
3. Données de consultation
3.1. Consultation des pages
L'audience d'un site internet, a fortiori celle de Wikipedia, n'est pas une réalité simple et unidimensionnelle cernable avec un seul indicateur. De plus, la mesure, la conservation et la diffusion de ces données demandent des ressources humaines, financières et techniques dont le mouvement Wikimedia n'a pas toujours disposées. Ce chapitre présente les données publiques disponibles, la définition de ce qui est mesuré, l'évolution au cours du temps des données recueillis et pointe quelques limites afin de correctement analyser ces jeux de données. La Wikimedia Foundation met à disposition de tous la fréquentation des wikis qu'elle héberge. Il est possible de remonter jusqu'à mai 2015, voire jusqu'en 2007 via les archives, mais au prix de nombreuses ruptures statistiques rendant délicate l'analyse sur longue période.
Données ouvertes
Il existe plusieurs façons d'accéder aux données. Pour connaître la fréquentation de quelques pages, une interface visuelle est proposée : la suite d'outils pageviews. Pour un nombre plus important de pages ou un besoin d'automatisation, une API ouverte est disponible. Enfin les données sont librement téléchargeables et publiées sous la mention Creative Commons CC0. Les dumps de données prennent la forme d'un fichier compressé par heure.
Par ailleurs, de nombreux outils, plus ou moins éphémères, voient régulièrement le jour à partir de ce jeu de données. C'est également un domaine important en matière de création de visualisation de données.
Enfin il y a une littérature abondante analysant la fréquentation de Wikipedia ou les chercheurs se servent du nombre de vues dans leur démonstration (Ball, 2023). Une récente revue de la littérature a étudié l'utilisation du nombre de vues dans Wikipedia dans le domaine de la santé (Alibudbud 2023). Un autre papier analyse l'impact de Wikipedia sur la science en utilisant entre autre la consultation des articles (Thompson et Hanley 2018). La consultation de l'encyclopédie peut aussi être utilisé pour mesurer l'intérêt du public pour un sujet donné, par exemple les aires protégées (Guedes-Santos et al. 2021), les reptiles (Roll et al. 2016) ou les sites touristiques (Owuor et al. 2023), la grippe (Brownstein et Mclever, 2014, McIver et Brownstein, 2014, De Toni et al., 2021), les épidémies mondiales (Provenzano et al., 2019), la grippe porcine (Ritterman et al., 2009), le coronavirus (O'Leary et Storey, 2020), si le Ice Bucket Challenge a sensibilisé les gens à la sclérose latérale amyotrophique (Bragazzi et al., 2017), le succès d'un film au cinéma (Mestyán et al., 2013), les résultats électoraux (Yasseri et Bright, 2016, Salem et Stephany, 2021), l'essor de l'extrême droite en Allemagne (Debus et Florczak 2022), le cour de la bourse (Moat et al., 2013, Zimmerman, 2020, Gómez-Martínez et al. 2022), l'incidence des restrictions en matière de droits d'auteur sur la réutilisation des connaissances (Nagaraj, 2017).
Dans la suite du cours, nous présenterons les liens vers les principales ressources utiles à l'aide d'icônes :
| Documentation | Données | API |
Dataviz |
|---|
Historique de la mesure de l'audience
La mesure de la fréquentation des wikis de Wikimedia Foundation n'a pas été un long fleuve tranquille. Voici une présentation des principales étapes montrant l'évolution dans la mesure de l'audience. Ce travail repose sur la chronologie de la mesure d'audience Wikimedia complétée par la documentation technique.
Définition de l'indicateur
La définition d'une page vue est la suivante depuis 2015. La documentation technique permet de savoir ce qui est précisément mesuré.
