
IA et recherche documentaire : ChatGPT et les autres
Résumé de section
-
Cette formation explore l'impact de l'Intelligence Artificielle (IA) sur la recherche documentaire. Elle examine comment les outils d'IA générative transforment nos pratiques de recherche d'information, depuis les évolutions des moteurs de recherche traditionnels jusqu'à l'émergence de nouveaux assistants conversationnels.
Objectifs généraux
- Comprendre le fonctionnement des robots conversationnels et leurs différences avec les moteurs de recherche traditionnels
- Identifier les limites et les biais des IA génératives dans un contexte de recherche documentaire
- Distinguer les différentes approches de recherche (simple, approfondie)
- Analyser de manière critique les réponses fournies par les outils d'IA et vérifier leur fiabilité

Ce cours est en libre accès !
Aucune création de compte ou d'inscription n'est nécessaire, toutefois vous ne pourrez le parcourir qu'en lecture seule.
Pour participer à certaines activités (test, forum...), vous pouvez vous inscrire au cours.
-
La notion d'Intelligence Artificielle (IA) n'est pas récente, mais elle s'est démocratisée en fin d'année 2022 avec le lancement de ChatGPT au grand public. Depuis, les IA génératives ont pris une place considérable dans la vie de millions de personnes, que ce soit dans le cadre de la sphère privée ou professionnelle.
2 minutes de lecture
-
Les IA actuellement connues du grand public sont celles qui peuvent générer des contenus (texte, image, musique, vidéo...), que l'on appelle IA génératives. Certaines sont capables de converser avec nous, on les appelle aussi IA conversationnelles. Elles peuvent ainsi écrire un poème, créer du code informatique, expliquer un concept complexe, tenir une vraie conversation.
15 minutes de lecture
-
Quelques exemples d'IA connues

ChatGPT
IA générative conversationnelle (crée du texte, du code, analyse des documents...) créé par OpenAI

Le Chat
IA générative conversationnelle (crée du texte, du code, analyse des documents...) créé par la société française Mistral

Gemini
IA générative conversationnelle (crée du texte, du code, analyse des documents...) créé par Google

Midjourney
IA générative d'images (crée des illustrations et visuels)

Suno
IA générative musicale (compose des chansons avec paroles et mélodie)

Runway
IA générative de vidéos (crée des vidéos à partir de descriptions textuelles ou d'images)
-
-
Les IA génératives sont désormais de plus en plus utilisées pour la recherche d'information. Quelles sont les convergences et divergences avec les moteurs de recherche classiques ?
30 minutes de lecture
-
L'aspect probabiliste
D'un point de vue technique, les IA conversationnelles analysent les mots de votre question pour prédire statistiquement quels mots ont le plus de chances de former une réponse cohérente. Pour cela, elles s'appuient sur les patterns (motifs récurrents) qu'elles ont appris dans d'énormes volumes de textes lors de leur entraînement.
Exemple
Si l'IA générative génère ce début de texte "Le chat mange ses...", les probabilités du mot suivant pourraient être :
- "croquettes" (85%)
- "souris" (12%)
- "légumes" (3%)
Dans la même logique, si vous lui demandez "Quel temps fait-il aujourd'hui ?", il pourrait vous répondre :
- "Il fait beau" (50%)
- "Il pleut" (50%)
Cet exemple météo illustre bien que l'IA peut donner des réponses factuellement incorrectes (prétendre connaître la météo actuelle alors qu'elle n'a pas accès aux données en temps réel) tout en ayant une forte probabilité. Cette approche probabiliste explique pourquoi les IA génératives, malgré leurs capacités impressionnantes, ne sont pas optimales pour la recherche d'information.

