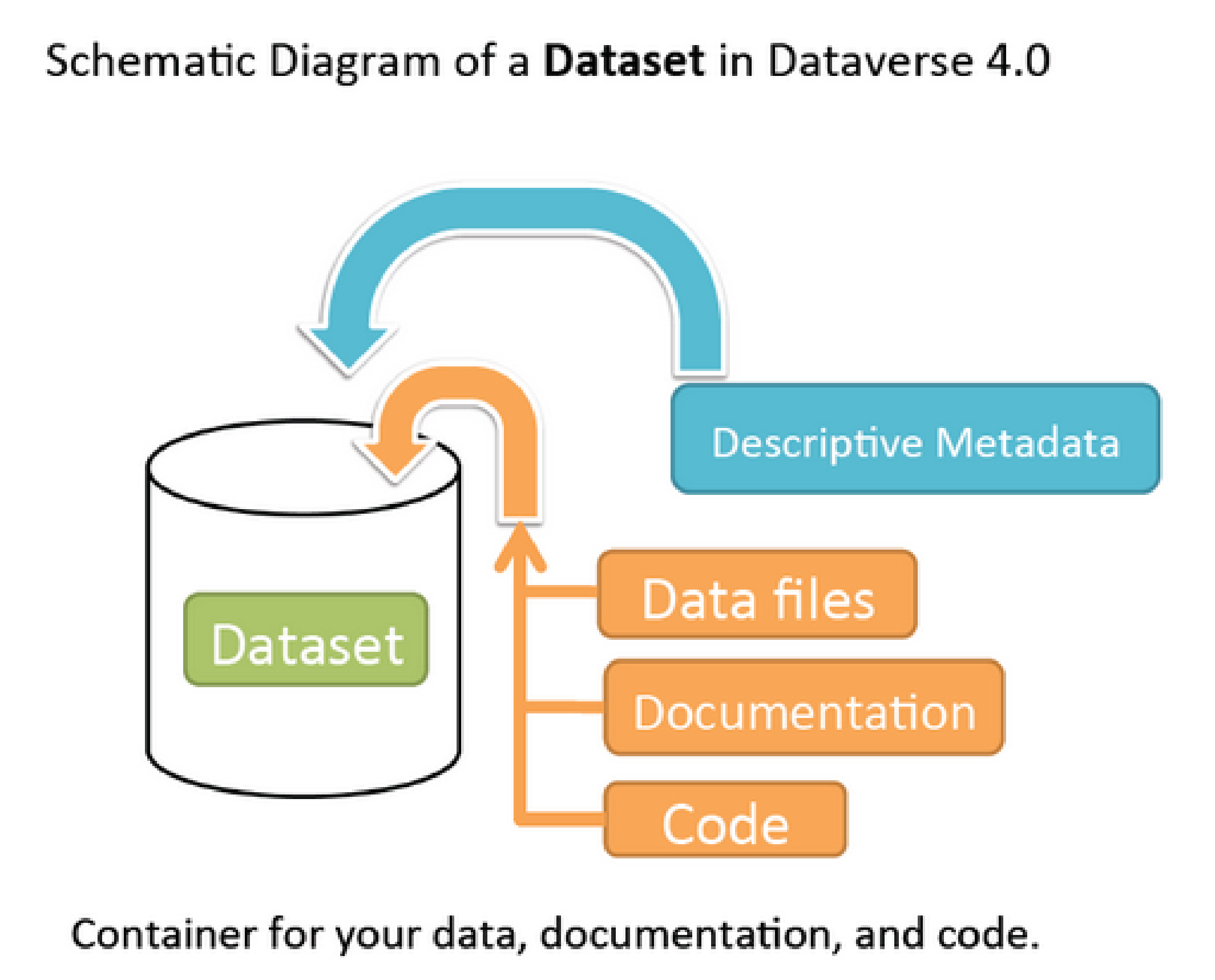
-
Fichier Readme
Un fichier "Lisez-moi" (Readme) donne des informations sur la façon d’interpréter un fichier de données et diminue les chances que les données soient mal comprises et/ou improprement utilisées par d’autres chercheurs. Il contient autant d’informations que possible sur les fichiers de données pour permettre aux autres de comprendre les données.Source : Données de recherche - Polytechnique MontréalNommez-le toujours README.txt ou README.md (Markdown) afin de respecter la nomenclature en vigueur et pensez à créer un fichier README.txt pour chacun de vos jeux de données.
Télécharger le gabarit recommandé de fichier Lisez-moi.
