
Ouvrir les données de recherche en informatique théorique : qu'a-t-on à y gagner ?
Résumé de section
-
Nous vous présentons ici les raisons pour lesquelles il convient d'ouvrir les données de recherche, c'est-à-dire de les rendre accessibles publiquement, afin notamment de permettre la reproductibilité des expériences.
À l'aide d'exemples concrets, nous donnerons un certain nombre de raisons (éthiques, pratiques, légales…) d'effectuer la mise à disposition dans des entrepôts de données accessibles à long terme. Nous donnerons également quelques pistes afin de mettre à disposition les données de recherche en accès libre.
La présentation est avant tout destinée aux universitaires en informatique théorique mais, du fait des similitudes dans ces différents domaines, les personnes effectuant leur recherche en informatique en général ou même en mathématiques, devraient y trouver bon nombre d'informations utiles.
Objectif
- Définir les données de la recherche en informatique théorique
- Comprendre
les inconvénients de ne pas ouvrir des données de recherche à partir
des mauvaises pratiques issues de retours d'expérience
- Connaître les intérêts de rendre public des données de recherche à titre personnel, pour sa communauté scientifique et pour le grand public
- Proposer des moyens d'ouvrir des données de recherche facilement

Ce cours est en libre accès !
Aucune création de compte ou d'inscription n'est nécessaire, toutefois vous ne pourrez le parcourir qu'en lecture seule.
Pour participer aux activités (exercices, forum...), vous devez vous inscrire au cours
S'inscrire au cours -
-
2.1 Les jeux de données en informatique théorique
Exemples
Les données en informatique théorique peuvent prendre plusieurs formes telles que :
Des programmes rédigés dans un langage informatique
for i in range(1, 2046):
j += i
print('Hello ' + j)Des graphes ou des automates
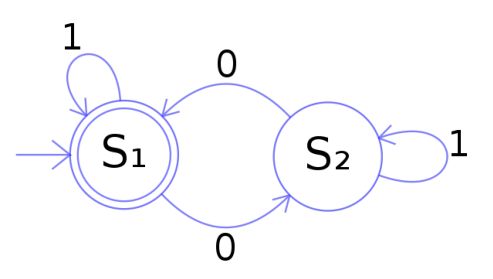
s1 -(1)-> s1
s1 -(0)-> s2
s2 -(0)-> s1
s2 -(1)-> s2Des données numériques (logs, suites de nombres…)
@t=2.3: temperature=2.3; vitesse=4.5
@t=2.7: temperature=3.2; vitesse=6.9
@t=4.9: temperature=5.1; vitesse=20.46Des modèles formels exprimés dans un langage formel
VARIABLE clock
Init == clock \in {0, 1}
Tick == IF clock = 0 THEN clock' = 1 ELSE clock' = 0
Spec == Init /\ [][Tick]_<<clock>>
(ci-dessus : extrait de code TLA+)
SpécificitésEn informatique théorique les jeux de données ne ressemblent pas à n'importe quel autre jeu de données. Ils ont pour particularités d'être :
1. Généralement du texte
- Code
- Modèles formels codés dans des formats textuels (XML, JSON, CSV...)
- Suites de nombres
- À la différence de : données d’imageries (médecine, géographie...)
2. Taille relativement modeste
- Taille typique d’un programme ou d’un modèle : quelques dizaines ou centaines de Kio
- Un programme même de grande taille excède très rarement 100 Mio
- À la différence de : banques d’images (médecine, géographie, apprentissage artificiel...), relevés météorologiques, etc.
- Par exemple, 1 répondant(e) sur 5 mentionne dans une enquête française de 2020 des données de plus de 1To
3. Rarement de questions de confidentialité ou d’éthique
- À la différence de : médecine, sociologie...
- (Contre-exemple : collaborations industrielles avec accord de confidentialité...)
-
-
Que partager ?
Si la taille le permet : tout
- logiciel (code + binaire)
- données brutes (modèles...)
- résultats
Ne pas oublier :
- Documentation : système, bibliothèques nécessaires, etc.
- Versions
- Description formelle ou (au moins) informelle des formats
Penser à partager les résultats négatifs
- Décret n°2021-1572 du 3 décembre 2021 : incite « à la publication des résultats de recherche dits négatifs »
- Évite à d’autres collègues de réessayer une « mauvaise » solution

-
Où partager ?
Données et code permettant la reproductibilité :
Entrepôt national Recherche Data Gouv ⇒ Propose également des ateliers de la donnée dans toute la France.
Obtention systématique d’un DOI, qui peut ensuite être cité
Versions du code :
- système git (par exemple GitLab)
- Software Heritage
-
-
Autres suugestions