-
Des réponses aléatoires
L'aspect probabiliste entraîne des réponses aléatoires, qui varient pour des interactions similaires.
Exemple
Dans les deux exemples ci-dessous, il a été demandé la même question à ChatGPT : "Est-ce que François Bayrou a déjà été premier ministre ?".
Dans le premier cas, la réponse donnée est que François Bayrou a été premier ministre sous la présidence de Jacques Chirac.
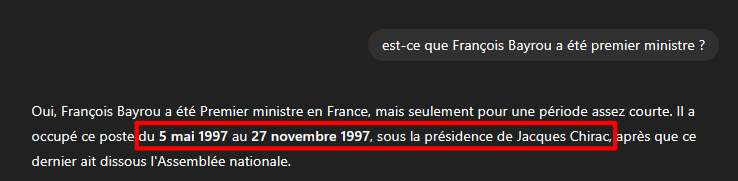
Dans le second cas, la réponse donnée est que François Bayrou a été premier ministre sous la présidence de Nicolas Sarkozy.
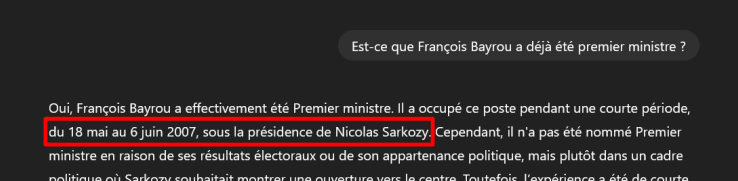
Bien que les deux réponses soient fausses, on constate qu'elles varient pour la même question, illustrant l'impact de l'aspect probabiliste du fonctionnement du LLM.
-
Des données datées
Les données sur lesquelles les LLM se sont entraînées s'arrêtent à une certaine date. Par exemple, pour GPT-5, sorti à l'été 2025, ses données d'entraînement s'arrêtent fin septembre 2024.
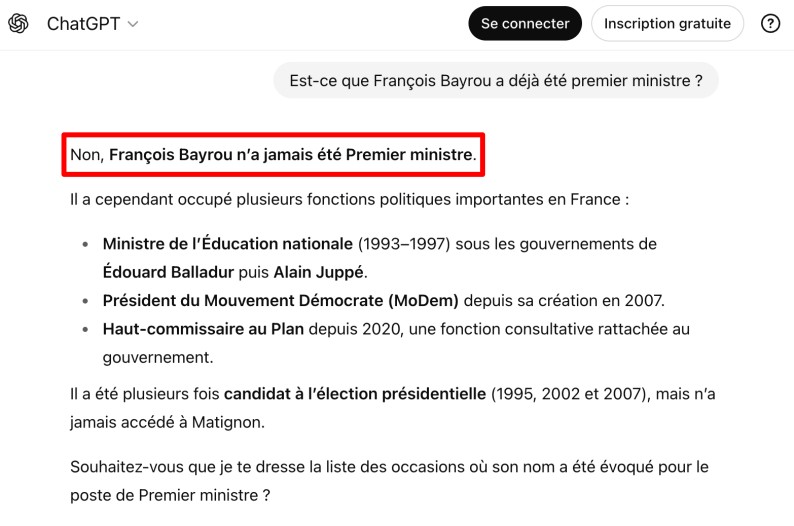
Exemple
Dans la capture d'écran ci-dessous, nous avons demandé à ChatGPT si François Bayrou a déjà été premier ministre. Sa réponse est "Non, François Bayrou n’a jamais été Premier ministre." alors qu'il a bien été, du 13 décembre 2024 au 9 septembre 2025.
-
Des hallucinations
Les LLM sont conçus pour générer du texte fluide et cohérent, pas pour garantir la véracité des informations. Comme déclaré sous sa zone de saisie, "ChatGPT peut commettre des erreurs. Il est recommandé de vérifier les informations importantes." Et en effet, il arrive aux LLM de générer des réponses fausses, tout en les présentant comme des affirmations certaines.
Exemple
Dans la capture d'écran ci-dessous, il a été demandé à ChatGPT la question suivante : "Dans sa dernière aventure, Harry Potter fait-il équipe avec un brocoli ou un carotte ?". La question semble absurde, pour peu que l'on connaisse Harry Potter, mais le chatbot ne reconnaît pas cette absurdité. Au lieu de répondre qu'il n'existe pas de tel personnage dans l'univers de Harry Potter, l'IA génère une réponse détaillée et cohérente sur un personnage végétal imaginaire nommé "Brocilus".