Une requête du journal des requêtes web est comptabilisée comme une page vue si elle remplit les conditions suivantes :
- l'entête HTTP X-Analytics ne contient pas
preview=1; - le code de réponse HTTP est
200 OKou304 Not Modified; - le type MIME est une version de
text/htmlouapplication/jsonpour les requêtes de l'application mobile ; - l'une ou l'autre des conditions suivantes :
- l'entête HTTP X-Analytics contient
pageview=1, ou - l'URL répond aux critères suivants :
- il comporte un site en production (Wikipedia, Wikisource, Meta, Commons, etc.) ;
- it comporte un répertoire de contenu (principalement
/wiki/, mais aussi/zh-hant/ou une autre variante linguistique) ; - il ne s'agit pas d'une page spéciale.
- l'entête HTTP X-Analytics contient
Bien que les modifications d’un article ne soient pas comptabilisées dans ce jeu de données, les pics de consultation d'articles très peu consultés peuvent tout de même être liés à un moment de forte activité de la part d'un ou plusieurs rédacteurs car dans la phase de rédaction, il peut être nécessaire de consulter l'article à plusieurs reprises.
L'API n'est pas prise en compte sauf dans un cas bien particulier. De plus, selon la méthode utilisée pour faire du web scraping des projets Wikimedia, cela va être ou non comptabilisé dans le nombre de vues d’une page. L'article Wikipedia intitulé Liste de sondage élections présidentielles de 2022 est un bon exemple d’article dont le contenu a été régulièrement scrappé en 2022, jusqu’à en faire un des articles les plus consultés durant cette année électorale.
Trafic humain vs Trafic automatisé
L'analyse de la consultation de l’encyclopédie n'est pas simple. Outre les internautes qui consultent le site pour lire le contenu, il y a ceux qui scrapent le contenu, les robots qui indexent le web et tout un tas d'autres cas : des personnes qui gonflent exprès le nombre de vues, des outils mal configurés et d'autres cas où la page n'est pas consultée pour son contenu. Il n'est pas rare de voir des courbes de fréquentation d'articles anormales sans qu'il soit possible d'en determiner la raison. C'est un sujet encore très peu etudié, que ce soit en interne (en 2023 aucun salarié de Wikimedia Foundation n'est dédié à ce sujet) ou de la part des journalistes et des chercheurs.
Dans les jeux de données mis à disposition, Wikimedia Foundation met a part le trafic provenant des moteurs de recherche et depuis 2020, la Fondation distingue le trafic automatisé, du trafic généré par les robots d’indexation et du trafic généré par les lecteurs stricto sensu. Le jeu de données comporte trois types d’agent utilisateur (user agent) :
- Utilisateur : les êtres humains qui consultent Wikipedia sur un ordinateur ou un téléphone ;
- Robot d'indexation : les robots des moteurs de recherche qui indexent le web (Bing, BNF, Google, Qwant...) ;
- Trafic automatisé : il peut s'agir par exemple de robots qui tentent de mettre en tête des articles les plus consultés des articles traitant de la sexualité, la pornographie ou la politique. La détection automatique du trafic automatisé est récente (sans reclassification du trafic passé) et très imparfaite. Beaucoup de trafic automatique se retrouve encore catégorisé comme du trafic humain. Et vice-versa, il doit y avoir du trafic humain catégorisé comme du trafic automatisé.
Étude de cas : Cléopâtre
L'analyse du trafic de Wikipedia est de plus en plus compliquée. Outre le cas standard d'un internaute intéressé par un article de l'encyclopédie, il y a de nombreux outils automatisés qui consultent Wikipedia afin d'en extraire des données (cela va des robots d'indexation au web scraping). Dans les deux cas, le site est consulté parce que son contenu intéresse l'internaute. Mais il y a sans doute un troisième cas assez fréquent où l'internaute consulte Wikipedia sans que son contenu l'intéresse.