Lobepaq, CC BY-SA 4.0, via Wikimedia Commons
Comme nous l'avons vu, une des raisons des hallucinations est que le modèle fonctionne par prédiction statistique. Face à cette question, il génère le texte le plus probable en combinant ses connaissances sur Harry Potter avec la contrainte imposée (un légume). Il privilégie la cohérence narrative sur la véracité factuelle.
-
Des biais intégrés
Au-delà des hallucinations, les LLM peuvent également véhiculer des biais présents dans leurs données d'entraînement :
- biais de genre, par exemple : associer certaines professions à un sexe plutôt qu'un autre,
- biais culturels, par exemple : sur-représenter certaines perspectives géographiques,
- biais linguistiques, par exemple : privilégier les contenus anglophones.
Pour illustrer ces biais, observons les résultats obtenus avec la même requête posée à trois IA différentes : "Je cherche les 10 romans de science-fiction les plus importants ces 30 dernières années".
Exemple
Je cherche les 10 romans de science-fiction les plus importants ces 30 dernières années (au 22/08/2025)

ChatGPT
- Le Problème à trois corps - Liu Cixin (2008)
- La Route (The Road) - Cormac McCarthy (2006)
- Altered Carbon - Richard K. Morgan (2002)
- Cloud Atlas - David Mitchell (2004)
- Blindsight - Peter Watts (2006)
- The Left Hand of Darkness - Ursula K. Le Guin (1969)
- The Windup Girl - Paolo Bacigalupi (2009)
- Autonomous - Annalee Newitz (2017)
- The Water Knife - Paolo Bacigalupi (2015)
- Semiosis - Sue Burke (2018)

Le Chat
- Spin – Robert Charles Wilson (2005)
- Children of Time – Adrian Tchaikovsky (2015)
- La Horde du Contrevent – Alain Damasio (2004)
- Le Problème à trois corps – Liu Cixin (2008)
- Les Furtifs – Alain Damasio (2019)
- La Mer de la Tranquillité – Emily St. John Mandel (2022)
- Latium – Romain Lucazeau (2019)
- Semiosis – Sue Burke (2018)
- Carbone modifié – Richard K. Morgan (2002)
- Le Château des millions d’années – Alastair Reynolds (2018)

Gemini
- La Trilogie martienne de Kim Stanley Robinson (1992-1996)
- L'Âge de diamant de Neal Stephenson (1995)
- La Cité des permutants de Greg Egan (1994)
- La Zone du Dehors d'Alain Damasio (1999)
- Le Cycle des Inhibiteurs d'Alastair Reynolds (2000)
- Carbone modifié de Richard Morgan (2002)
- Le Problème à trois corps de Liu Cixin (2008)
- Silo de Hugh Howey (2011)
- The Expanse de James S.A. Corey (2011)
- La Terre fracturée de N. K. Jemisin (2015)
Cet exemple révèle plusieurs problèmes. D'abord, on remarque qu'il y a beaucoup d'œuvres anglo-saxonnes, avec une absence de traduction pour certains titres pourtant publiés en français. Ensuite, on constate que chaque IA propose une liste différente pour la même question, sans qu'il soit possible d'expliquer ces divergences. Enfin, les LLM peuvent adapter leurs réponses selon le profil supposé de l'utilisateur, créant ainsi des bulles de filtre sans que celui-ci en ait conscience.
-
Des données d'entraînement issues de contenus grand public
Un autre biais particulièrement important pour la recherche documentaire concerne la nature même des données d'entraînement. Les LLM généralistes sont entraînés majoritairement sur des contenus "grand public" : articles de presse, forums, blogs, réseaux sociaux, Wikipédia...
Les publications scientifiques, rapports techniques spécialisés ou bases de données académiques représentent une part minime de leur apprentissage. Au final, ces IA peuvent être très approximatives ou erronées sur des sujets académiques ou techniques pointus.

-
Du moteur de recherche au moteur de réponse
Avec les progrès des IA, du web sémantique, de la compréhension du langage, et suite au développement des smartphones, les moteurs de recherche classiques se transforment en moteurs de réponse. Plutôt que de simplement fournir une liste de liens, ces outils cherchent désormais à donner directement l'information recherchée, sans que l'utilisateur ait besoin de naviguer sur d'autres sites.
Cette évolution s'accompagne du développement de la recherche conversationnelle et de la personnalisation des résultats basée sur l'historique de l'utilisateur. Les moteurs sont à la recherche du "zéro clic".
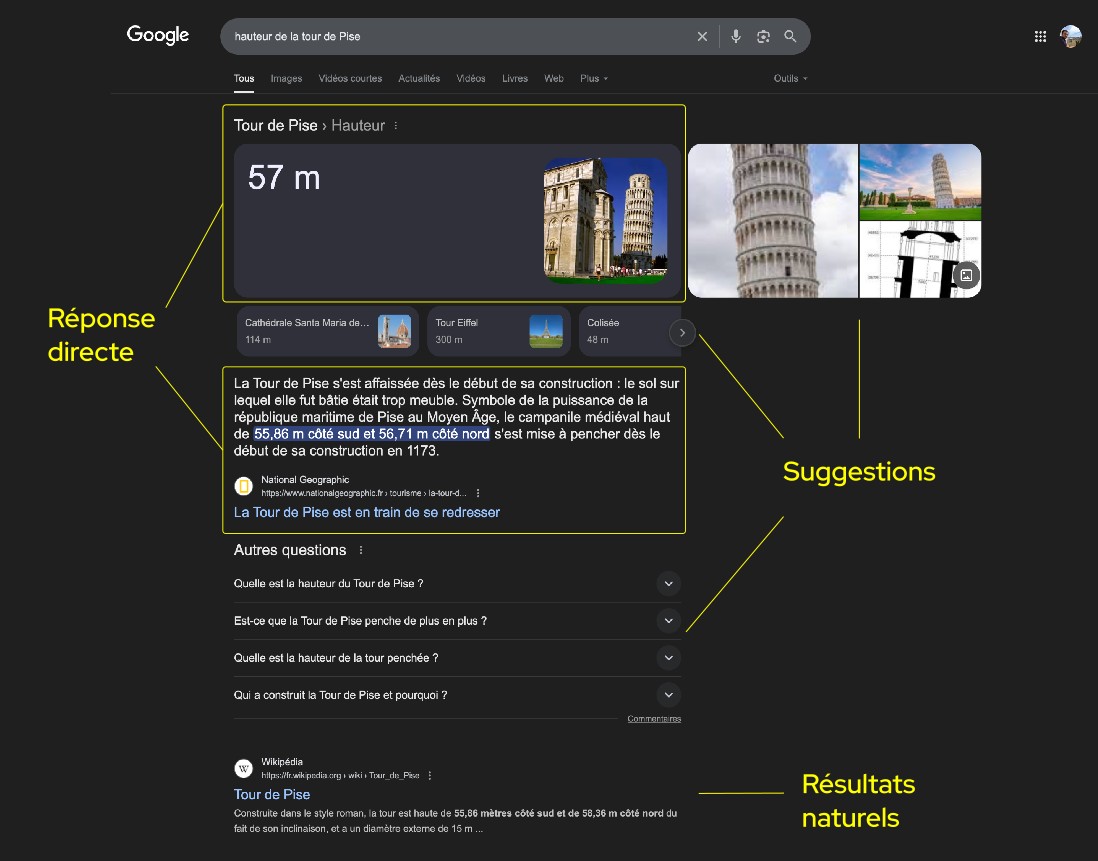
Page de résultat Google suite à la recherche "hauteur tour de Pise", montrant la réponse directe, les suggestions automatiques et la liste des résultats naturels.
-
Un écosystème en mutation
L'arrivée des IA génératives a accéléré cette transformation, particulièrement depuis le printemps 2023. Les principaux moteurs de recherche ont annoncé ou déjà mis en place le développement d'agents conversationnels à l'image de Microsoft Bing (s'appuyant sur GPT), Qwant, Brave, ou encore Google AI Overview.
Capture d'écran du moteur de recherche Brave intégrant une IA (Leo AI).
En parallèle, les chatbots comme ChatGPT, Le Chat ou Claude proposent désormais d'effectuer des recherches sur le web présentant les sources, ce qui permet de vérifier les réponses données.
Capture d'écran de ChatGPT intégrant la recherche d'information sur le web.
-
Les chatbots proposent maintenant des fonctions de recherche. Comment ça fonctionne ? Et surtout, est-ce que ça fonctionne ?
40 minutes de lecture
-
La recherche simple
Nous l'avons vu, les robots conversationnels peuvent faire des recherches sur le web. Il s'agit d'une fonctionnalité optionnelle ou ponctuelle : l'IA peut chercher sur le web quand on lui demande ou quand elle détecte qu'elle a besoin d'informations actuelles.
D'un point de vue technique, le processus reste assez basique et ne prend que quelques secondes :
- Le LLM transforme le prompt en mots-clés optimisés pour la recherche ;
- Il fait sa requête sur un index de moteur de recherche ;
- Il accède aux sites pertinents, puis combine le prompt original avec les informations qu'il vient de récupérer ;
- Il génère une réponse finale sourcée et en langage naturel.