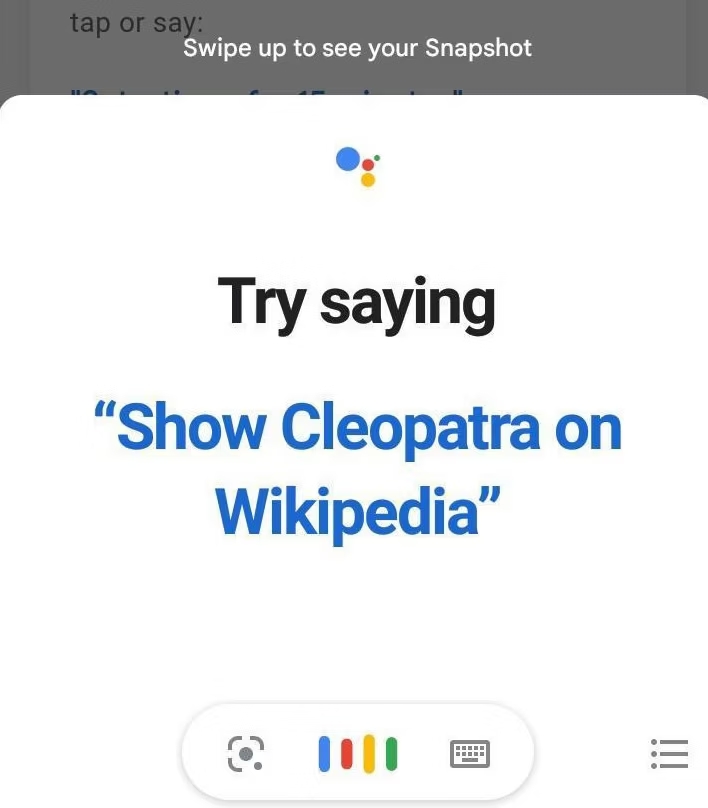
La biographie Wikipedia en anglais et en espagnol sur Cléopâtre figure régulièrement dans les articles les plus consultés. Cléopâtre est un personnage célèbre, mais cela ne suffit pas à justifier un tel trafic limité à deux langues. Une analyse détaillée de l'audience permet de s'apercevoir que le trafic provient de consultations faites par téléphone portable.
Bien souvent, nous n'avons pas d'explication à ces courbes d'audience anormales. Mais ce cas fait exception. Google invite ses utilisateurs à tester l'outil de commande vocale en chargeant l'article Cléopâtre.
Comme les autres moteurs de recherche, Google présente très souvent Wikipedia dans les premiers résultats. Et ponctuellement, Google génère des pics de consultation via les bannières Google Doodles affichées pour célébrer un événement ou une personnalité. Cette fois-ci il ne s'agit pas de trafic aberrant, mais cela montre l'importance de Google dans l'étude du trafic d'un site web, a fortiori dans le cas de Wikipedia. C'est aussi le signe qu'une décision a priori anodine peut avoir des effets très importants (Yasseri, 2023).
Étude de cas : Aster des jardins
Il n'y a pas que les articles qui peuvent avoir un trafic anormalement élevé. Pendant plusieurs mois entre 2020 et 2021, un fichier représentant une fleur a totalisé plus de 60 millions de requêtes par jour. Le trafic provenait d'Inde et représentait 20 % du trafic générés par les médias dans le datacenter EQSIN situé à Singapour. Dès qu'elle a découvert le problème, l'équipe de Wikimedia Foundation a rapidement détecté l'origine : il s'agissait d'une application mobile de réseautage social populaire en Inde qui était mal configurée.

{kind=link}
Conseils pour détecter les cas aberrants
- Analysez le trafic sur une période longue.
- Regardez la répartition du trafic selon les méthodes d'accès. Moins de 10% pour l'ordinateur ou le mobile est suspect.
- Jetez un œil au trafic dans d'autres langues. Si un sujet mondialement connu voit sa courbe d'audience fortement grimpée que dans une seule langue, cela peut être suspect.
- Vérifiez si le sujet est évoqué sur les réseaux sociaux. Cela permet notamment de détecter les pics de consultation liés aux jeux télévisés.
- L'actualité doit également être prise en compte.
- Utiliser l'API PageViews pour obtenir la liste des articles les plus consultés par pays afin de mieux comprendre ce qui se passe. Cela permet par exemple de voir que le trafic démesuré sur l'article en français traitant des cookies informatiques provient des États-Unis et du Royaume-Uni.