Ce processus est appelé RAG (Retrieval Augmented Generation ou génération augmentée par récupération).
-
La recherche approfondie (deep search)
Contrairement à la recherche simple qui effectue quelques requêtes ciblées en quelques secondes, la recherche approfondie (ou deep search) utilise le RAG de manière intensive et itérative.
Concrètement, lorsqu'on lance une recherche approfondie, l'IA ne se contente pas d'une seule série de recherches. Elle suit un plan de recherche structuré et effectue de multiples cycles successifs de manière autonome : elle recherche des informations, analyse les résultats, identifie les manques ou contradictions, puis relance de nouvelles recherches plus ciblées. Ce processus peut impliquer 10 à 50 recherches ou plus, avec lecture complète de sources, croisement d'informations et vérification des données.
 Temps total du processus RAG en deep search : plusieurs minutes
Temps total du processus RAG en deep search : plusieurs minutesLe résultat n'est plus une simple réponse conversationnelle, mais un rapport détaillé comprenant une synthèse argumentée, une analyse comparative des sources, et une bibliographie complète. Cette approche méthodique prend généralement 5 à 15 minutes, mais offre une profondeur d'analyse comparable à la démarche itérative de la recherche documentaire.
Pour exemple, vous trouverez ci-dessous un rapport généré après une recherche approfondie sur ChatGPT (voir la conversation).
-
Exemple de rapport détaillé généré en 9 minutes par la fonction deep search de ChatGPT 5.
37.5 Ko
-
-
Tout au long de ce cours, nous avons exploré l'impact des IA génératives sur la recherche documentaire. Nous avons vu qu'elles transforment nos pratiques d'information en proposant des approches conversationnelles et des synthèses rapides, mais qu'elles présentent aussi des limites importantes : hallucinations, biais, manque de reproductibilité et sources parfois peu fiables.
Les fonctions de recherche basées sur le RAG (simple ou approfondie) permettent de pallier certaines de ces limites en s'appuyant sur des bases de connaissances externes actualisées. Toutefois, elles ne remplacent pas une démarche de recherche rigoureuse et critique, essentielle dans un contexte académique ou professionnel.
Dans tous les cas, gardez en tête ces quatre principes :
- comparez différentes requêtes ;
- comparez les outils entre eux ;
- vérifiez systématiquement les réponses des outils (présence de sources, contenus générés) ;
- tenez vous au courant des évolutions des outils que vous utilisez.
-
Et demain ? L'IA agentique ?
La prochaine évolution se dessine déjà : l'IA agentique.
Contrairement à l’IA générative, qui crée des réponses sur demande, l’IA agentique a la faculté de fonctionner de manière autonome et de prendre des décisions en fonction d’un ensemble d’objectifs prédéfinis par l’utilisateur ou l’utilisatrice. Il peut donc interagir avec plusieurs systèmes, bases de données et autres modèles d’IA.
Les IA agentiques capables d'enchaîner des tâches complexes dans différents environnements sont pour l'instant plutôt utilisées dans le monde de l'entreprise ou dans le cadre de la sphère privée, par exemple :
- réserver un billet d'avion, un hôtel et un restaurant pour un voyage ;
- planifier un rendez-vous en consultant votre agenda et en envoyant les invitations ;
- gérer vos courses en ligne en fonction de votre budget et de vos préférences alimentaires...
Néanmoins, en l'état actuel de la technique, il convient de rester très prudent sur les résultats fournis par ces outils. En cumulant différents types d'IA à différents moments du processus, l'IA agentique tend en effet à renforcer les erreurs et le manque de contrôle humain.
Toutefois, des plateformes comme SciSpace illustrent le potentiel de l'IA agentique en recherche documentaire : recherche de publications scientifiques, extraction de données, génération de synthèses, création de visualisations... le tout de manière automatisée et intégrée.
Si ce sujet vous intéresse, restez attentifs : un prochain cours dédié aux outils spécialisés en recherche documentaire explorera plus en détail comment ces technologies peuvent être mises au service d'une recherche académique.
-
-
Ce forum est à votre disposition pour tout échange sur le cours. Vos retours sont aussi les bienvenus.
-